Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden Sie Reinforcement Learning mit Amazon SageMaker AI
Reinforcement Learning (RL) kombiniert Bereiche wie Informatik, Neurowissenschaften und Psychologie, um zu bestimmen, wie Situationen Aktionen zugeordnet werden können, um ein numerisches Belohnungssignal zu maximieren. Diese Vorstellung von einem Belohnungssignal bei RL stammt aus neurowissenschaftlichen Untersuchungen, die untersuchen, wie das menschliche Gehirn Entscheidungen darüber trifft, welche Aktionen die Belohnung maximieren und die Bestrafung minimieren. In den meisten Situationen erhalten Menschen keine ausdrücklichen Anweisungen, welche Maßnahmen zu ergreifen sind, sondern müssen lernen, welche Aktionen die unmittelbarsten Belohnungen bringen und wie diese Handlungen future Situationen und Konsequenzen beeinflussen.
Das Problem der RL wird mit Hilfe von Markov-Entscheidungsprozessen (MDPs) formalisiert, die ihren Ursprung in der Theorie dynamischer Systeme haben. MDPs zielen darauf ab, allgemeine Details eines realen Problems zu erfassen, auf das ein Lernagent im Laufe eines bestimmten Zeitraums stößt, wenn er versucht, ein bestimmtes Endziel zu erreichen. Der Lernagent sollte in der Lage sein, den aktuellen Zustand seiner Umgebung zu ermitteln und mögliche Maßnahmen zu identifizieren, die sich auf den aktuellen Zustand des Lernagenten auswirken. Darüber hinaus sollten die Ziele des Lernagenten stark mit dem Zustand der Umgebung korrelieren. Eine auf diese Weise formulierte Lösung eines Problems wird als Reinforcement-Learning-Methode bezeichnet.
Was sind die Unterschiede zwischen den Paradigmen des verstärkenden, überwachten und unbeaufsichtigten Lernens?
Machine Learning kann in drei verschiedene Lernparadigmen unterteilt werden: überwachtes, unbeaufsichtigtes und verstärkendes Lernen.
Beim überwachten Leraning bietet ein externer Supervisor eine Reihe von Trainingsbeispielen an. Jedes Beispiel enthält Informationen über eine Situation, gehört zu einer Kategorie und ist mit einem Etikett versehen, das die Kategorie angibt, zu der es gehört. Das Ziel des überwachten Leraning ist die Generalisierung, um Situationen, die in den Trainingsdaten nicht enthalten sind, korrekt vorherzusagen.
Im Gegensatz dazu befasst sich RL mit interaktiven Problemen, sodass es unmöglich ist, alle möglichen Beispiele für Situationen mit korrekten Bezeichnungen zu sammeln, auf die ein Agent stoßen könnte. Diese Art des Lernens ist am vielversprechendsten, wenn ein Agent in der Lage ist, genau aus seiner eigenen Erfahrung zu lernen und sich entsprechend anzupassen.
Beim unbeaufsichtigten Lernen lernt ein Agent, indem er Strukturen in unmarkierten Daten aufdeckt. Ein RL-Agent könnte zwar davon profitieren, Strukturen auf der Grundlage seiner Erfahrungen aufzudecken, aber der einzige Zweck von RL besteht darin, ein Belohnungssignal zu maximieren.
Themen
Warum ist RL wichtig?
RL eignet sich hervorragend für die Lösung großer, komplexer Probleme wie Lieferkettenmanagement, HLK-Systeme, Industrierobotik, künstliche Intelligenz in Spielen, Dialogsysteme und autonome Fahrzeuge. Da RL-Modelle auf Basis eines kontinuierlichen Prozesses lernen, im Rahmen dessen Belohnungen oder Strafen für jede Aktion des Agenten erhalten werden, können Systeme so trainiert werden, dass sie auch bei Unsicherheiten und in dynamischen Umgebungen Entscheidungen treffen.
Markow-Entscheidungsprozess (MEP)
RL basiert auf Modellen, die Markow-Entscheidungsprozesse (MEPs) genannt werden. Ein MEP besteht aus einer Reihe von Zeitschritten. Jeder Zeitschritt besteht aus Folgendem:
- Umgebung
-
Definiert den Raum, in dem das RL-Modell agiert. Dies kann entweder eine reale Umgebung oder einen Simulator sein. Wenn Sie zum Beispiel eine physisches autonomes Fahrzeug auf einer physischen Straße trainieren, wäre das eine reale Umgebung. Wenn Sie ein Computerprogramm trainieren, dass ein auf einer Straße fahrendes autonomes Fahrzeug modelliert, wäre das ein Simulator.
- Status
-
Gibt alle Informationen über die Umgebung und vergangene Schritte an, die für die Zukunft relevant sind. In einem RL-Modell, in dem sich ein Roboter in jedem Zeitschritt in eine beliebige Richtung bewegen kann, ist beispielsweise die Position des Roboters im aktuellen Zeitschritt der Zustand, denn wenn wir wissen, wo sich der Roboter befindet, ist es nicht notwendig, die Schritte zu kennen, die er unternommen hat, um dorthin zu gelangen.
- Action
-
Was der Agent tut. Beispiel: Der Roboter geht einen Schritt nach vorne.
- Belohnung
-
Eine Zahl, die den Wert des Zustands angibt, der aus der letzten Aktion des Agenten resultierte. Beispiel: Wenn das Ziel für einen Roboter darin besteht, einen Schatz zu finden, dann könnte die Belohnung für das Finden des Schatzes 5 und bei Nichtfinden des Schatzes 0 sein. Das RL-Modell versucht, eine Strategie zu finden, die die kumulative Belohnung langfristig optimiert. Diese Strategie wird als Richtlinie bezeichnet.
- Beobachtung
-
Informationen über den Zustand der Umgebung, die dem Agenten in jedem Schritt zur Verfügung stehen. Dies kann der gesamte Zustand oder nur ein Teil des Zustands sein. Beispiel: Der Agent in einem Schachspielmodell kann des gesamten Zustand des Schachbrettes in jedem Schritt beobachten. Ein Roboter in einem Labyrinth hingegen kann nur einen kleinen Teil des Labyrinths beobachten – den Bereich, in dem er sich aktuell befindet.
Das Training besteht im RL in der Regel aus vielen Episoden. Eine Episode umfasst alle Zeitschritte eines MEP, vom ersten Zustand bis die Umgebung den abschließenden Zustand erreicht.
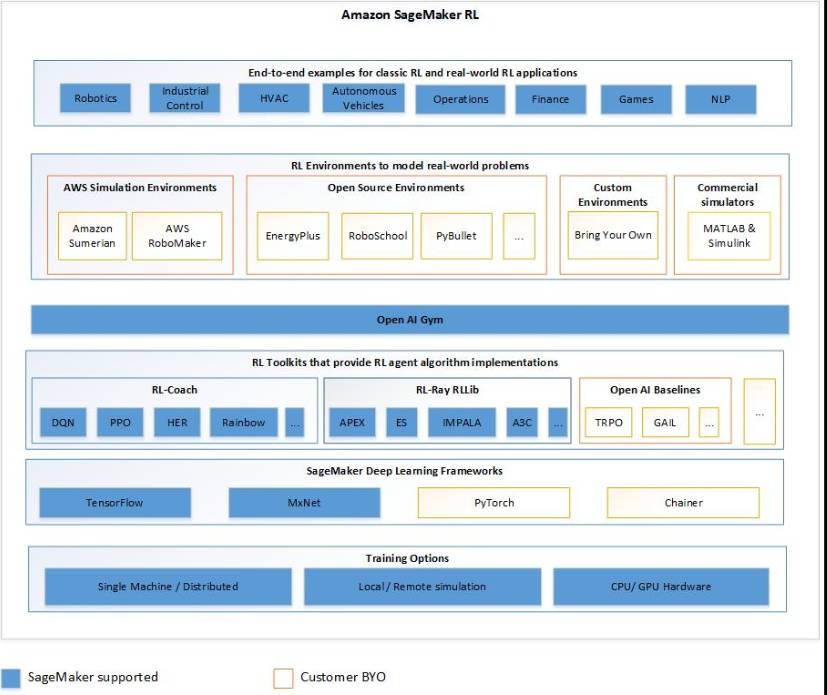
Hauptmerkmale von Amazon SageMaker AI RL
Verwenden Sie die folgenden Komponenten, um RL-Modelle in SageMaker AI RL zu trainieren:
-
Ein Deep-Learning-Framework: Derzeit unterstützt SageMaker AI RL in TensorFlow und Apache MXNet.
-
Ein RL-Toolkit: Ein RL-Toolkit verwaltet die Interaktion zwischen dem Agenten und der Umgebung und bietet eine große Auswahl an modernen RL-Algorithmen. SageMaker AI unterstützt die Toolkits Intel Coach und Ray RLLib. Informationen zu Intel Coach finden Sie unter. https://nervanasystems.github.io/coach/
Informationen zu Ray RLLib finden Sie unter https://ray.readthedocs.io/en/latest/rllib.html . -
Eine RL-Umgebung: Sie können benutzerdefinierte Umgebungen, Open-Source-Umgebungen oder kommerzielle Umgebungen verwenden. Weitere Informationen finden Sie unter RL-Umgebungen in Amazon SageMaker AI.
Das folgende Diagramm zeigt die RL-Komponenten, die in SageMaker AI RL unterstützt werden.
Notebooks zum Reinforcement-Lernen
Vollständige Codebeispiele finden Sie in den Beispielnotizbüchern zum Reinforcement-Learning
