AWS Lake Formation es compatible con la creación de tablas Apache Iceberg que utilizan el formato de datos Apache Parquet en el AWS Glue Data Catalog con datos que residen en Amazon S3. Una tabla en el Catálogo de datos es la definición de metadatos que representa los datos en un almacén de datos. De forma predeterminada, Lake Formation crea tablas Iceberg v2. Para ver la diferencia entre las tablas v1 y v2, consulte Cambios de versión de formato
Apache Iceberg
Puede utilizar la consola de Lake Formation o la operación CreateTable en la API de AWS Glue para crear una tabla Iceberg en el Catálogo de datos. Para obtener más información, consulte la acción CreateTable (Python: create_table).
Cuando cree una tabla de Iceberg en el Catálogo de datos, deberá especificar el formato de la tabla y la ruta del archivo de metadatos en Amazon S3 para poder hacer lecturas y escrituras.
Puede utilizar Lake Formation para asegurar su tabla de Iceberg utilizando permisos de control de acceso específicos cuando registre la ubicación de datos de Amazon S3 con AWS Lake Formation. Para los datos de origen en Amazon S3 y los metadatos que no están registrados en Lake Formation, el acceso se determina mediante las políticas de permisos de IAM para Amazon S3 y acciones de AWS Glue. Para obtener más información, consulte Administrar los permisos de Lake Formation.
nota
El Catálogo de datos no admite la creación de particiones ni la adición de propiedades de tablas de iceberg.
Requisitos previos
Para crear tablas de Iceberg en el Catálogo de datos y configurar los permisos de acceso a los datos de Lake Formation, debe cumplir los siguientes requisitos:
-
Se requieren permisos para crear tablas de Iceberg sin datos registrados en Lake Formation.
Además de los permisos necesarios para crear una tabla en el Catálogo de datos, el creador de la tabla requiere los siguientes permisos:
s3:PutObjecten el recurso arn:aws:s3:::{bucketName}-
s3:GetObjecten el recurso arn:aws:s3:::{bucketName} -
s3:DeleteObjecten el recurso arn:aws:s3:::{bucketName}
-
Se requieren permisos para crear tablas de Iceberg con datos registrados en Lake Formation:
Para utilizar Lake Formation para administrar y asegurar los datos de su lago de datos, registre su ubicación de Amazon S3 que tiene los datos de las tablas con Lake Formation. De este modo, Lake Formation puede expedir credenciales a servicios analíticos de AWS como Athena, Redshift Spectrum y Amazon EMR para acceder a los datos. Para obtener más información sobre el registro de una ubicación de Amazon S3, consulte Añadir una ubicación de Amazon S3 a su lago de datos.
Una entidad principal que lee y escribe los datos subyacentes que están registrados en Lake Formation requiere los siguientes permisos:
-
lakeformation:GetDataAccess -
DATA_LOCATION_ACCESSUna entidad principal que tiene permisos de localización de datos en una localización también tiene permisos de localización en todas las ubicaciones secundarias.
Para obtener más información sobre permisos de ubicación de datos, consulte Control de acceso a los datos subyacentes.
-
Para habilitar la compactación, el servicio debe asumir un rol de IAM que tenga permisos para actualizar las tablas del Catálogo de datos. Para obtener más información, consulte Requisitos previos para la optimización de tablas.
Creación de tablas de Iceberg
Puede crear tablas de Iceberg v1 y v2 con la consola Lake Formation o la AWS Command Line Interface tal como se documenta en esta página. También puede crear tablas de Iceberg utilizando la consola de AWS Glue o Rastreador de AWS Glue. Para más información, consulte Catálogo de datos y rastreadores en la Guía para desarrolladores de AWS Glue.
Para crear una tabla de Iceberg
Inicie sesión en la AWS Management Console y abra la consola de Lake Formation en https://console.aws.amazon.com/lakeformation/
. En Catálogo de datos, seleccione Tablas y utilice el botón Crear tabla para especificar los siguientes atributos:
-
Nombre de tabla. Escriba un nombre para la tabla. Si utiliza Athena para acceder a las tablas, utilice los consejos para nombres recogidos en la Guía del usuario de Amazon Athena.
-
Base de datos. Elija una base de datos existente o cree una nueva.
-
Descripción. Descripción de la tabla. Puede escribir una descripción para ayudarle a entender el contenido de la tabla.
-
Formato de tabla. Para el formato de la tabla, elija Apache Iceberg.
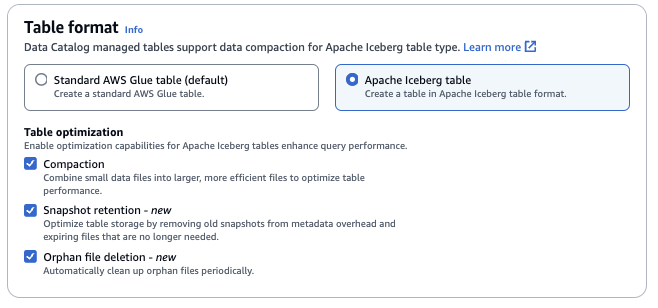
Optimización de tablas
-
Compactación: los archivos de datos se combinan y se reescriben para eliminar los datos obsoletos y consolidar los datos fragmentados en archivos más grandes y eficientes.
Retención de instantáneas: las instantáneas son versiones con fecha y hora de una tabla de Iceberg. Las configuraciones de retención de instantáneas permiten a los clientes determinar cuánto tiempo se deben retener las instantáneas y cuántas instantáneas retener. La configuración de un optimizador de retención de instantáneas puede ayudar a administrar la sobrecarga de almacenamiento mediante la eliminación de las instantáneas antiguas e innecesarias y sus correspondientes archivos subyacentes.
Eliminación de archivos huérfanos: los archivos huérfanos son archivos a los que los metadatos de la tabla de Iceberg ya no hacen referencia. Con el tiempo, estos archivos se pueden acumular, sobre todo después de operaciones como la eliminación de tablas o los errores en los trabajos de ETL. Habilitar la eliminación de archivos huérfanos permite a AWS Glue identificar y eliminar periódicamente estos archivos innecesarios y así liberar espacio de almacenamiento.
Para obtener más información, consulte Optimización de las tablas de Iceberg.
-
-
Rol de IAM. Para ejecutar la compactación, el servicio asume un rol de IAM en su nombre. Puede elegir un rol de IAM mediante el menú desplegable. Asegúrese de que el rol tenga los permisos necesarios para habilitar la compactación.
Para obtener más información sobre los permisos necesarios, consulte Requisitos previos para la optimización de tablas.
-
Ubicación. Especifique la ruta a la carpeta de Amazon S3 que almacena la tabla de metadatos. Iceberg necesita un archivo de metadatos y una ubicación en el Catálogo de datos para poder hacer lecturas y escrituras.
-
Esquema. Seleccione Agregar columnas para añadir columnas y tipos de datos de las columnas. Tiene la opción de crear una tabla vacía y actualizar el esquema más adelante. El Catálogo de datos admite los tipos de datos de Hive. Para obtener más información, consulte Tipos de datos de Hive
. Con Iceberg podrá desarrollar el esquema y la partición después de crear la tabla. Puede utilizar consultas de Athena para actualizar el esquema de la tabla y consultas de Spark
para actualizar las particiones.
-
