Hinweis zum Ende des Supports: Am 31. Mai 2026 AWS endet der Support für AWS Panorama. Nach dem 31. Mai 2026 können Sie nicht mehr auf die AWS Panorama Konsole oder AWS Panorama die Ressourcen zugreifen. Weitere Informationen finden Sie unter AWS Panorama Ende des Supports.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Computer-Vision-Modelle
Ein Computer-Vision-Modell ist ein Softwareprogramm, das darauf trainiert ist, Objekte in Bildern zu erkennen. Ein Modell lernt, eine Reihe von Objekten zu erkennen, indem es zunächst Bilder dieser Objekte durch Training analysiert. Ein Computer-Vision-Modell verwendet ein Bild als Eingabe und gibt Informationen über die Objekte aus, die es erkennt, z. B. den Objekttyp und seinen Standort. AWS Panorama unterstützt Computer Vision-Modelle PyTorch, die mit Apache MXNet und erstellt wurden TensorFlow.
Anmerkung
Eine Liste der vorgefertigten Modelle, die mit AWS Panorama getestet wurden, finden Sie unter Modellkompatibilität
Sections
Modelle im Code verwenden
Ein Modell gibt ein oder mehrere Ergebnisse zurück, die Wahrscheinlichkeiten für erkannte Klassen, Ortsinformationen und andere Daten beinhalten können. Das folgende Beispiel zeigt, wie Inferenzen für ein Bild aus einem Videostream ausgeführt und die Ausgabe des Modells an eine Verarbeitungsfunktion gesendet werden.
Beispiel application.py — Inferenz
def process_media(self, stream): """Runs inference on a frame of video.""" image_data = preprocess(stream.image,self.MODEL_DIM) logger.debug('Image data: {}'.format(image_data)) # Run inference inference_start = time.time()inference_results = self.call({"data":image_data}, self.MODEL_NODE)# Log metrics inference_time = (time.time() - inference_start) * 1000 if inference_time > self.inference_time_max: self.inference_time_max = inference_time self.inference_time_ms += inference_time # Process results (classification)self.process_results(inference_results, stream)
Das folgende Beispiel zeigt eine Funktion, die Ergebnisse eines grundlegenden Klassifikationsmodells verarbeitet. Das Beispielmodell gibt eine Reihe von Wahrscheinlichkeiten zurück. Dabei handelt es sich um den ersten und einzigen Wert in der Ergebnismatrix.
Beispiel application.py
def process_results(self, inference_results, stream): """Processes output tensors from a computer vision model and annotates a video frame.""" if inference_results is None: logger.warning("Inference results are None.") return max_results = 5 logger.debug('Inference results: {}'.format(inference_results)) class_tuple = inference_results[0] enum_vals = [(i, val) for i, val in enumerate(class_tuple[0])] sorted_vals = sorted(enum_vals, key=lambda tup: tup[1]) top_k = sorted_vals[::-1][:max_results] indexes = [tup[0] for tup in top_k] for j in range(max_results): label = 'Class [%s], with probability %.3f.'% (self.classes[indexes[j]], class_tuple[0][indexes[j]]) stream.add_label(label, 0.1, 0.1 + 0.1*j)
Der Anwendungscode findet die Werte mit den höchsten Wahrscheinlichkeiten und ordnet sie den Bezeichnungen in einer Ressourcendatei zu, die während der Initialisierung geladen wird.
Ein benutzerdefiniertes Modell erstellen
Sie können Modelle verwenden, die Sie in Apache PyTorch MXNet - und TensorFlow AWS-Panorama-Anwendungen erstellen. Als Alternative zum Erstellen und Trainieren von Modellen in SageMaker KI können Sie ein trainiertes Modell verwenden oder Ihr eigenes Modell mit einem unterstützten Framework erstellen und trainieren und es in eine lokale Umgebung oder in Amazon exportieren EC2.
Anmerkung
Einzelheiten zu den von SageMaker AI Neo unterstützten Framework-Versionen und Dateiformaten finden Sie unter Unterstützte Frameworks im Amazon SageMaker AI Developer Guide.
Das Repository für dieses Handbuch enthält eine Beispielanwendung, die diesen Workflow für ein Keras-Modell im TensorFlow SavedModel Format demonstriert. Es verwendet TensorFlow 2 und kann lokal in einer virtuellen Umgebung oder in einem Docker-Container ausgeführt werden. Die Beispiel-App enthält auch Vorlagen und Skripte für die Erstellung des Modells auf einer EC2 Amazon-Instance.
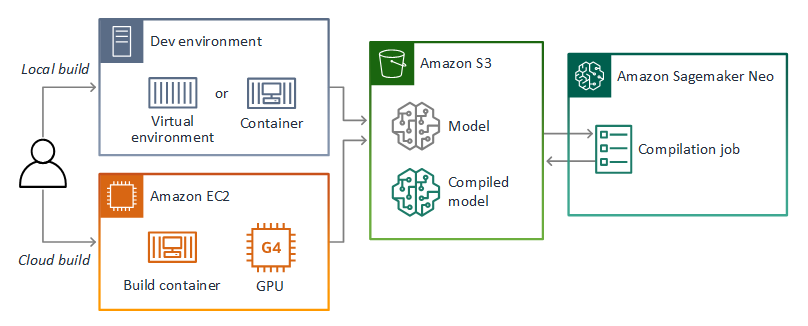
AWS Panorama verwendet SageMaker AI Neo, um Modelle für die Verwendung auf der AWS Panorama Appliance zu kompilieren. Verwenden Sie für jedes Framework das Format, das von SageMaker AI Neo unterstützt wird, und verpacken Sie das Modell in einem .tar.gz Archiv.
Weitere Informationen finden Sie unter Modelle mit Neo kompilieren und bereitstellen im Amazon SageMaker AI Developer Guide.
Ein Modell verpacken
Ein Modellpaket besteht aus einem Deskriptor, einer Paketkonfiguration und einem Modellarchiv. Wie in einem Anwendungs-Image-Paket teilt die Paketkonfiguration dem AWS Panorama Panorama-Service mit, wo das Modell und der Deskriptor in Amazon S3 gespeichert sind.
Beispiel packages/123456789012-squeezenet_pytorch-1.0/descriptor.json
{ "mlModelDescriptor": { "envelopeVersion": "2021-01-01", "framework": "PYTORCH", "frameworkVersion": "1.8", "precisionMode": "FP16", "inputs": [ { "name": "data", "shape": [ 1, 3, 224, 224 ] } ] } }
Anmerkung
Geben Sie nur die Haupt- und Nebenversion der Framework-Version an. Eine Liste der unterstützten Versionen PyTorch MXNet, Apache- und TensorFlow Versionsversionen finden Sie unter Unterstützte Frameworks.
Verwenden Sie den import-raw-model CLI-Befehl AWS Panorama Application, um ein Modell zu importieren. Wenn Sie Änderungen am Modell oder seinem Deskriptor vornehmen, müssen Sie diesen Befehl erneut ausführen, um die Ressourcen der Anwendung zu aktualisieren. Weitere Informationen finden Sie unter Änderung des Computer-Vision-Modells.
Das JSON-Schema der Deskriptordatei finden Sie unter AssetDescriptor.schema.json.
Modelltraining
Wenn Sie ein Modell trainieren, verwenden Sie Bilder aus der Zielumgebung oder aus einer Testumgebung, die der Zielumgebung sehr ähnlich ist. Berücksichtigen Sie die folgenden Faktoren, die sich auf die Modellleistung auswirken können:
-
Beleuchtung — Die Lichtmenge, die von einem Objekt reflektiert wird, bestimmt, wie viele Details das Modell analysieren muss. Ein Modell, das mit Bildern gut beleuchteter Objekte trainiert wurde, funktioniert in Umgebungen mit wenig Licht oder Gegenlicht möglicherweise nicht gut.
-
Auflösung — Die Eingabegröße eines Modells ist in der Regel auf eine Auflösung zwischen 224 und 512 Pixeln in einem quadratischen Seitenverhältnis festgelegt. Bevor Sie ein Videobild an das Modell übergeben, können Sie es verkleinern oder zuschneiden, bis es der gewünschten Größe entspricht.
-
Bildverzerrung — Die Brennweite und die Linsenform einer Kamera können dazu führen, dass Bilder außerhalb der Bildmitte verzerrt werden. Die Position einer Kamera bestimmt auch, welche Merkmale eines Motivs sichtbar sind. Beispielsweise zeigt eine Overhead-Kamera mit Weitwinkelobjektiv die Oberseite eines Motivs, wenn es sich in der Bildmitte befindet, und eine schiefe Ansicht der Seite des Motivs, wenn es sich weiter von der Bildmitte entfernt.
Um diese Probleme zu lösen, können Sie Bilder vorverarbeiten, bevor Sie sie an das Modell senden, und das Modell anhand einer größeren Vielfalt von Bildern trainieren, die Abweichungen in realen Umgebungen widerspiegeln. Wenn ein Modell in Lichtsituationen und mit einer Vielzahl von Kameras betrieben werden muss, benötigen Sie mehr Daten für das Training. Sie können nicht nur mehr Bilder erfassen, sondern auch mehr Trainingsdaten gewinnen, indem Sie Variationen Ihrer vorhandenen Bilder erstellen, die schief sind oder unterschiedliche Lichtverhältnisse aufweisen.
