Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Minimiser les frais de planification
Comme indiqué dans les rubriques clés d'Apache Spark, le pilote Spark génère le plan d'exécution. Sur la base de ce plan, les tâches sont attribuées à l'exécuteur Spark pour un traitement distribué. Cependant, le pilote Spark peut devenir un goulot d'étranglement s'il AWS Glue Data Catalog contient un grand nombre de petits fichiers ou un grand nombre de partitions. Pour identifier les frais de planification élevés, évaluez les indicateurs suivants.
CloudWatch métriques
Vérifiez la CPUcharge et l'utilisation de la mémoire dans les situations suivantes :
-
La CPUcharge du pilote Spark et l'utilisation de la mémoire sont enregistrées comme étant élevées. Normalement, le pilote Spark ne traite pas vos données, de sorte que la CPU charge et l'utilisation de la mémoire n'augmentent pas. Toutefois, si la source de données Amazon S3 contient trop de petits fichiers, la liste de tous les objets S3 et la gestion d'un grand nombre de tâches peuvent entraîner une utilisation élevée des ressources.
-
Il y a un long intervalle avant le début du traitement dans l'exécuteur Spark. Dans l'exemple de capture d'écran suivant, la CPU charge de l'exécuteur Spark est trop faible avant 10 h 57, même si le AWS Glue travail a débuté à 10 h 00. Cela indique que le pilote Spark met peut-être beaucoup de temps à générer un plan d'exécution. Dans cet exemple, récupérer le grand nombre de partitions du catalogue de données et répertorier le grand nombre de petits fichiers dans le pilote Spark prend du temps.
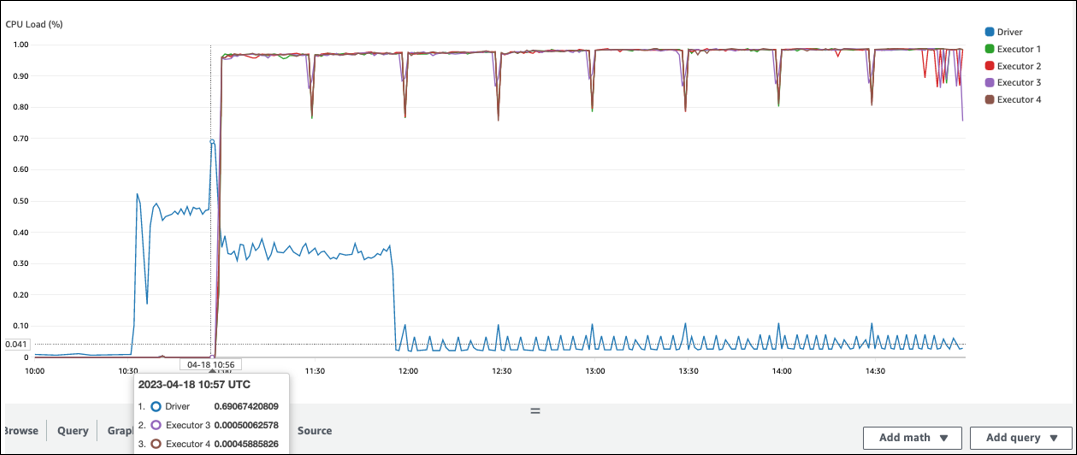
Interface utilisateur Spark
Dans l'onglet Job de l'interface utilisateur de Spark, vous pouvez voir l'heure de soumission. Dans l'exemple suivant, le pilote Spark a démarré job0 à 10:56:46, même si le job a débuté à 10:00:00. AWS Glue

Vous pouvez également voir les tâches (pour toutes les étapes) : Réussité/Durée totale dans l'onglet Job. Dans ce cas, le nombre de tâches est enregistré sous la forme58100. Comme expliqué dans la section Amazon S3 de la page des tâches de parallélisation, le nombre de tâches correspond approximativement au nombre d'objets S3. Cela signifie qu'il y a environ 58 100 objets dans Amazon S3.
Pour plus de détails sur cette tâche et son calendrier, consultez l'onglet Étape. Si vous observez un goulot d'étranglement avec le pilote Spark, envisagez les solutions suivantes :
-
Lorsque Amazon S3 contient trop de fichiers, consultez les instructions relatives au parallélisme excessif dans la section Trop de partitions de la page des tâches de parallélisation.
-
Lorsque le nombre de partitions d'Amazon S3 est trop élevé, consultez les instructions relatives au partitionnement excessif figurant dans la section Trop de partitions Amazon S3 de la page Réduire la quantité de données numérisées. Activez les index de AWS Glue partition s'il existe de nombreuses partitions afin de réduire le temps de latence lors de la récupération des métadonnées des partitions à partir du catalogue de données. Pour plus d'informations, voir Améliorer les performances des requêtes à l'aide des index de AWS Glue partition
. -
Si JDBC le nombre de partitions est trop élevé, réduisez la
hashpartitionvaleur. -
Lorsque DynamoDB possède un trop grand nombre de partitions, réduisez la valeur.
dynamodb.splits -
Lorsque les tâches de streaming comportent trop de partitions, réduisez le nombre de partitions.
