Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
En una perspectiva, puede ver las anomalías de los recursos de Amazon RDS. En una página de información reactiva, en la sección de métricas agregadas, puede ver una lista de anomalías con los plazos correspondientes. También hay secciones que muestran información sobre los grupos de registro y los eventos relacionados con las anomalías. Cada una de las anomalías causales de una visión reactiva tiene una página correspondiente con detalles sobre la anomalía.
Visualización del análisis detallado de una anomalía reactiva de RDS
En esta etapa, profundice en la anomalía para obtener un análisis detallado y recomendaciones para sus instancias de base de datos de Amazon RDS.
El análisis detallado solo está disponible para las instancias de bases de datos de Amazon RDS que tienen Performance Insights activado.
Para acceder a la página de detalles de la anomalía
-
En la página de información, busque una métrica agregada con el tipo de recurso AWS/RDS.
-
Elija Ver detalles.
Se abrirá la página de detalles de la anomalía. El título comienza con Anomalía de rendimiento de la base de datos y nombra el recurso que se muestra. La consola utiliza de forma predeterminada la anomalía de mayor gravedad, independientemente del momento en el que se haya producido la anomalía.
-
(Opcional) Si se ven afectados varios recursos, elija un recurso diferente de la lista de la parte superior de la página.
A continuación, puede encontrar las descripciones de los componentes de la página de detalles.
Información general
La sección superior de la página de detalles es la descripción general de los recursos. En esta sección, se resume la anomalía de rendimiento que experimenta la instancia de base de datos de Amazon RDS.
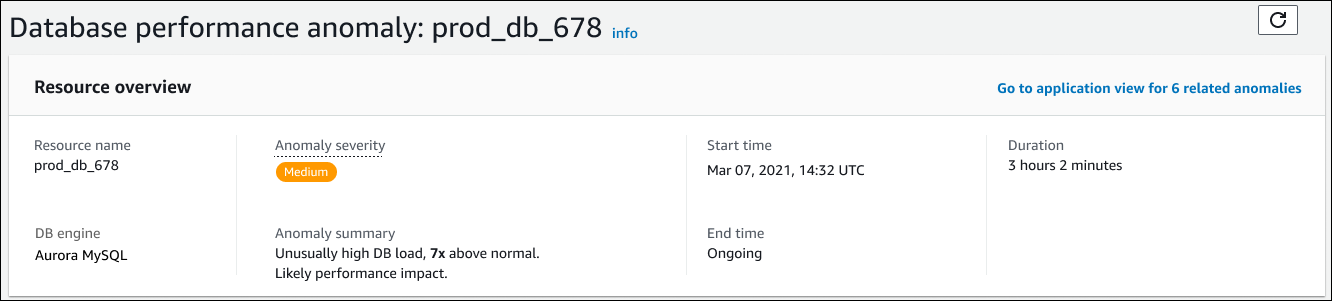
Esta sección incluye los siguientes campos:
-
Nombre de recurso: el nombre de la instancia de base de datos que está experimentando la anomalía. En este ejemplo, el grupo de recursos se llama prod_db_678.
-
Motor de base de datos: nombre de la instancia de base de datos que experimenta la anomalía. En este ejemplo, el motor es Aurora MySQL.
-
Gravedad de la anomalía: la medida del impacto negativo de la anomalía en la instancia. Los niveles de gravedad posibles son alto, medio y bajo.
-
Resumen de la anomalía: un breve resumen del problema. Un resumen típico es una carga de base de datos inusualmente alta.
-
Hora de inicio y hora de finalización: hora a la que comenzó y finalizó la anomalía. Si la hora de finalización es En curso, la anomalía sigue ocurriendo.
-
Duración: la duración del comportamiento anómalo. En este ejemplo, la anomalía continúa y ha estado ocurriendo durante 3 horas y 2 minutos.
Métrica principal
La sección de métricas principales resume la anomalía casual, que es la anomalía de nivel superior del resultado de información. Puede pensar en la anomalía causal como el problema general que experimenta su instancia de base de datos.
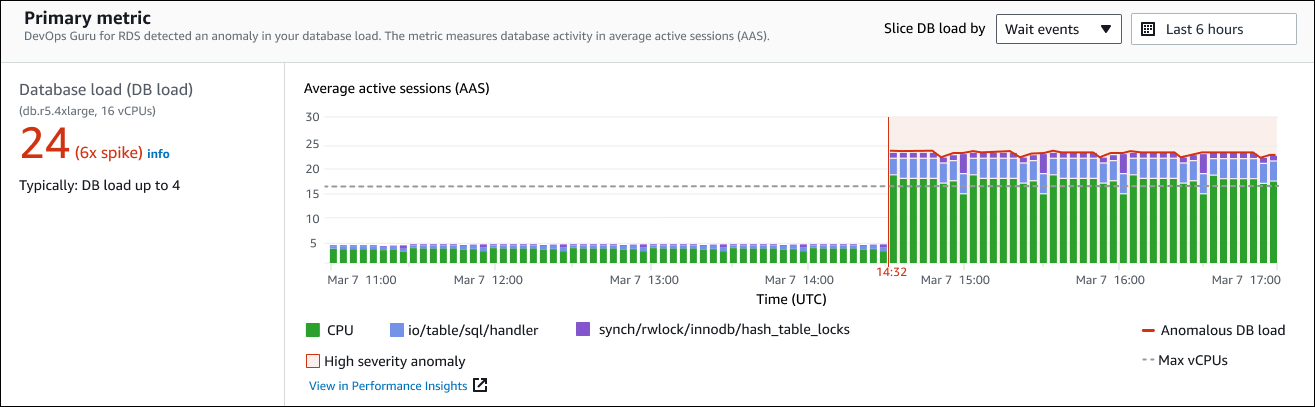
El panel izquierdo proporciona más detalles sobre el problema. En este ejemplo, el resumen de incluye la siguiente información:
-
Carga de la base de datos: categorización de la anomalía como un problema de carga de la base de datos. La métrica correspondiente en Performance Insights es
DBLoad. Esta métrica también se publica en Amazon CloudWatch. -
db.r5.4xlarge: la clase de instancia de base de datos. El número de vCPUs, que en este ejemplo es 16, corresponde a la línea de puntos del gráfico Promedio de sesiones activas (AAS).
-
24 (pico de 6 veces): la carga de la base de datos, medida en el promedio de sesiones activas (AAS) durante el tiempo indicado en el resultado de información. Por tanto, en un momento dado durante el período de la anomalía, había un promedio de 24 sesiones activas en la base de datos. La carga de base de datos es 6 veces mayor que la carga de base de datos normal para esta instancia.
-
Normalmente: carga de base de datos de hasta 4: el valor inicial de carga de base de datos, medida en AAS, durante una carga de trabajo típica. El valor 4 significa que, durante las operaciones normales, hay un promedio de 4 o menos sesiones activas en la base de datos en un momento dado.
De forma predeterminada, el gráfico de carga se divide en función de los eventos de espera. Esto significa que, para cada barra del gráfico, el área coloreada más grande representa el evento de espera que más contribuye a la carga total de la base de datos. El gráfico muestra la hora (en rojo) en que comenzó el problema. Centra su atención en los eventos de espera que ocupan más espacio en la barra:
-
CPU -
IO:wait/io/sql/table/handler
Los eventos de espera anteriores aparecen más de lo normal en esta base de datos Aurora MySQL. Para obtener información acerca de cómo ajustar el rendimiento con eventos de espera en Amazon Aurora, consulte Ajuste con eventos de espera para Aurora MySQL y Ajuste con eventos de espera para Aurora PostgreSQL en la Guía del usuario de Amazon Aurora. Para obtener información sobre cómo ajustar el rendimiento mediante eventos de espera en RDS para PostgreSQL, consulte Cómo ajustar los eventos de espera para RDS para PostgreSQL en la Guía del usuario de Amazon RDS.
Métricas Relacionadas
La sección de Métricas Relacionadas enumera las anomalías contextuales, que son resultados específicos dentro de la anomalía causal. Estos resultados proporcionan información adicional sobre los problemas de rendimiento.
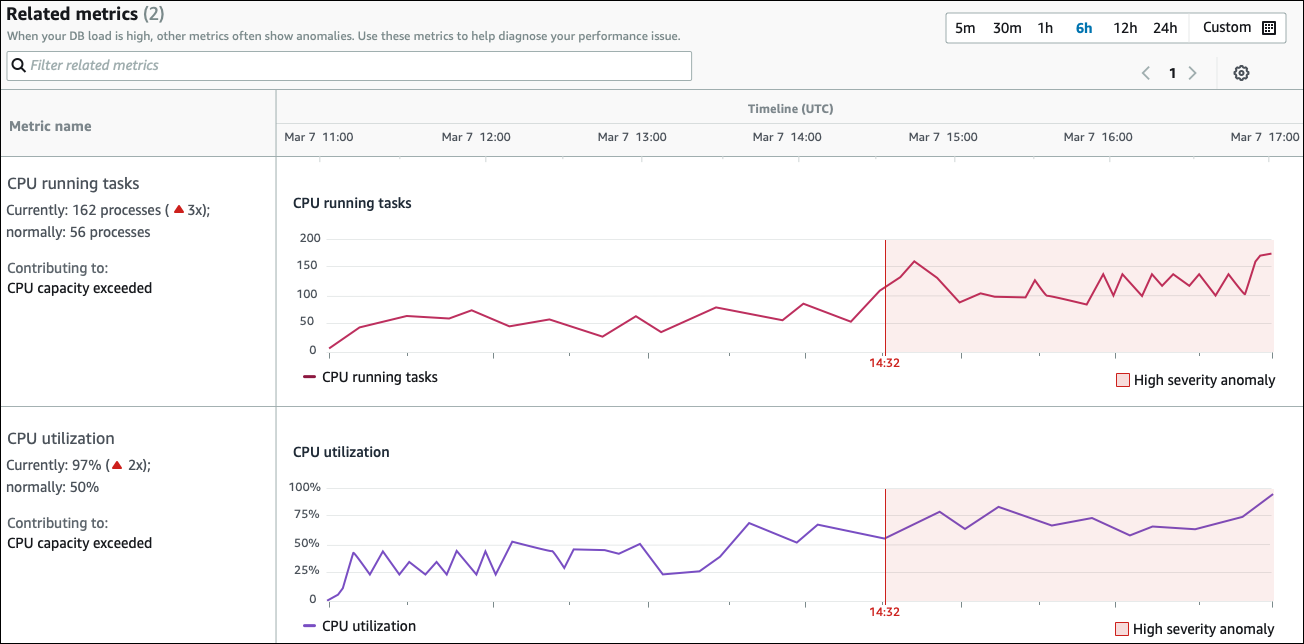
La tabla de Métricas Relacionadas tiene dos columnas: el nombre de las métricas y el Cronograma (UTC). Cada fila de la tabla corresponde a una métrica específica.
La primera columna de cada fila contiene la siguiente información:
-
Name— El nombre de la métrica. La primera fila identifica la métrica como tareas de ejecución de la CPU. -
Actual: el valor actual de la métrica. En la primera fila, el valor actual es de 162 procesos (3x).
-
Normalmente: la línea base de esta métrica para esta base de datos cuando funciona con normalidad. DevOpsGuru para RDS calcula la línea base como el valor del percentil 95 a lo largo de una semana de historia. La primera fila indica que normalmente se ejecutan 56 procesos en la CPU.
-
Contribuir a: el resultado asociado a esta métrica. En la primera fila, la métrica de tareas de ejecución de la CPU está asociada a la anomalía de capacidad de la CPU superada.
La columna Cronograma muestra un gráfico de líneas para la métrica. El área sombreada muestra el intervalo de tiempo en el que DevOps Guru, para RDS, designó el hallazgo como de gravedad alta.
Análisis y recomendaciones
Mientras que la anomalía causal describe el problema general, una anomalía contextual describe un resultado específico que requiere investigación. Cada resultado corresponde a un conjunto de métricas relacionadas.
En el siguiente ejemplo de una sección de Análisis y recomendaciones, la anomalía de carga alta en la base de datos tiene dos resultados.
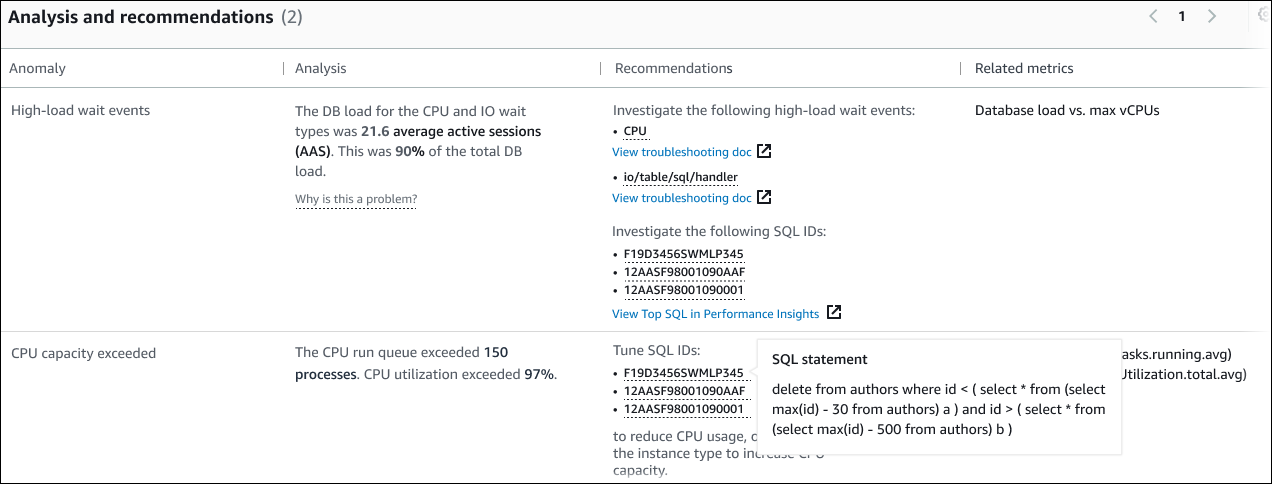
Esta tabla tiene las siguientes columnas:
-
Anomalía: descripción general de esta anomalía contextual. En este ejemplo, la primera anomalía son los eventos de espera de alta carga y la segunda es el exceso de capacidad de la CPU.
-
Análisis: una explicación detallada de la anomalía.
En la primera anomalía, tres tipos de espera representan el 90 % de la carga de la base de datos. En la segunda anomalía, la cola de ejecución de la CPU superaba las 150, lo que significa que, en un momento dado, había más de 150 sesiones esperando la hora de la CPU. El uso de la CPU era superior al 97 %, lo que significa que, mientras duró el problema, la CPU estuvo ocupada el 97 % del tiempo. Por tanto, la CPU estaba ocupada casi continuamente mientras se esperaba una media de 150 sesiones para ejecutarse en la CPU.
-
Recomendaciones: la respuesta sugerida por el usuario a la anomalía.
En la primera anomalía, DevOps Guru for RDS recomienda investigar los eventos de espera y.
cpuio/table/sql/handlerPara obtener información sobre cómo ajustar el rendimiento de la base de datos en función de estos eventos, consulte cpu y io/table/sql/handlerla Guía del usuario de Amazon Aurora.En la segunda anomalía, DevOps Guru for RDS recomienda reducir el consumo de CPU ajustando tres sentencias SQL. Puede pasar el ratón por encima de los enlaces para ver el texto SQL.
-
Métricas Relacionadas: métricas que proporcionan medidas específicas de la anomalía. Para más información sobre estas métricas, consulte la referencia de métricas de Amazon Aurora en la Guía del usuario de Amazon Aurora o la referencia de métricas de Amazon RDS en la Guía del usuario de Amazon RDS.
En la primera anomalía, DevOps Guru for RDS recomienda comparar la carga de base de datos con la CPU máxima de la instancia. En la segunda anomalía, se recomienda tener en cuenta la cola de ejecución de la CPU, el uso de la CPU y la tasa de ejecución de SQL.
