Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Qu'est-ce qu'Amazon Managed Service pour Apache Flink ?
Avec Amazon Managed Service pour Apache Flink, vous pouvez utiliser Java, Scala, Python ou SQL pour traiter et analyser les données de streaming. Le service vous permet de créer et d'exécuter du code à partir de sources de streaming et de sources statiques pour effectuer des analyses de séries chronologiques, alimenter des tableaux de bord en temps réel et des métriques.
Vous pouvez créer des applications avec le langage de votre choix dans Managed Service for Apache Flink à l'aide de bibliothèques open source basées sur Apache
Le service géré pour Apache Flink fournit l’infrastructure sous-jacente pour vos applications Apache Flink. Il gère des fonctionnalités de base telles que le provisionnement des ressources informatiques, la résilience au basculement en mode AZ, le calcul parallèle, le dimensionnement automatique et les sauvegardes d'applications (mises en œuvre sous forme de points de contrôle et de snapshots). Vous pouvez utiliser les fonctionnalités de programmation de haut niveau de Flink (telles que les opérateurs, les fonctions, les sources et les récepteurs) de la même manière que lorsque vous hébergez vous-même l’infrastructure Flink.
Choisissez entre utiliser le service géré pour Apache Flink ou le service géré pour Apache Flink Studio
Vous avez deux options pour exécuter vos tâches Flink avec Amazon Managed Service pour Apache Flink. Avec Managed Service for Apache Flink, vous créez des applications Flink en Java, Scala ou Python (et en SQL intégré) à l'aide de l'IDE de votre choix et des API Apache Flink Datastream ou Table. Avec le service géré pour Apache Flink Studio, vous pouvez interroger des flux de données de manière interactive en temps réel et créer et exécuter facilement des applications de traitement de flux à l'aide de SQL, Python et Scala standard.
Vous pouvez sélectionner la méthode qui convient le mieux à votre cas d'utilisation. En cas de doute, cette section propose des conseils de haut niveau pour vous aider.
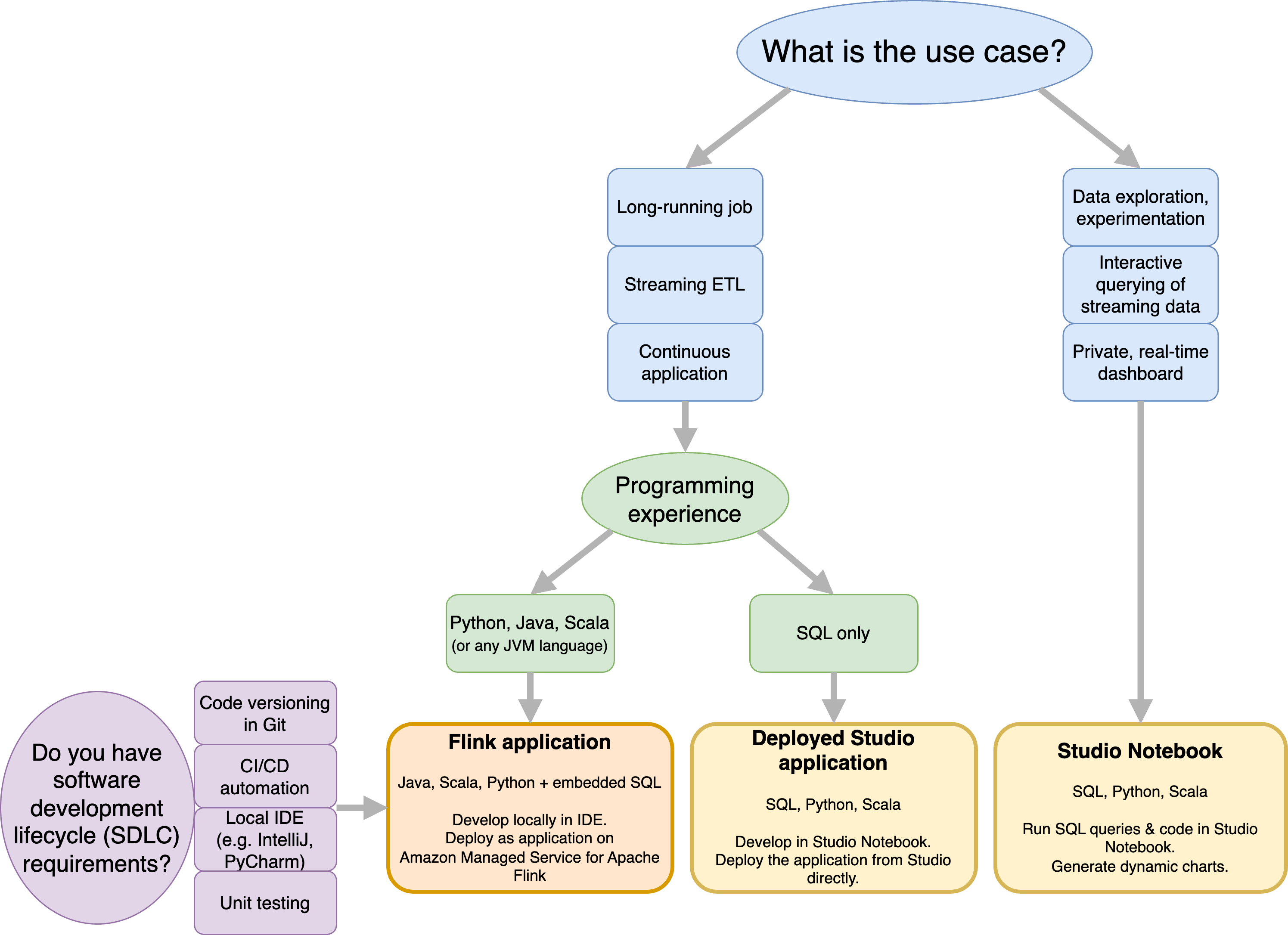
Avant de décider d'utiliser Amazon Managed Service pour Apache Flink ou Amazon Managed Service pour Apache Flink Studio, vous devez prendre en compte votre cas d'utilisation.
Si vous envisagez d'exploiter une application de longue durée qui prendra en charge des charges de travail telles que le streaming ETL ou les applications continues, vous devriez envisager d'utiliser le service géré pour Apache Flink. En effet, vous pouvez créer votre application Flink à l'aide des API Flink directement dans l'IDE de votre choix. Le développement local avec votre IDE vous permet également de tirer parti des processus et outils courants du cycle de vie du développement logiciel (SDLC) tels que le versionnement du code dans Git, l' CI/CD automatisation ou les tests unitaires.
Si vous êtes intéressé par l'exploration de données ad hoc, si vous souhaitez interroger des données de streaming de manière interactive ou créer des tableaux de bord privés en temps réel, le service géré pour Apache Flink Studio vous aidera à atteindre ces objectifs en quelques clics. Les utilisateurs familiarisés avec SQL peuvent envisager de déployer une application de longue durée directement depuis Studio.
Note
Vous pouvez transformer votre bloc-notes Studio en une application de longue durée. Toutefois, si vous souhaitez intégrer vos outils SDLC tels que le versionnement du code sur Git et l' CI/CD automatisation, ou des techniques telles que les tests unitaires, nous vous recommandons d'utiliser le service géré pour Apache Flink en utilisant l'IDE de votre choix.
Choisissez les API Apache Flink à utiliser dans le service géré pour Apache Flink
Vous pouvez créer des applications à l'aide de Java, Python et Scala dans Managed Service pour Apache Flink à l'aide des API Apache Flink dans l'IDE de votre choix. Vous trouverez des conseils sur la façon de créer des applications à l'aide de Flink Datastream et de l'API Table dans la documentation. Vous pouvez sélectionner la langue dans laquelle vous créez votre application Flink et les API que vous utilisez pour répondre au mieux aux besoins de votre application et de vos opérations. En cas de doute, cette section fournit des conseils de haut niveau pour vous aider.
Choisissez une API Flink
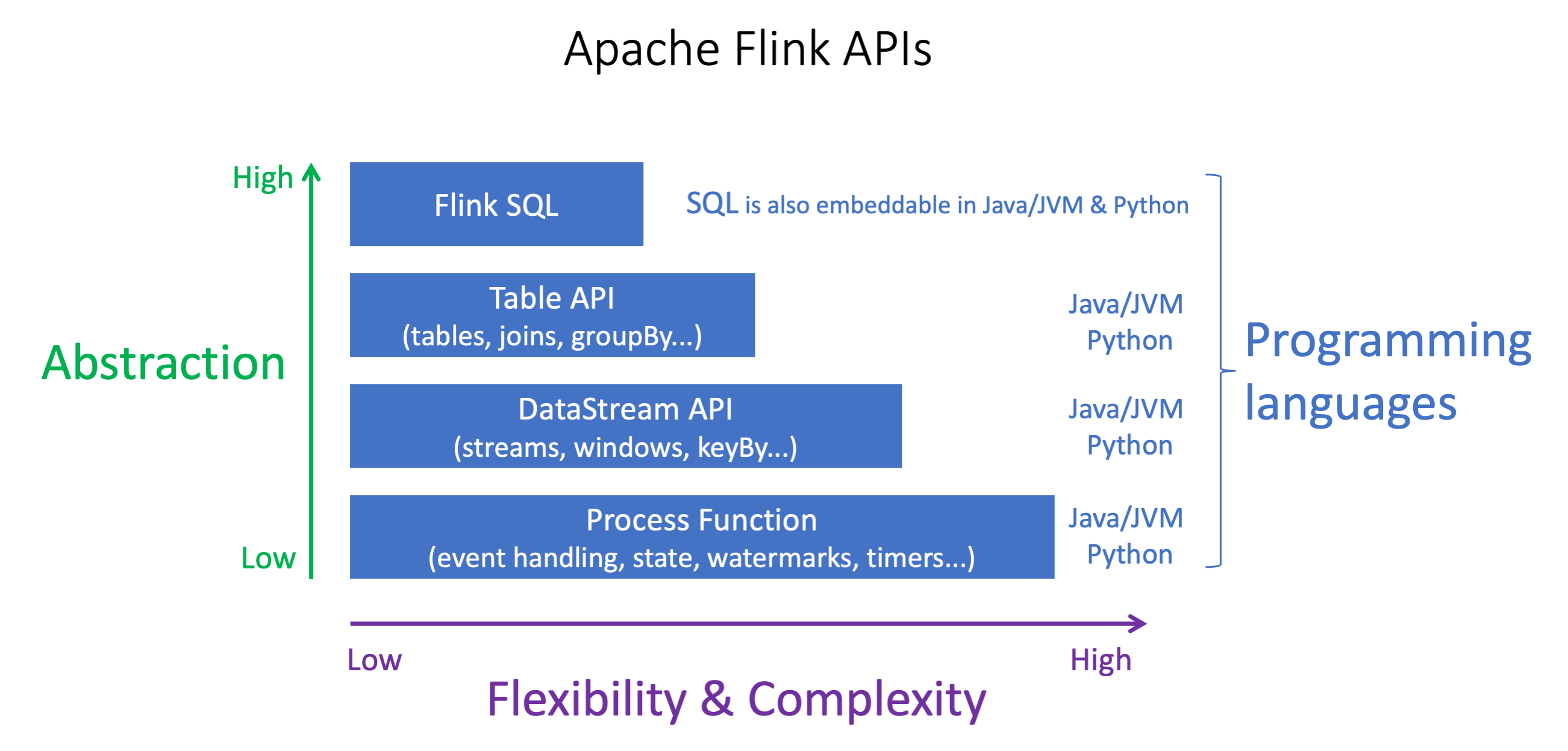
Les API Apache Flink ont différents niveaux d'abstraction qui peuvent avoir une incidence sur la façon dont vous décidez de créer votre application. Ils sont expressifs et flexibles et peuvent être utilisés ensemble pour créer votre application. Vous n'êtes pas obligé d'utiliser une seule API Flink. Pour en savoir plus sur les API Flink, consultez la documentation d'Apache Flink
Flink propose quatre niveaux d'abstraction d'API : Flink SQL, Table API, DataStream API et Process Function, qui sont utilisés conjointement avec l' DataStream API. Ils sont tous pris en charge dans Amazon Managed Service pour Apache Flink. Il est conseillé de commencer par un niveau d'abstraction plus élevé lorsque cela est possible, mais certaines fonctionnalités de Flink ne sont disponibles qu'avec l'API Datastream, où vous pouvez créer votre application en Java, Python ou Scala. Vous devriez envisager d'utiliser l'API Datastream si :
Vous avez besoin d'un contrôle précis de l'État
Vous souhaitez tirer parti de la possibilité d'appeler une base de données externe ou un point de terminaison de manière asynchrone (par exemple pour l'inférence)
Vous souhaitez utiliser des minuteries personnalisées (par exemple pour implémenter un fenêtrage personnalisé ou une gestion des événements tardifs)
-
Vous souhaitez pouvoir modifier le flux de votre application sans réinitialiser l'état
Note
Choix d'une langue avec l'DataStreamAPI :
Le SQL peut être intégré dans n'importe quelle application Flink, quel que soit le langage de programmation choisi.
Si vous envisagez d'utiliser l' DataStream API, tous les connecteurs ne sont pas pris en charge en Python.
Si vous avez besoin d'un faible latency/high débit, vous devez envisager Java/Scala quelle que soit l'API.
Si vous envisagez d'utiliser Async IO dans l'API Process Functions, vous devez utiliser Java.
Le choix de l'API peut également avoir un impact sur votre capacité à faire évoluer la logique de l'application sans avoir à réinitialiser l'état. Cela dépend d'une fonctionnalité spécifique, la possibilité de définir un UID sur les opérateurs, qui n'est disponible que dans l'DataStreamAPI pour Java et Python. Pour plus d'informations, consultez la section Définir les UUID pour tous les opérateurs
Commencez avec les applications de streaming de données
Vous pouvez commencer par créer une application de service géré pour Apache Flink qui lit et traite en continu les données en streaming. Créez ensuite votre code à l’aide de l’IDE de votre choix et testez-le avec des données de diffusion en direct. Vous pouvez également configurer des destinations où vous voulez que le service géré pour Apache Flink envoie les résultats.
Nous vous recommandons de commencer par lire les sections suivantes :
Vous pouvez également commencer par créer un service géré pour le bloc-notes Apache Flink Studio qui vous permet d'interroger des flux de données de manière interactive en temps réel, et de créer et d'exécuter facilement des applications de traitement de flux à l'aide de SQL, Python et Scala standard. En quelques clics Console de gestion AWS, vous pouvez lancer un bloc-notes sans serveur pour interroger des flux de données et obtenir des résultats en quelques secondes. Nous vous recommandons de commencer par lire les sections suivantes :
