Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Préparation aux incidents dans Incident Manager
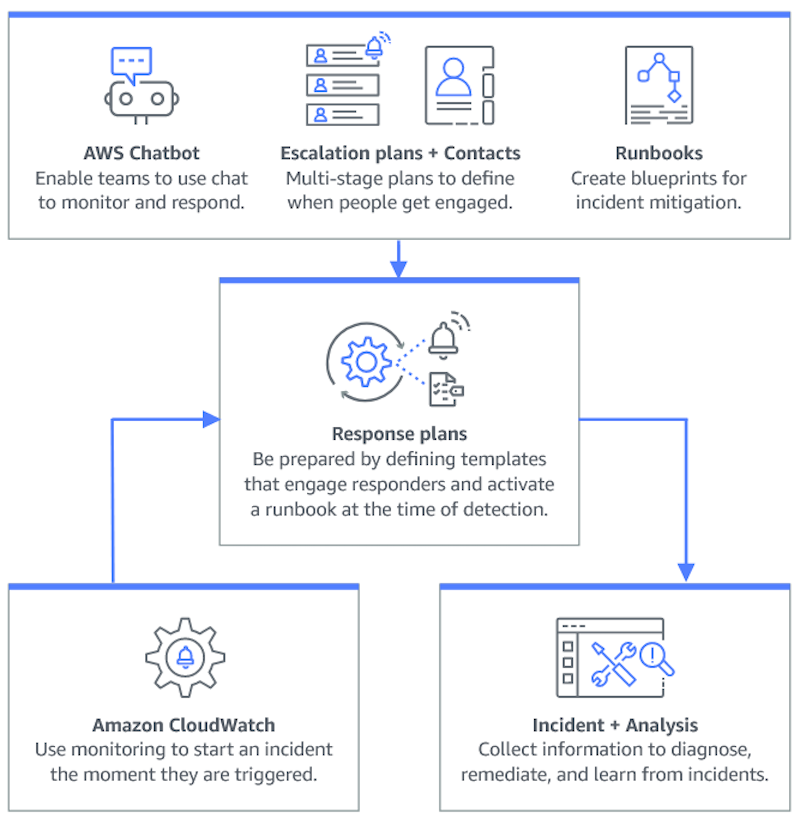
La planification d'un incident commence bien avant le cycle de vie de l'incident. Comme le montre l'illustration suivante, avant de commencer à répondre aux incidents, vous devez vous préparer en configurant des canaux de discussion, en créant des plans d'escalade, en spécifiant les contacts et en déterminant les runbooks d'automatisation à utiliser pour répondre aux incidents. Utilisez ensuite un plan de réponse qui précise le mode de surveillance et indique si les réponses sont automatisées. Une fois la correction terminée, vous pouvez analyser l'incident et la réponse à l'incident afin d'affiner votre plan de réponse pour les futurs incidents.
Rubriques
- Surveillance
- Configuration des ensembles de réplication et des résultats dans Incident Manager
- Création et configuration de contacts dans Incident Manager
- Gestion de la rotation des intervenants avec des horaires d'astreinte dans Incident Manager
- Création d'un plan d'escalade pour l'engagement des intervenants dans Incident Manager
- Création et intégration de canaux de discussion pour les intervenants dans Incident Manager
- Intégration des runbooks Systems Manager Automation dans Incident Manager pour remédier aux incidents
- Création et configuration de plans de réponse dans Incident Manager
- Identifier les causes potentielles des incidents provenant d'autres services en tant que « constatations » dans Incident Manager
Surveillance
La surveillance de l'état de vos applications AWS hébergées est essentielle pour garantir le temps de disponibilité et les performances des applications. Lorsque vous déterminez des solutions de surveillance, tenez compte des points suivants :
-
Criticité de la fonctionnalité — Si le système devait tomber en panne, quel en serait l'impact critique pour les utilisateurs en aval.
-
Caractère commun des défaillances — Quelle est la fréquence des défaillances d'un système ? Les systèmes nécessitant des interventions fréquentes doivent être étroitement surveillés.
-
Latence accrue : augmentation ou diminution du temps nécessaire à l'exécution d'une tâche.
-
Mesures côté client et côté serveur : en cas de divergence entre les mesures associées sur le client et sur le serveur.
-
Défaillances de dépendance : défaillances auxquelles votre équipe peut et doit se préparer.
Après avoir créé des plans de réponse, vous pouvez utiliser vos solutions de surveillance pour suivre automatiquement les incidents dès qu'ils se produisent dans votre environnement. Pour plus d'informations sur le suivi et la création d'incidents, consultezAfficher les détails de l'incident dans la console Incident Manager.
