Ayude a mejorar esta página
Para contribuir a esta guía del usuario, elija el enlace Edit this page on GitHub que se encuentra en el panel derecho de cada página.
Información sobre el cambio de zona del Controlador de recuperación de aplicaciones de Amazon (ARC) en Amazon EKS
Kubernetes tiene características nativas que le permiten que sus aplicaciones sean más resistentes a eventos como el deterioro del estado o el deterioro de una zona de disponibilidad (AZ). Cuando ejecuta sus cargas de trabajo en un clúster de Amazon EKS, puede mejorar aún más la tolerancia a errores del entorno y la recuperación de aplicaciones mediante el cambio de zona del Controlador de recuperación de aplicaciones de Amazon (ARC) o el cambio de zona automático. El cambio de zona de ARC está diseñado como una medida temporal que le permite alejar el tráfico de un recurso de una AZ deteriorada hasta que el cambio de zona caduque o se cancele. Si es necesario, puede ampliar el cambio de zona.
Puede iniciar un cambio de zona para un clúster de EKS o permitir que AWS cambie el tráfico mediante la activación del cambio de zona automático. Este cambio actualiza el flujo del tráfico de red de este a oeste en su clúster para tener en cuenta únicamente los puntos de conexión de red de los pods que se ejecutan en nodos de trabajo en AZ en buen estado. Además, cualquier ALB o NLB que administre la entrada del tráfico de las aplicaciones de su clúster de EKS enrutará de forma automática el tráfico a los destinos de las AZ en buen estado. Para aquellos clientes que buscan los objetivos de disponibilidad más altos, en caso de que una AZ se estropee, puede ser importante poder desviar todo el tráfico de la AZ afectada hasta que se recupere. Para esto, también puede activar un ALB o un NLB con el cambio de zona de ARC.
Descripción del flujo de tráfico de red de este a oeste entre pods
El siguiente diagrama ilustra dos ejemplos de cargas de trabajo, Pedidos y Productos. El propósito de este ejemplo es mostrar cómo se comunican las cargas de trabajo y los pods en diferentes AZ.
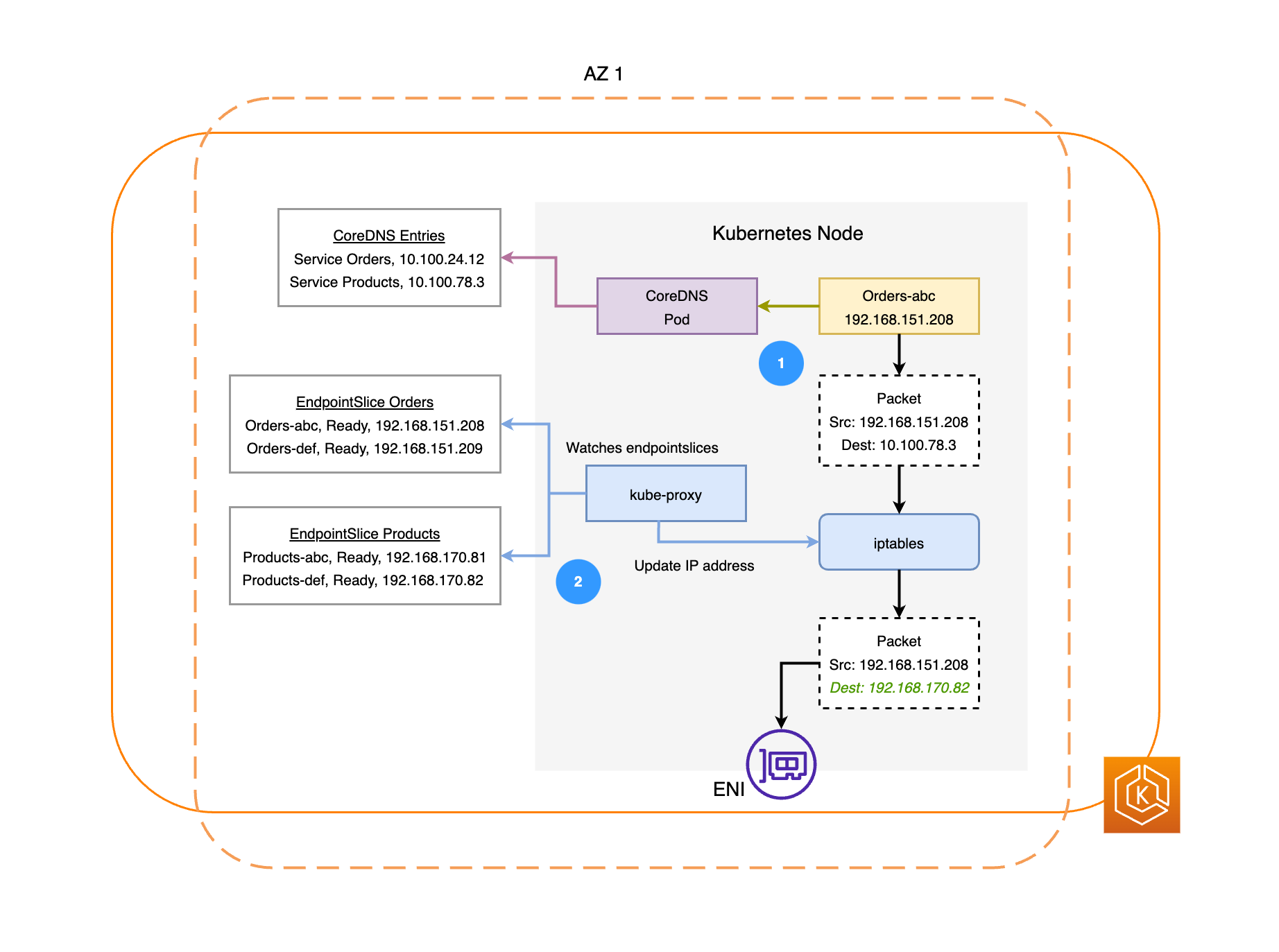
-
Para que Pedidos se comunique con Productos, debe resolver antes el nombre de DNS del servicio de destino. Pedidos se comunica con CoreDNS para obtener la dirección IP virtual (IP del clúster) de ese servicio. Después de que Pedidos resuelva el nombre del servicio de Productos, envía el tráfico a esa dirección IP de destino.
-
El kube-proxy se ejecuta en todos los nodos del clúster y supervisa de manera continua los EndpointSlices
en busca de servicios. Cuando se crea un servicio, el controlador EndpointSlice crea y administra un EndpointSlice en segundo plano. Cada EndpointSlice tiene una lista o tabla de puntos de conexión que contiene un subconjunto de direcciones de pods junto con los nodos en los que se ejecutan. El kube-proxy establece reglas de enrutamiento para cada uno de estos puntos de conexión de los pods mediante el uso de iptablesen los nodos. El kube-proxy también es responsable de una forma básica de equilibrio de carga, ya que redirige el tráfico destinado a la dirección IP del clúster de un servicio para que, en su lugar, se envía directamente a la dirección IP del pod. Para hacerlo, el kube-proxy reescribe la dirección IP de destino en la conexión saliente. -
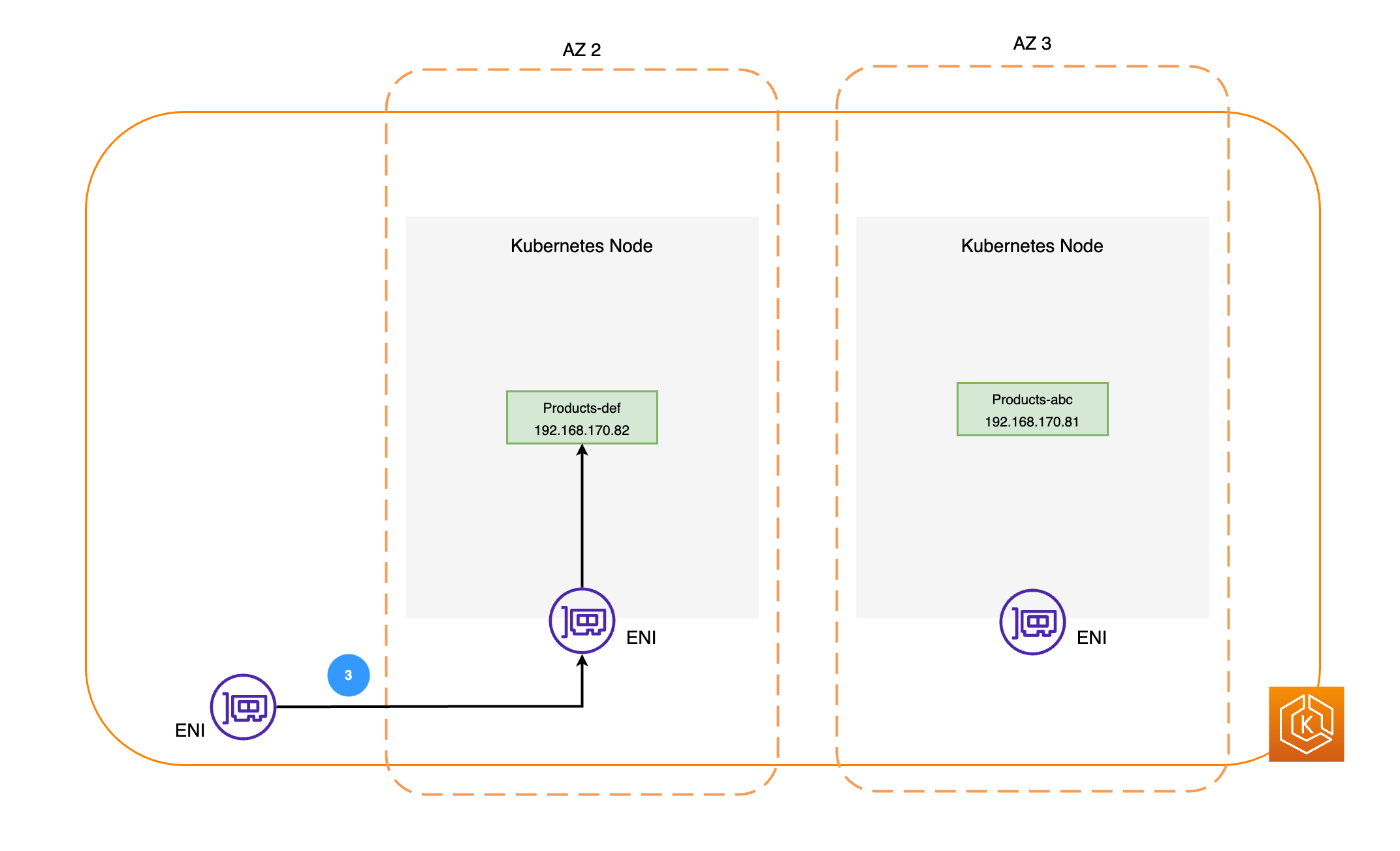
A continuación, los paquetes de red se envían al pod Productos de la AZ 2 mediante los ENI de los nodos respectivos, como se muestra en el diagrama anterior.
Descripción del cambio de zona de ARC en Amazon EKS
Si hay una alteración de la AZ en su entorno, puede iniciar un cambio de zona para su entorno de clústeres de EKS. Como alternativa, puede permitir que AWS administre el cambio de tráfico con el cambio de zona automático. Con el cambio de zona automático, AWS supervisa el estado general de la AZ y responde a una posible alteración de esta mediante el cambio automático del tráfico de la AZ dañada de su entorno de clústeres.
Cuando se haya activado el cambio de zona del clúster de Amazon EKS con ARC, puede iniciar un cambio de zona o activar un cambio de zona automático mediante la consola de ARC, la AWS CLI o las API de cambio de zona automático y cambio de zona. Durante un cambio de zona de EKS, ocurrirá lo siguiente de forma automática:
-
Se acordonan todos los nodos de la AZ afectada. De este modo, se evita que el programador de Kubernetes programe nuevos pods en los nodos de la AZ en mal estado.
-
Si utiliza grupos de nodos administrados, se suspende el reequilibrio de la zona de disponibilidad y se actualiza el grupo de escalado automático para garantizar que los nuevos nodos del plano de datos de Amazon EKS solo se lancen en las zonas de disponibilidad en buen estado.
-
Los nodos de la AZ en mal estado no se terminan y los pods no se expulsan de los nodos. De este modo, se garantizar que, cuando un cambio de zona caduque o se cancele, el tráfico pueda devolverse con seguridad a la AZ para una capacidad plena.
-
El controlador EndpointSlice busca todos los puntos de conexión del pod en la AZ defectuosa y los elimina de los EndpointSlices pertinentes. Esto garantiza que solo los puntos de conexión de pods situados en zonas de disponibilidad en buen estado estén destinados a recibir tráfico de red. Cuando un cambio de zona caduca o se cancela, el controlador EndpointSlice actualiza los EndpointSlices para incluir los puntos de conexión de la AZ restaurada.
Los diagramas siguientes proporcionan información general de alto nivel sobre cómo el cambio de zona de EKS garantiza que solo se usen como objetivo los puntos de conexión de pod en buen estado en el entorno de clústeres.
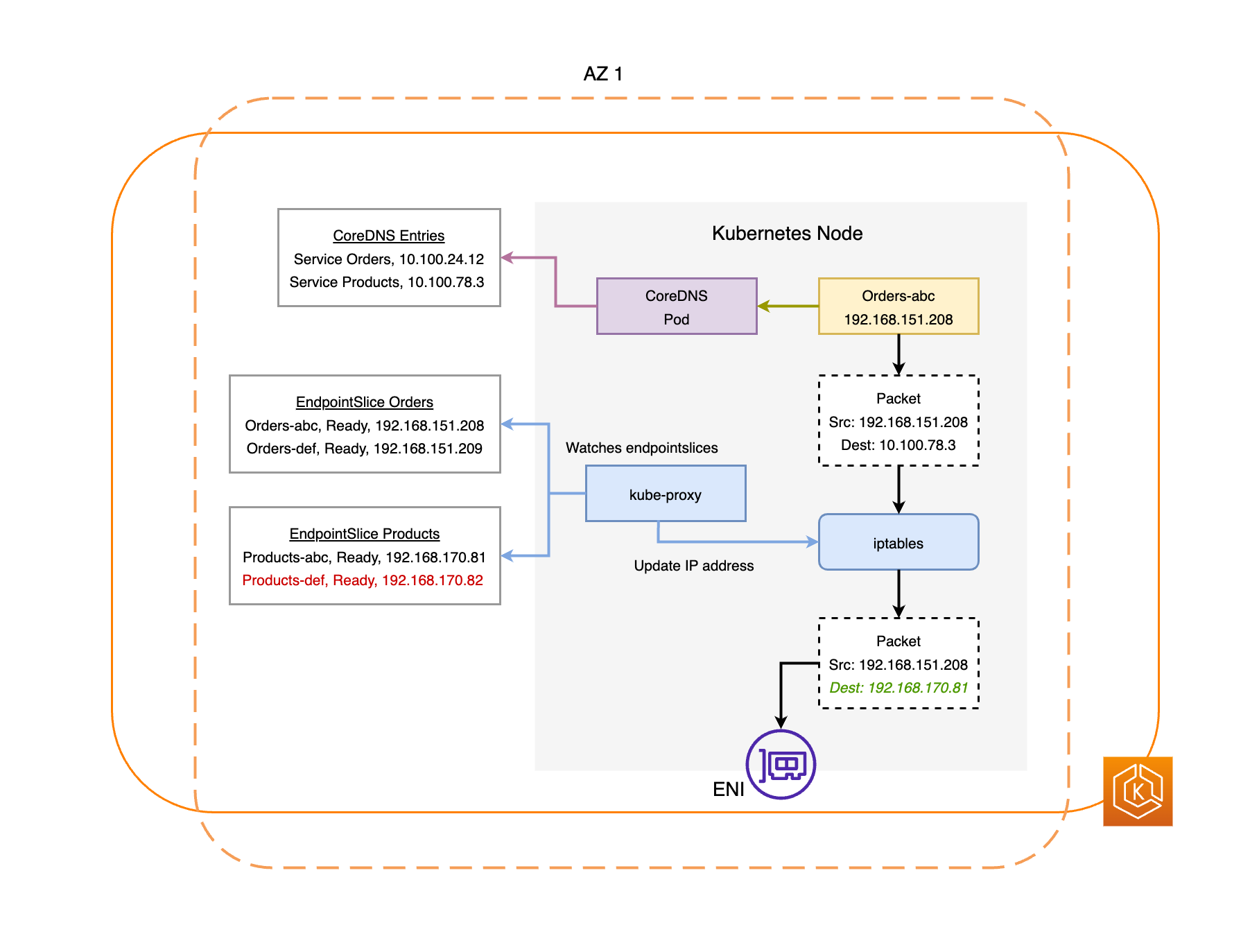
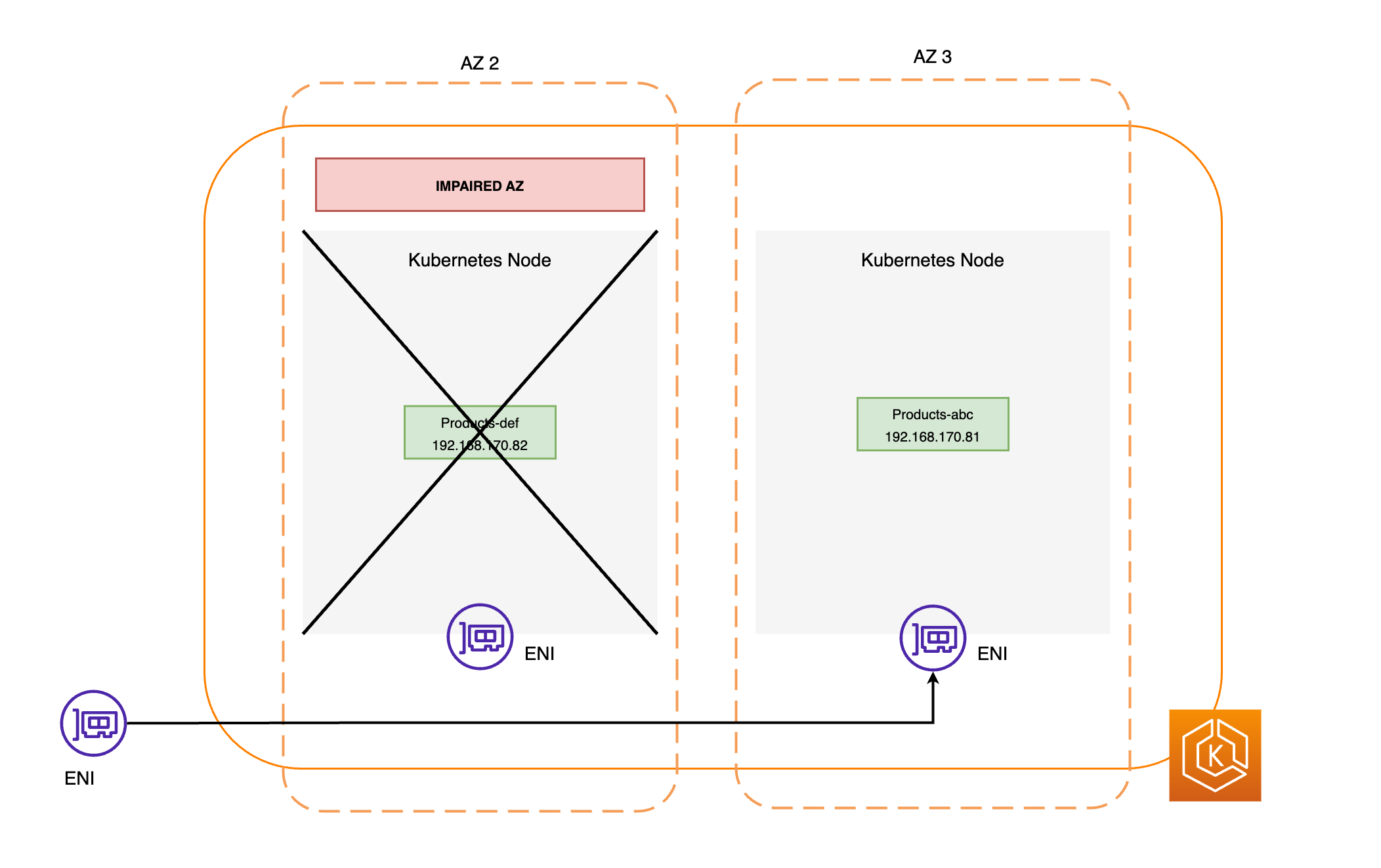
Requisitos del cambio de zona de EKS
Para que el cambio de zona funcione de manera correcta con EKS, debe configurar previamente su entorno de clústeres para que sea resistente a un deterioro de la AZ. A continuación se muestra una lista de opciones de configuración que ayudan a garantizar la resiliencia.
-
Aprovisione los nodos de trabajo de su clúster en varias zonas de disponibilidad.
-
Aprovisione suficiente capacidad de computación para acomodar la eliminación de una sola AZ.
-
Escale previamente sus pods, incluido CoreDNS, en todas las AZ.
-
Distribuya varias réplicas de pods en todas las AZ para asegurarse de que dispondrá de suficiente capacidad si deja de utilizar una sola AZ.
-
Ubique los pods interdependientes o relacionados en la misma AZ.
-
Inicie un cambio de zona de una AZ de forma manual para probar si el entorno de clústeres funciona según lo esperado sin una AZ. Como alternativa, puede activar el cambio de zona automático y depender de las ejecuciones de práctica del cambio automático. Las pruebas con cambios de zona manuales o de práctica no son obligatorias para que el cambio de zona funcione en EKS, pero se recomiendan encarecidamente.
Aprovisionamiento de los nodos de trabajo de EKS en varias zonas de disponibilidad
Las regiones de AWS tienen varias ubicaciones independientes con centros de datos físicos, conocidas como zonas de disponibilidad (AZ). Las AZ están diseñadas para estar aisladas físicamente unas de otras a fin de evitar un impacto simultáneo que podría afectar a toda una región. Al aprovisionar un clúster de EKS, le recomendamos que implemente los nodos de trabajo en varias AZ de una región. Esto ayudará a que su entorno ende clústeres sea más resistente a los daños de una sola AZ y le permitirá mantener una alta disponibilidad para las aplicaciones que se ejecuten en las demás AZ. Cuando inicie un cambio de zona para alejarse de la AZ afectada, la red integrada en el clúster de su entorno de Amazon EKS se actualizará automáticamente para utilizar solo las AZ en buen estado a fin de ayudar a mantener una alta disponibilidad para el clúster.
Asegurarse de disponer de una configuración multi-AZ para su entorno de Amazon EKS mejora la fiabilidad general de su sistema. Sin embargo, los entornos multi-AZ influyen en cómo se transfieren y procesan los datos de las aplicaciones, lo que, a su vez, repercute en las tarifas de red de su entorno. Concretamente, el tráfico de salida frecuente entre zonas (tráfico distribuido entre las AZ) puede tener un impacto importante en los costos relacionados con la red. Puede aplicar diferentes estrategias para controlar la cantidad de tráfico entre zonas en los pods de su clúster de Amazon EKS y reducir los costos asociados. Para obtener más información sobre cómo optimizar los costos de red cuando se utilizan entornos de Amazon EKS de alta disponibilidad, consulte estas prácticas recomendadas
En el siguiente diagrama, se ilustra un entorno de EKS de alta disponibilidad con tres AZ en buen estado.
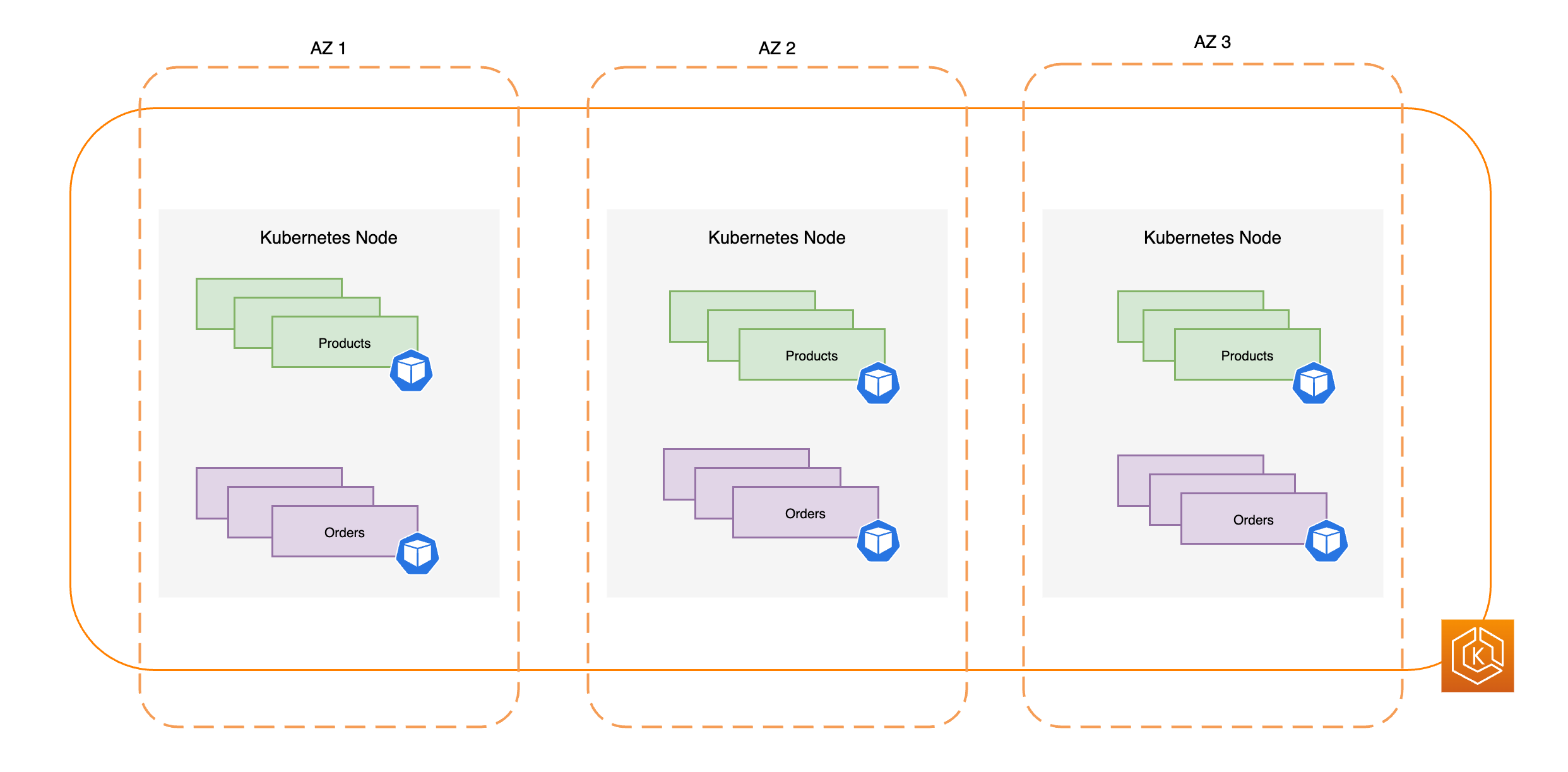
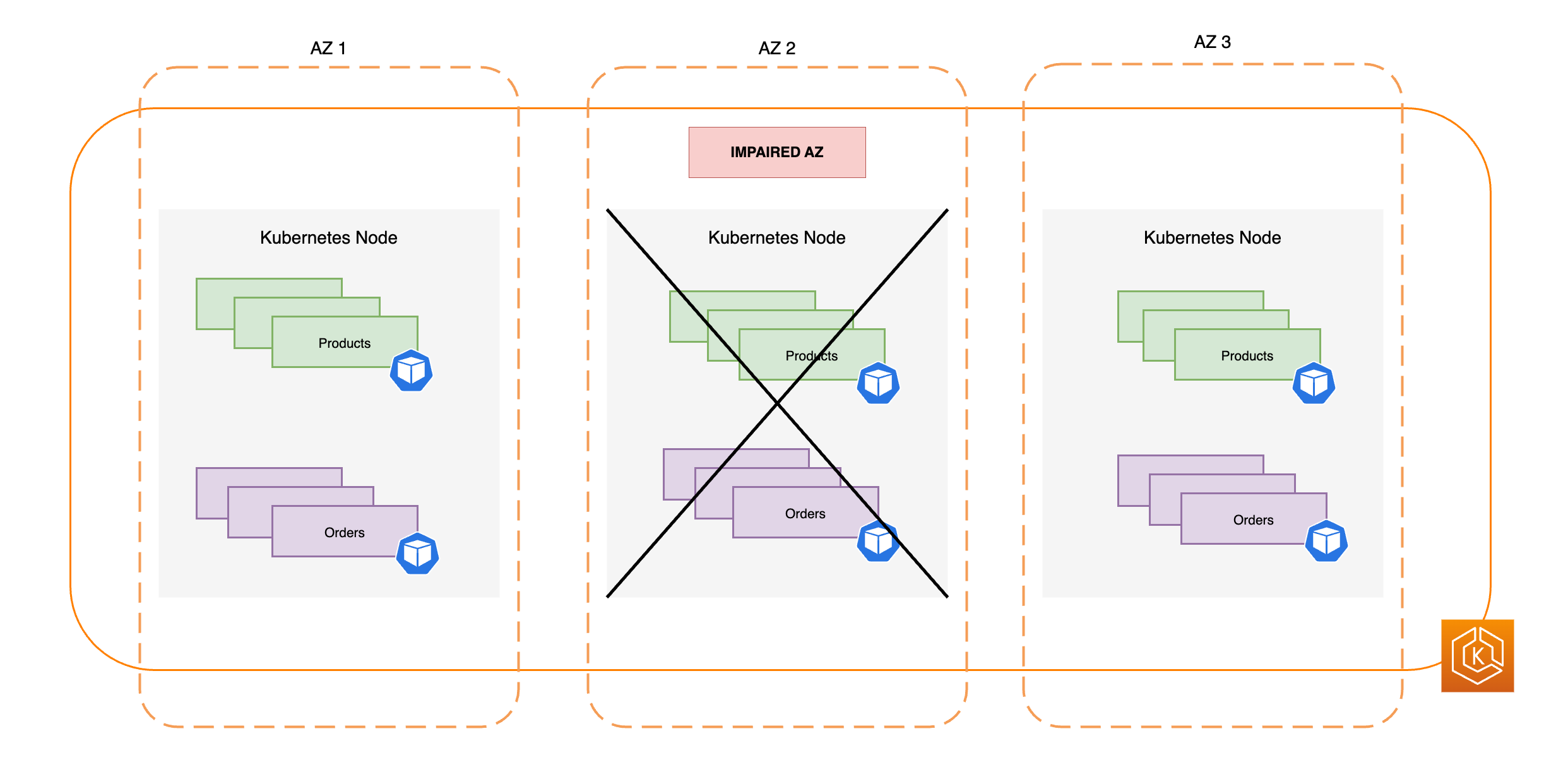
En el siguiente diagrama, se ilustra cómo un entorno de Amazon EKS con tres AZ es resistente a una AZ dañada y mantiene una alta disponibilidad gracias a dos AZ restantes en buen estado.
Aprovisionamiento de suficiente capacidad de computación para soportar la eliminación de una sola zona de disponibilidad
Para optimizar el uso de los recursos y los costos de su infraestructura de computación en el plano de datos de Amazon EKS, una práctica recomendada consiste e alinear la capacidad de computación con los requisitos de la carga de trabajo. Sin embargo, si todos sus nodos de trabajo están a plena capacidad, tiene que agregar nuevos nodos de trabajo al plano de datos de EKS antes de poder programar nuevos pods. Cuando ejecuta cargas de trabajo críticas, suele ser una práctica recomendada ejecutar una capacidad redundante en línea para gestionar distintos escenarios como el aumento repentino de la carga o los problemas de estado de los nodos. Si tiene previsto utilizar un cambio de zona, tiene previsto eliminar toda una zona de disponibilidad de capacidad si hubiera daños. Esto significa que debe ajustar la capacidad de computación redundante a fin de que sea suficiente para gestionar la carga incluso con una de las AZ desconectada.
Al escalar los recursos de computación, el proceso de agregar nuevos nodos al plano de datos de EKS lleva algún tiempo. Esto puede repercutir en el rendimiento y la disponibilidad en tiempo real de las aplicaciones, en especial si hay daños en una zona. Su entorno de Amazon EKS debe poder absorber la carga que supone perder una AZ sin que la experiencia de sus usuarios finales o clientes se deteriore. Esto significa minimizar o eliminar cualquier intervalo entre el momento en que se necesita un nuevo pod y el momento real en que se programa en un nodo de trabajo.
Además, si se producen daños en una zona, debe intentar reducir el riesgo de que se produzca una posible limitación de la capacidad de computación que impida agregar nuevos nodos necesarios al plano de datos de Amazon EKS en las AZ en buen estado.
Para reducir el riesgo de estos posibles impactos negativos, le recomendamos aprovisionar en exceso la capacidad de computación en algunos de los nodos de trabajo de cada AZ. De este modo, el programador de Kubernetes dispone de una capacidad preexistente para colocar nuevos pods, lo que es de especial importancia si se pierde una de las AZ del entorno.
Ejecución y distribución de varias réplicas de pods entre zonas de disponibilidad
Kubernetes le permite escalar previamente sus cargas de trabajo mediante la ejecución de varias instancias (réplicas de pods) de una sola aplicación. Al ejecutar varias réplicas de pods para una aplicación, se eliminan puntos de error y se aumenta su rendimiento general, ya que se reduce la carga de recursos en una sola réplica. Sin embargo, para que sus aplicaciones tengan una alta disponibilidad y una mejor tolerancia a errores, le recomendamos que ejecute y distribuya varias réplicas de su aplicación en distintos dominios de errores, también denominados dominios de topología. Los dominios de errores de este escenario son las zonas de disponibilidad. Al utilizar las restricciones de distribución topológica
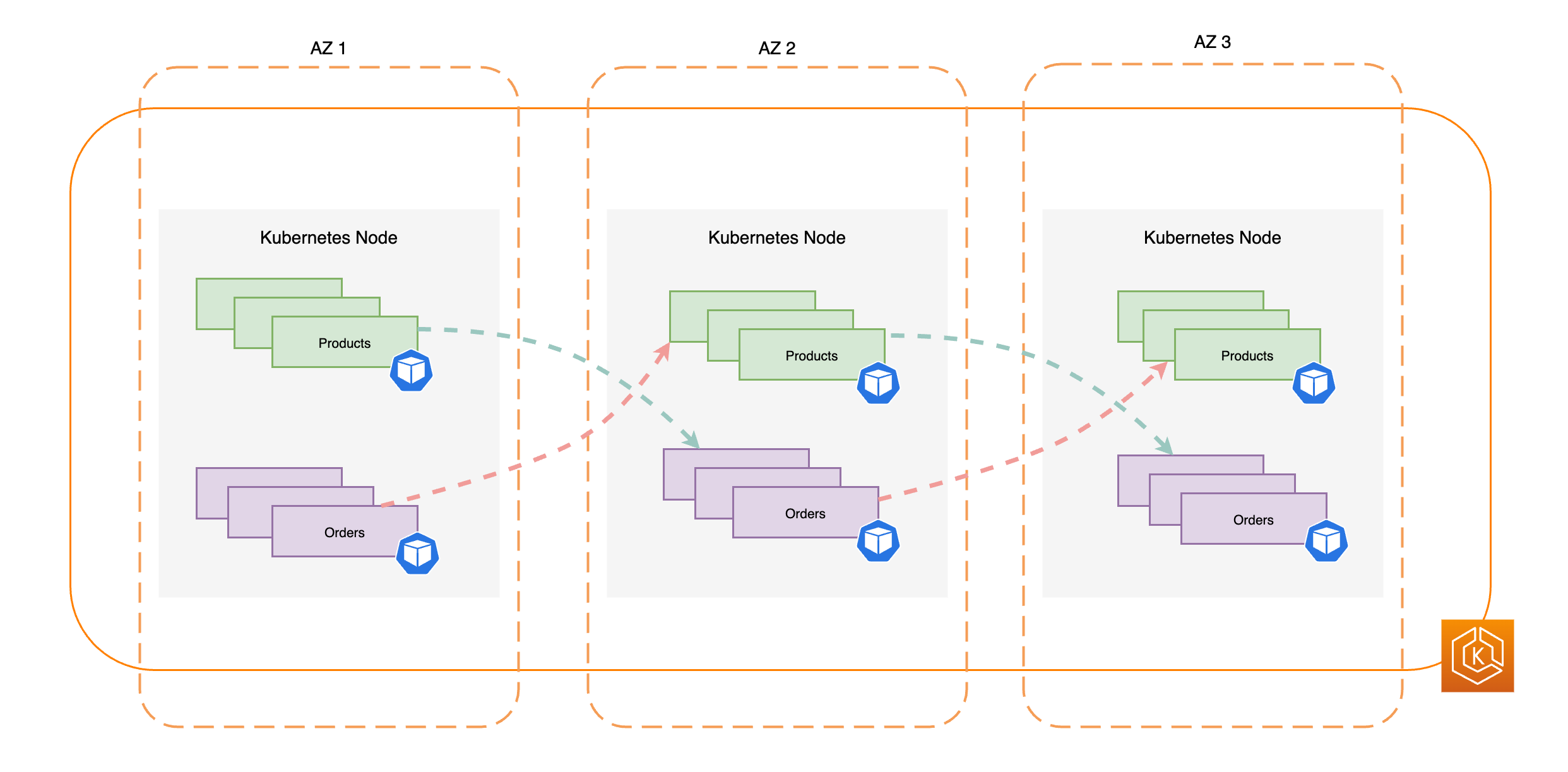
En el siguiente diagrama, se ilustra un entorno de Amazon EKS que tiene un flujo de tráfico de este a oeste cuando todas las AZ están en buen estado.
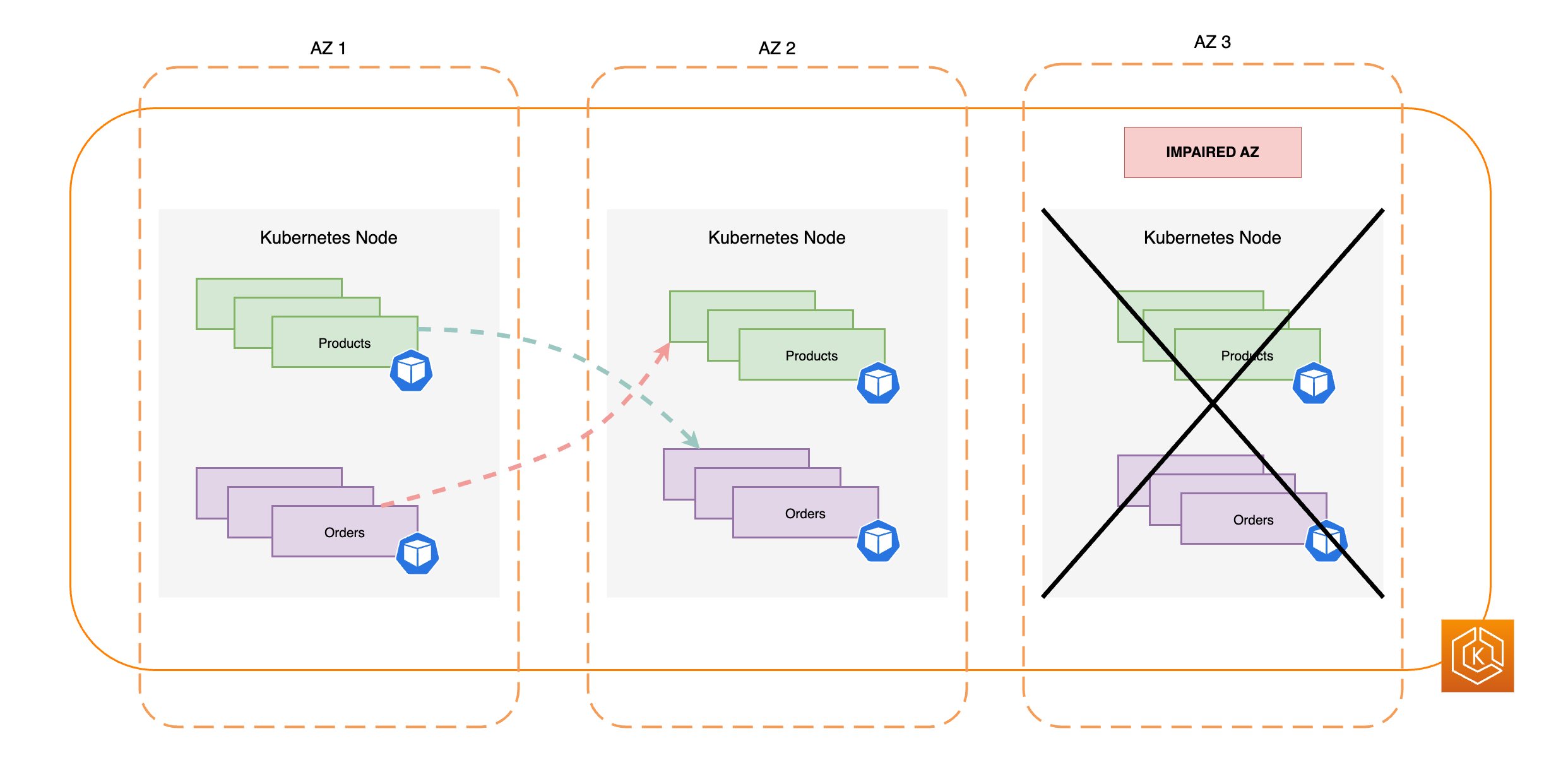
En el siguiente diagrama, se ilustra un entorno de Amazon EKS que tiene un flujo de tráfico de este a oeste en el que se ha producido un error en una sola zona de disponibilidad y ha iniciado un cambio de zona.
El siguiente fragmento de código es un ejemplo de cómo configurar la carga de trabajo con varias réplicas en Kubernetes.
apiVersion: apps/v1 kind: Deployment metadata: name: orders spec: replicas: 9 selector: matchLabels: app: orders template: metadata: labels: app: orders tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: orders
Lo que es más importante, debe ejecutar varias réplicas del software de servidor de DNS (CoreDNS/kube-dns) y aplicar restricciones de distribución topológica similares si no están configuradas de forma predeterminada. Esto ayuda a garantizar que, si hay daños en una sola AZ, disponga de suficientes pods de DNS en AZ en buen estado para poder continuar con la gestión de las solicitudes de detección de servicios de otros pods que se comunican entre sí en el clúster. El complemento de EKS de CoreDNS tiene una configuración predeterminada para los pods de CoreDNS que garantiza que, si hay nodos en varias AZ disponibles, se distribuyan en las zonas de disponibilidad del clúster. Si lo desea, también puede reemplazar esta configuración predeterminada por su propia configuración personalizada.
Al instalar CoreDNS con HelmreplicaCount en el archivo values.yamltopologySpreadConstraints en el mismo archivo values.yaml. En el siguiente fragmento de código, se ilustra cómo puede configurar CoreDNS para hacerlo.
CoredNS Helm values.yaml
replicaCount: 6 topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: k8s-app: kube-dns
Si hay daños en una AZ, puede absorber el aumento de carga de los pods de CoreDNS mediante un sistema de escalado automático para CoreDNS. La cantidad de instancias de DNS que necesite dependerá de la cantidad de cargas de trabajo que se ejecuten en el clúster. CoreDNS está vinculado a la CPU, lo que le permite escalar en función de la CPU mediante el Escalador automático de pods horizontales (HPA)
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: coredns namespace: default spec: maxReplicas: 20 minReplicas: 2 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: coredns targetCPUUtilizationPercentage: 50
Como alternativa, Amazon EKS puede administrar el escalado automático de la implementación de CoreDNS en la versión del complemento de EKS de CoreDNS. Este escalador automático de CoreDNS monitorea continuamente el estado del clúster, incluida la cantidad de nodos y núcleos de CPU. En función de esa información, el controlador ajusta dinámicamente el número de réplicas de la implementación de CoreDNS en un clúster de Amazon EKS.
Para activar la configuración de escalado automático en el complemento de EKS de CoreDNS, utilice la configuración siguiente:
{ "autoScaling": { "enabled": true } }
También puede usar el NodeLocal DNS
Colocación de pods interdependientes en la misma zona de disponibilidad
Por lo general, las aplicaciones tienen cargas de trabajo distintas que deben comunicarse entre sí para completar correctamente un proceso integral. Si estas distintas aplicaciones están distribuidas en diferentes AZ y no están ubicadas en la misma AZ, el proceso integral puede verse afectado si hay daños en una sola AZ. Por ejemplo, si la Aplicación A tiene varias réplicas en la AZ 1 y la AZ 2, pero la Aplicación B tiene todas sus réplicas en la AZ 3, la pérdida de la AZ 3 afectará al proceso integral entre las dos cargas de trabajo, Aplicación A y Aplicación B. Si combina las restricciones de distribución topológica con la afinidad de pods, puede mejorar la resiliencia de la aplicación mediante la distribución de pods entre todas las AZ. Además, se configura una relación entre determinados pods para garantizar su coubicación.
Con las reglas de afinidad de los pods
apiVersion: apps/v1 kind: Deployment metadata: name: products namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
En el siguiente diagrama, se muestran varios pods que se han ubicado en el mismo nodo con reglas de afinidad de pods.
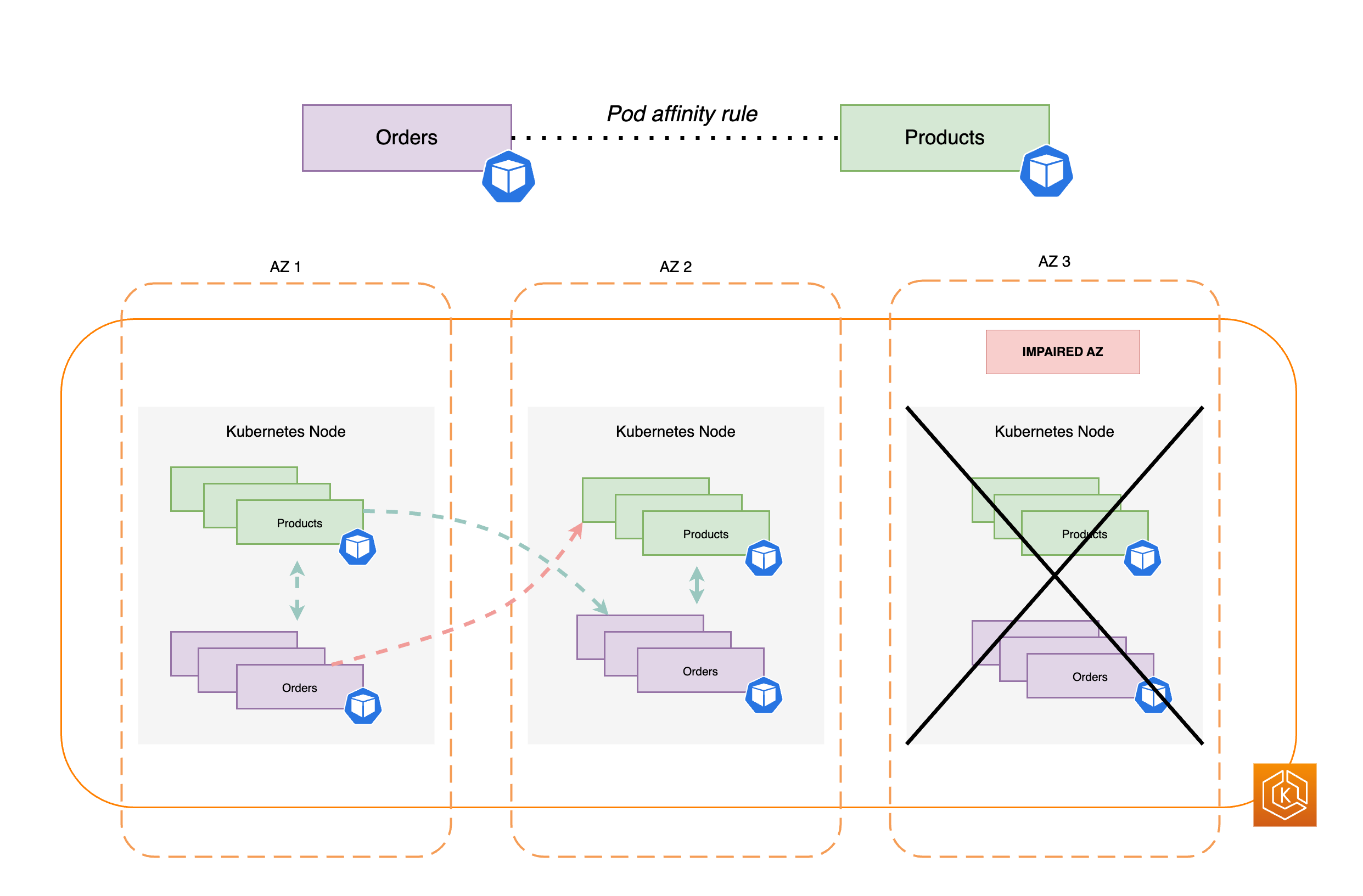
Comprobación de si el entorno de clústeres puede soportar la pérdida de una AZ
Después de cumplir los requisitos descritos en las secciones anteriores, el siguiente paso es comprobar que disponga de la capacidad de computación y cargas de trabajo suficientes para afrontar la pérdida de una AZ. Para ello, puede iniciar un cambio de zona en EKS de forma manual. Como alternativa, puede activar el cambio de zona automático y configurar ejecuciones de práctica, que también comprueban que las aplicaciones funcionen según lo esperado con una AZ menos en el entorno de clústeres.
Preguntas frecuentes
Por qué debo utilizar esta característica?
Al utilizar el cambio de zona o el cambio de zona automático de ARC en su clúster de Amazon EKS es más fácil mantener la disponibilidad de las aplicaciones de Kubernetes al automatizar el proceso de recuperación rápida que consiste en desviar el tráfico de red de una zona de disponibilidad defectuosa dentro del clúster. Con ARC, puede evitar pasos largos y complicados que pueden conllevar un periodo de recuperación prolongado cuando se producen daños en las AZ.
¿Cómo funciona esta característica con otros servicios de AWS?
EKS se integra con ARC, que proporciona la interfaz principal en la que puede llevar a cabo las operaciones de recuperación en AWS. Para garantizar que el tráfico interno del clúster se aleje de manera apropiada de una AZ dañada, EKS hace modificaciones en la lista de puntos de conexión de red para los pods que se ejecutan en el plano de datos de Kubernetes. Si utiliza Elastic Load Balancing para dirigir el tráfico externo al clúster, puede registrar los equilibradores de carga con ARC e iniciar un cambio de zona en ellos para evitar que el tráfico fluya hacia la AZ dañada. El cambio de zona también funciona con grupos de Amazon EC2 Auto Scaling creados por los grupos de nodos administrados por EKS. Para evitar que una AZ dañada se utilice para lanzar nuevos nodos o pods de Kubernetes, EKS elimina la AZ dañada de los grupos de escalado automático.
En qué se diferencia esta característica de las protecciones predeterminadas de Kubernetes?
Esta característica funciona junto con varias protecciones integradas de Kubernetes que ayudan a la resiliencia de las aplicaciones de los clientes. Puede configurar sondeos de disponibilidad y actividad de un pod que decidan cuándo un pod debe recibir tráfico. Cuando se produce un error en estos sondeos, Kubernetes elimina estos pods como objetivos de un servicio y deja de enviarse el tráfico al pod. Si bien esto es útil, no es sencillo para los clientes configurar estas comprobaciones de estado de forma que se garantice que se produzca un error cuando una AZ se dañe. La característica de cambio de zona de ARC proporciona una red de seguridad adicional que lo ayuda a aislar por completo una AZ dañada cuando las protecciones nativas de Kubernetes no fueron suficientes. El cambio de zona también le proporciona una forma sencilla de evaluar la preparación operativa y la resiliencia de su arquitectura.
¿AWS puede iniciar un cambio de zona en mi nombre?
Sí, si desea utilizar el cambio de zona de ARC de forma totalmente automática, puede activar el cambio de zona automático de ARC. Con el cambio de zona automático, puede depender de AWS para supervisar el estado de las AZ del clúster de EKS e iniciar un cambio de zona cuando se detecten daños en la AZ de manera automática.
Qué ocurre si utilizo esta característica y mis nodos de trabajo y cargas de trabajo no están escaladas previamente?
Si no ha escalado previamente y depende del aprovisionamiento de nodos o pods adicionales durante un cambio de zona, corre el riesgo de que la recuperación se retrase. El proceso de agregar nuevos nodos al plano de datos de EKS lleva algún tiempo, lo que puede afectar al rendimiento y la disponibilidad en tiempo real de las aplicaciones, especialmente si hay daños en una zona. Además, si se producen daños en una zona, es posible que se encuentre con una limitación de la capacidad de computación que impida agregar nuevos nodos necesarios a las AZ en buen estado.
Si sus cargas de trabajo no se han escalado previamente y no están distribuidas entre todas las AZ del clúster, los daños de una zona podrían afectar a la disponibilidad de una aplicación que solo se ejecuta en los nodos de trabajo de una AZ afectada. Para reducir el riesgo de una interrupción total de la disponibilidad de la aplicación, Amazon EKS dispone de un sistema de seguridad para que el tráfico se envíe a los puntos de conexión de los pods situados en una zona afectada, si esa carga de trabajo tiene todos sus puntos de conexión en una AZ en mal estado. Sin embargo, le recomendamos encarecidamente que escale previamente sus aplicaciones y las distribuya en todas las AZ para mantener la disponibilidad si se produce un problema en un zona.
¿Cómo funciona si ejecuto una aplicación con estado?
Si ejecuta una aplicación con estado, debe evaluar su tolerancia a errores en función del caso de uso y la arquitectura. Si tiene una arquitectura o un patrón, ya sea activo o en espera, es posible que haya instancias en las que el elemento activo se encuentre en una AZ dañada. En la aplicación, si el elemento en espera no se activa, es posible que tenga problemas con la aplicación. También es posible que tenga problemas cuando se lancen nuevos pods de Kubernetes en AZ en buen estado, ya que no se podrán conectar a los volúmenes persistentes enlazados a la AZ dañada.
Funciona esta característica con Karpenter?
Karpenter es compatible con el cambio de zona y el cambio de zona automático de ARC en EKS con la versión 1.12 de Karpenter o posterior
Funciona esta característica con EKS Fargate?
Esta característica no es compatible con EKS Fargate. De forma predeterminada, cuando EKS Fargate reconoce un evento de salud en una zona, los pods preferirán ejecutarse en las otras AZ.
Amazon EKS afectará el plano de control de Kubernetes administrado?
No, de manera predeterminada Amazon EKS ejecuta y escala el plano de control de Kubernetes en varias AZ para garantizar una alta disponibilidad. El cambio de zona y el cambio de zona automático de ARC solo actúan en el plano de datos de Kubernetes.
Hay algún costo asociado a esta nueva característica?
Puede utilizar el cambio de zona y el cambio de zona automático de ARC en su clúster de Amazon EKS sin ningún costo adicional. Sin embargo, continuará pagando por las instancias aprovisionadas y le recomendamos encarecidamente que escale previamente el plano de datos de Kubernetes antes de utilizar esta característica. Debe plantearse que haya un equilibrio entre el costo y la disponibilidad de la aplicación.
Recursos adicionales
