Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Siklus hidup insiden di Manajer Insiden
Manajer Insiden AWS Systems Manager menyediakan step-by-step kerangka kerja berdasarkan praktik terbaik untuk mengidentifikasi dan bereaksi terhadap insiden, seperti pemadaman layanan atau ancaman keamanan. Fokus utama Manajer Insiden adalah membantu memulihkan layanan atau aplikasi yang terpengaruh ke normal secepat mungkin melalui solusi manajemen siklus hidup insiden yang lengkap.
Seperti yang digambarkan dalam ilustrasi berikut, Manajer Insiden menyediakan alat dan praktik terbaik untuk setiap fase siklus hidup insiden:
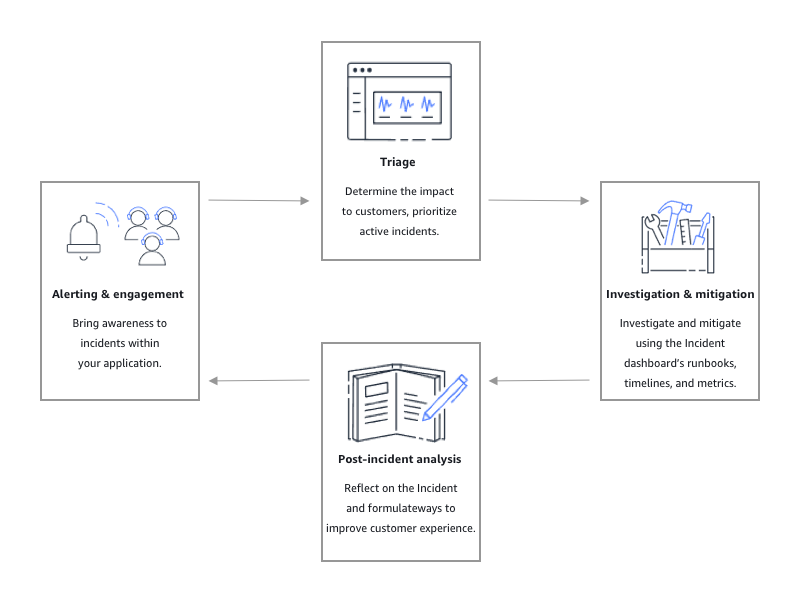
Peringatan dan keterlibatan
Fase peringatan dan keterlibatan dari siklus hidup insiden berfokus pada kesadaran akan insiden dalam aplikasi dan layanan Anda. Fase ini dimulai sebelum insiden terdeteksi dan membutuhkan pemahaman mendalam tentang aplikasi Anda. Anda dapat menggunakan CloudWatchmetrik Amazon untuk memantau data tentang kinerja aplikasi Anda, atau menggunakan Amazon EventBridge untuk mengumpulkan peringatan dari berbagai sumber, aplikasi, dan layanan. Setelah menyiapkan pemantauan untuk aplikasi Anda, Anda dapat mulai memberi tahu metrik yang menyimpang di luar norma historis. Untuk mempelajari lebih lanjut tentang memantau praktik terbaik, lihatPemantauan.
Untuk mendukung diagnosis insiden responden, Anda dapat mengaktifkan fitur Temuan di Manajer Insiden. Temuan adalah informasi tentang AWS CodeDeploy penyebaran dan pembaruan AWS CloudFormation tumpukan yang terjadi sekitar waktu insiden. Memiliki informasi ini mengurangi waktu yang dibutuhkan untuk mengevaluasi penyebab potensial, yang dapat mengurangi waktu rata-rata untuk memulihkan (MTTR) dari suatu insiden.
Sekarang setelah Anda memantau insiden dalam aplikasi Anda, Anda dapat menentukan rencana respons insiden yang akan digunakan selama insiden. Untuk mempelajari lebih lanjut tentang membuat rencana respons, lihatMembuat dan mengonfigurasi rencana respons di Manajer Insiden. EventBridge Acara Amazon atau CloudWatch Alarm dapat secara otomatis membuat insiden menggunakan paket respons sebagai templat. Untuk mempelajari lebih lanjut tentang penciptaan insiden, lihatMembuat insiden secara otomatis atau manual di Manajer Insiden.
Rencana respons meluncurkan rencana eskalasi terkait dan rencana keterlibatan untuk membawa responden pertama ke dalam insiden tersebut. Untuk informasi selengkapnya tentang menyiapkan rencana eskalasi, lihatBuat rencana eskalasi. Secara bersamaan, AWS Chatbot memberi tahu responden menggunakan saluran obrolan yang mengarahkan mereka ke halaman detail insiden. Dengan menggunakan saluran obrolan dan detail insiden, tim dapat berkomunikasi dan melakukan triase insiden. Untuk informasi selengkapnya tentang menyiapkan saluran obrolan di Manajer Insiden, lihatTugas 2: Buat saluran obrolan di AWS Chatbot.
Triase
Triase adalah ketika responden pertama mencoba untuk menentukan dampaknya terhadap pelanggan. Tampilan detail insiden di konsol Manajer Insiden memberi responden jadwal dan metrik untuk membantu mereka menilai insiden tersebut. Menilai dampak dari suatu insiden juga meletakkan dasar untuk waktu respons, resolusi, dan komunikasi untuk insiden tersebut. Responden memprioritaskan insiden dengan menggunakan peringkat dampak dari 1 (Kritis) hingga 5 (Tanpa Dampak).
Organisasi Anda dapat menentukan cakupan yang tepat dari setiap peringkat dampak sesuai pilihan Anda. Tabel berikut memberikan contoh bagaimana setiap tingkat dampak biasanya dapat didefinisikan.
| Kode dampak | Nama dampak | Sampel ruang lingkup yang ditentukan |
|---|---|---|
1 |
Critical |
Kegagalan aplikasi penuh yang berdampak pada sebagian besar pelanggan. |
2 |
High |
Kegagalan aplikasi penuh yang berdampak pada sebagian pelanggan. |
3 |
Medium |
Kegagalan aplikasi sebagian yang berdampak pada pelanggan. |
4 |
Low |
Kegagalan intermiten yang berdampak terbatas pada pelanggan. |
5 |
No Impact |
Pelanggan saat ini tidak terpengaruh tetapi tindakan mendesak diperlukan untuk menghindari dampak. |
Investigasi dan mitigasi
Tampilan detail insiden memberi tim Anda runbook, garis waktu, dan metrik. Untuk melihat bagaimana Anda dapat bekerja dengan suatu insiden, lihatMelihat detail insiden di konsol.
Runbook biasanya menyediakan langkah-langkah investigasi dan dapat secara otomatis menarik data atau mencoba solusi yang umum digunakan. Runbook juga memberikan langkah-langkah yang jelas dan berulang yang menurut tim Anda berguna dalam mengurangi insiden. Tab runbook berfokus pada langkah runbook saat ini dan menunjukkan langkah masa lalu dan masa depan.
Incident Manager terintegrasi dengan Systems Manager Automation untuk membangun runbook. Gunakan runbook untuk melakukan salah satu hal berikut:
-
Mengelola contoh dan sumber daya AWS
-
Jalankan skrip secara otomatis
-
Kelola AWS CloudFormation sumber daya
Untuk informasi selengkapnya tentang jenis tindakan yang didukung, lihat referensi tindakan Otomasi Systems Manager di Panduan AWS Systems Manager Pengguna.
Tab Timeline menunjukkan tindakan apa yang telah diambil. Timeline mencatat masing-masing dengan stempel waktu dan detail yang dibuat secara otomatis. Untuk menambahkan peristiwa khusus ke timeline, lihat Garis Waktu bagian di halaman Detail insiden di panduan pengguna ini.
Tab Diagnosis menampilkan metrik yang diisi secara otomatis dan metrik yang ditambahkan secara manual. Pandangan ini memberikan informasi berharga tentang aktivitas aplikasi Anda selama insiden.
Tab Keterlibatan memungkinkan Anda menambahkan kontak tambahan ke insiden tersebut dan membantu menyediakan sumber daya bagi kontak yang terlibat untuk mempercepat dengan cepat setelah terlibat dalam insiden tersebut. Kontak terlibat melalui rencana eskalasi yang ditentukan atau rencana keterlibatan pribadi.
Menggunakan saluran obrolan, Anda dapat langsung berinteraksi dengan insiden Anda dan responden lain di tim Anda. Dengan menggunakan AWS Chatbot, Anda dapat mengonfigurasi saluran obrolan di. Slack, Microsoft Teams, dan Amazon Chime. Masuk Slack and Microsoft Teams saluran, responden dapat berinteraksi dengan insiden langsung dari saluran obrolan menggunakan sejumlah perintah. ssm-incidents Untuk informasi selengkapnya, lihat Berinteraksi melalui saluran obrolan.
Analisis pasca-insiden
Incident Manager menyediakan kerangka kerja untuk merefleksikan insiden, mengambil langkah-langkah yang diperlukan untuk mencegah insiden terjadi lagi di masa depan, dan untuk meningkatkan aktivitas respons insiden secara keseluruhan. Perbaikan dapat mencakup:
-
Perubahan pada aplikasi yang terlibat dalam suatu insiden. Tim Anda dapat menggunakan waktu ini untuk meningkatkan sistem dan membuatnya lebih toleran terhadap kesalahan.
-
Perubahan pada rencana respons insiden. Luangkan waktu untuk memasukkan pelajaran yang dipelajari.
-
Perubahan pada runbook. Tim Anda dapat menyelam jauh ke dalam langkah-langkah yang diperlukan untuk resolusi dan langkah-langkah yang dapat Anda otomatiskan.
-
Perubahan pada peringatan. Setelah insiden, tim Anda mungkin telah memperhatikan titik-titik penting dalam metrik yang dapat Anda gunakan untuk mengingatkan tim lebih cepat tentang suatu insiden.
Manajer Insiden memfasilitasi peningkatan potensial ini dengan menggunakan serangkaian pertanyaan analisis pasca-insiden dan item tindakan di samping garis waktu insiden. Untuk mempelajari lebih lanjut tentang peningkatan melalui analisis, lihatMenjalankan analisis pasca-insiden di Incident Manager.
