Après mûre réflexion, nous avons décidé de mettre fin à Amazon Kinesis Data Analytics pour les applications SQL :
1. À compter du 1er septembre 2025, nous ne fournirons aucune correction de bogue pour les applications Amazon Kinesis Data Analytics for SQL, car leur support sera limité, compte tenu de l'arrêt prochain.
2. À compter du 15 octobre 2025, vous ne pourrez plus créer de nouvelles applications Kinesis Data Analytics for SQL.
3. Nous supprimerons vos candidatures à compter du 27 janvier 2026. Vous ne serez pas en mesure de démarrer ou d'utiliser vos applications Amazon Kinesis Data Analytics for SQL. Support ne sera plus disponible pour Amazon Kinesis Data Analytics for SQL à partir de cette date. Pour de plus amples informations, veuillez consulter Arrêt d'Amazon Kinesis Data Analytics pour les applications SQL.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Mise en parallèle des flux d'entrée pour un débit accru
Note
Après le 12 septembre 2023, vous ne pourrez plus créer de nouvelles applications en utilisant Kinesis Data Firehose comme source si vous n’utilisez pas déjà Kinesis Data Analytics pour SQL. Pour plus d’informations, consultez Limites .
Les applications Amazon Kinesis Data Analytics peuvent prendre en charge plusieurs flux d’entrée intégrés à l’application pour mettre une application à l’échelle au-delà du débit d’un flux d’entrée intégré. Pour plus d'informations sur les flux d'entrée intégrés à l'application, consultez Applications Amazon Kinesis Data Analytics pour SQL : fonctionnement.
Dans presque tous les cas, Amazon Kinesis Data Analytics adapte votre application pour gérer la capacité des flux Kinesis ou des flux sources Firehose qui alimentent votre application. Toutefois, si le débit de votre flux source est supérieur au débit d'un flux d'entrée intégré à l'application, vous pouvez augmenter sensiblement le nombre de flux d'entrée que votre application utilise. Pour ce faire, vous devez utiliser le paramètre InputParallelism.
Lorsque le paramètre InputParallelism est supérieur à un, Amazon Kinesis Data Analytics répartit uniformément les partitions de votre flux source entre les flux intégrés à l’application. Par exemple, si votre flux source possède 50 partitions et que vous avez défini InputParallelism sur 2, chaque flux d'entrée intégré à l'application reçoit les entrées de 25 partitions du flux source.
Si vous augmentez le nombre de flux, votre application doit accéder explicitement aux données de chaque flux. Pour plus d'informations sur l'accès aux différents flux intégrés à l'application dans votre code, consultez Accès à In-Application des flux distincts dans votre application Amazon Kinesis Data Analytics.
Bien que les fragments de flux Kinesis Data Streams et Firehose soient tous deux répartis de la même manière entre les flux intégrés à l'application, ils apparaissent différemment dans votre application :
Les enregistrements d’un flux de données Kinesis incluent un champ
shard_idqui peut servir à identifier la partition source de l’enregistrement.Les enregistrements d'un flux de diffusion Firehose n'incluent pas de champ identifiant la partition ou la partition source de l'enregistrement. Cela est dû au fait que Firehose extrait ces informations de votre application.
Évaluation de l'opportunité d'augmenter le nombre de flux In-Application d'entrée
Dans la plupart des cas, un flux d'entrée intégré à l'application peut traiter le débit d'un flux source, selon la complexité et la taille des données des flux d'entrée. Pour déterminer si vous devez augmenter le nombre de flux d'entrée intégrés à l'application, vous pouvez surveiller les MillisBehindLatest métriques InputBytes et sur Amazon CloudWatch.
Si la InputBytes métrique est supérieure à 100 MB/sec (ou si vous prévoyez qu'elle sera supérieure à ce taux), cela peut entraîner une augmentation MillisBehindLatest et un impact accru des problèmes liés aux applications. Pour résoudre ce problème, il est recommandé de faire les choix de langues suivants pour votre application :
Utilisez plusieurs flux et les applications Kinesis Data Analytics for SQL si votre application a des besoins de mise à l'échelle supérieurs à 100. MB/second
Utilisez les applications Kinesis Data Analytics pour Java si vous voulez utiliser un seul flux et une application.
Si la métrique MillisBehindLatest possède l'une des caractéristiques suivantes, vous devez augmenter le paramètre InputParallelism de votre application :
La métrique
MillisBehindLatestaugmente progressivement, ce qui indique que votre application est en retard par rapport aux dernières données du flux.La métrique
MillisBehindLatestest systématiquement supérieure à 1 000 (une seconde).
Vous n'avez pas besoin d'augmenter le paramètre InputParallelism de votre application si :
La métrique
MillisBehindLatestbaisse progressivement, ce qui indique que votre application devance les dernières données du flux.La métrique
MillisBehindLatestest systématiquement inférieure à 1 000 (une seconde).
Pour plus d'informations sur l'utilisation CloudWatch, consultez le guide de CloudWatch l'utilisateur.
Implémentation de plusieurs flux In-Application d'entrée
Vous pouvez définir le nombre de flux d'entrée intégrés à l'application lorsqu'une application est créée à l'aide de CreateApplication. Ce nombre est défini une fois que l'application a été créée à l'aide de UpdateApplication.
Note
Vous ne pouvez définir le paramètre InputParallelism qu’à l’aide de l’API Amazon Kinesis Data Analytics ou de l’ AWS CLI. Vous ne pouvez pas définir ce paramètre à l'aide du Console de gestion AWS. Pour plus d'informations sur la configuration du AWS CLI, voirÉtape 2 : configurer le AWS Command Line Interface (AWS CLI).
Définition du nombre de flux d'entrée d'une nouvelle application
L'exemple suivant montre comment utiliser l'action d'API CreateApplication pour définir le nombre de flux d'entrée d'une nouvelle application sur 2.
Pour plus d’informations sur CreateApplication, consultez CreateApplication.
{ "ApplicationCode": "<The SQL code the new application will run on the input stream>", "ApplicationDescription": "<A friendly description for the new application>", "ApplicationName": "<The name for the new application>", "Inputs": [ { "InputId": "ID for the new input stream", "InputParallelism": { "Count": 2 }], "Outputs": [ ... ], }] }
Définition du nombre de flux d'entrée d'une application existante
L'exemple suivant montre comment utiliser l'action d'API UpdateApplication pour définir le nombre de flux d'entrée d'une application existante sur 2.
Pour plus d’informations sur Update_Application, consultez UpdateApplication.
{ "InputUpdates": [ { "InputId": "yourInputId", "InputParallelismUpdate": { "CountUpdate": 2 } } ], }
Accès à In-Application des flux distincts dans votre application Amazon Kinesis Data Analytics
Pour utiliser plusieurs flux d'entrée intégrés à l'application au sein de votre application, vous devez sélectionner explicitement différents flux. L'exemple de code suivant montre comment interroger plusieurs flux d'entrée intégrés à l'application créés dans le didacticiel de mise en route.
Dans l'exemple suivant, chaque flux source est d'abord agrégé avec COUNT avant d'être combiné en un seul flux intégré à l'application, appelé in_application_stream001. L'agrégation des flux source en amont vous permet de vous assurer que les flux combinés peuvent gérer le trafic de plusieurs flux sans être surchargés.
Note
Pour exécuter cet exemple et obtenir des résultats des deux flux d'entrée intégrés à l'application, vous devez mettre à jour le nombre de partitions dans votre flux source et le paramètre InputParallelism dans votre application.
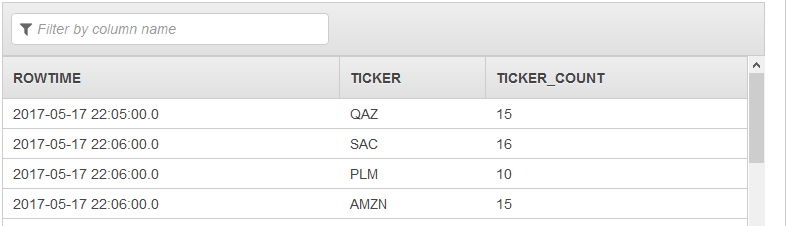
CREATE OR REPLACE STREAM in_application_stream_001 ( ticker VARCHAR(64), ticker_count INTEGER ); CREATE OR REPLACE PUMP pump001 AS INSERT INTO in_application_stream_001 SELECT STREAM ticker_symbol, COUNT(ticker_symbol) FROM source_sql_stream_001 GROUP BY STEP(source_sql_stream_001.rowtime BY INTERVAL '60' SECOND), ticker_symbol; CREATE OR REPLACE PUMP pump002 AS INSERT INTO in_application_stream_001 SELECT STREAM ticker_symbol, COUNT(ticker_symbol) FROM source_sql_stream_002 GROUP BY STEP(source_sql_stream_002.rowtime BY INTERVAL '60' SECOND), ticker_symbol;
L'exemple de code précédent produit dans in_application_stream001 un résultat similaire à ce qui suit :
Considérations supplémentaires
Si vous utilisez plusieurs flux d'entrée, vous devez savoir que :
Le nombre maximal de flux d'entrée intégrés à l'application est de 64.
Les flux d'entrée intégrés à l'application sont répartis uniformément entre les partitions du flux d'entrée de l'application.
Les gains de performances résultant de l'ajout de flux intégrés à l'application ne sont pas linéaires. Ainsi, le fait de doubler le nombre de flux intégrés à l'application ne double pas le débit. Avec une taille de ligne classique, chaque flux intégré à l'application peut atteindre un débit de 5 000 à 15 000 lignes par seconde. En passant le nombre de flux intégrés à l'application à 10, vous pouvez obtenir un débit de 20 000 à 30 000 lignes par seconde. La vitesse du débit dépend du nombre, des types et de la taille des données des champs dans le flux d'entrée.
Certaines fonctions d'agrégation (comme AVG) peuvent générer des résultats inattendus en cas de répartition des flux d'entrée entre plusieurs partitions. Etant donné que vous devez agréger toutes les partitions avant de les rassembler en un flux agrégé, les résultats peuvent être dirigés vers le flux contenant le plus d'enregistrements, quel qu'il soit.
Si votre application continue d’offrir des performances médiocres (ce qui est reflété par une métrique
MillisBehindLatestélevée) lorsque vous augmentez le nombre de flux d’entrée, vous avez peut-être atteint votre limite d’unités de traitement Kinesis (KPU). Pour de plus amples informations, veuillez consulter Dimensionnement automatique des applications pour augmenter le débit.
