Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Configurare e personalizzare la generazione di query e risposte
È possibile configurare e personalizzare il recupero e la generazione di risposte, migliorando ulteriormente la pertinenza delle risposte stesse. Ad esempio, puoi applicare filtri ai metadati dei documenti fields/attributes per utilizzare i documenti aggiornati più di recente o i documenti con orari di modifica più recenti.
Nota
Tutte le configurazioni seguenti, ad eccezione di orchestrazione e generazione, sono applicabili solo alle origini dati non strutturate.
Per ulteriori informazioni su queste configurazioni nella console o nell’API, seleziona uno dei seguenti argomenti:
Quando si esegue una query su una knowledge base, per impostazione predefinita Amazon Bedrock restituisce fino a cinque risultati nella risposta. Ogni risultato corrisponde a un blocco di origine.
Nota
Il numero effettivo di risultati nella risposta potrebbe essere inferiore al valore numberOfResults specificato, poiché questo parametro imposta il numero massimo di risultati da restituire. Se è stato configurato il chunking semantico per la strategia di chunking, il parametro numberOfResults viene mappato al numero di blocchi figlio recuperati dalla knowledge base. Poiché i blocchi figlio che condividono lo stesso blocco padre vengono sostituiti con il blocco padre nella risposta finale, il numero di risultati restituiti potrebbe essere inferiore alla quantità richiesta.
Per modificare il numero massimo di risultati da restituire, scegli la scheda relativa al metodo che preferisci, quindi segui la procedura:
Il tipo di ricerca definisce il modo in cui vengono eseguite le query sulle origini dati nella knowledge base. I tipi di ricerca possibili sono i seguenti:
Nota
La ricerca ibrida è supportata solo per gli archivi vettoriali Amazon RDS, Amazon OpenSearch Serverless e MongoDB che contengono un campo di testo filtrabile. Se si utilizza un archivio vettoriale diverso o l’archivio vettoriale in uso non contiene un campo di testo filtrabile, la query utilizza la ricerca semantica.
-
Predefinito: Amazon Bedrock decide automaticamente la strategia di ricerca.
-
Ibrido: la ricerca di embedding vettoriali (ricerca semantica) viene combinata con la ricerca nel testo non elaborato.
-
Semantico: vengono cercati solo gli embedding vettoriali.
Per informazioni sulla definizione del tipo di ricerca, scegli la scheda relativa al metodo che preferisci, quindi segui la procedura:
Puoi applicare filtri al documento per aiutarti fields/attributes a migliorare ulteriormente la pertinenza delle risposte. Le tue fonti di dati possono includere metadati di documenti su cui attributes/fields filtrare e specificare quali campi includere negli incorporamenti.
Considerazioni sulla Knowledge Base gestita
Quando si utilizza il filtraggio dei metadati con una knowledge base gestita:
-
I filtri
startsWithestringContainsi metadati non sono supportati. UtilizzateequalsinvecenotIngli operatorigreaterThanlessThanin,,, o. -
Per le knowledge base personalizzate, i campi di metadati con il prefisso
x-amz-bedrocksono riservati dal servizio. Per le knowledge base completamente gestite, i campi di metadati riservati utilizzano un prefisso di sottolineatura (ad esempio,)._source_uri_data_source_idNon è possibile sovrascrivere i campi di metadati riservati in entrambi i tipi di knowledge base.
Ad esempio, “epoch_modification_time” rappresenta il tempo in numero di secondi dal 1° gennaio 1970 (UTC), data dell’ultimo aggiornamento del documento. È possibile filtrare in base ai dati più recenti, in cui “epoch_modification_time” è maggiore di un determinato numero. I documenti più recenti possono essere utilizzati per la query.
Per utilizzare i filtri durante l’esecuzione di query su una knowledge base, verifica che quest’ultima soddisfi i seguenti requisiti:
-
Durante la configurazione del connettore dell’origine dati, la maggior parte dei connettori esegue il crawling dei campi di metadati principali dei documenti. Se si utilizza un bucket Amazon S3 come origine dati, il bucket deve includerne almeno un oggetto
fileName.extension.metadata.jsonper il file o il documento a cui è associato. Per ulteriori informazioni sulla configurazione del file di metadati, consulta Campi dei metadati dei documenti in Configurazione della connessione. -
Se l'indice vettoriale della tua knowledge base si trova in un archivio vettoriale Amazon OpenSearch Serverless, verifica che l'indice vettoriale sia configurato con il motore.
faissSe l’indice vettoriale è configurato con il motorenmslib, eseguire una delle seguenti operazioni:-
Crea una nuova knowledge base nella console e consenti ad Amazon Bedrock di creare automaticamente un indice vettoriale in Amazon OpenSearch Serverless per te.
-
Crea un altro indice vettoriale nell’archivio vettoriale e seleziona
faisscome motore. Crea una nuova knowledge base e specifica il nuovo indice vettoriale.
-
-
Se la knowledge base utilizza un indice vettoriale in un bucket vettoriale S3, non è possibile utilizzare i filtri
startsWithestringContains. -
Se si aggiungono metadati a un indice vettoriale esistente in un cluster di database Amazon Aurora, si consiglia di fornire il nome del campo della colonna di metadati personalizzata per archiviare tutti i metadati in un’unica colonna. Durante l’importazione dei dati, questa colonna verrà utilizzata per popolare tutte le informazioni contenute nei file di metadati delle origini dati. Se si sceglie di fornire questo campo, è necessario creare un indice sulla colonna.
-
Quando si crea una nuova knowledge base nella console e si consente ad Amazon Bedrock di configurare il database Amazon Aurora, viene creata automaticamente una singola colonna popolata con le informazioni contenute nel file di metadati.
-
Quando si sceglie di creare un altro indice vettoriale nell’archivio vettoriale, è necessario fornire il nome del campo di metadati personalizzato per archiviare le informazioni contenute nel file di metadati. Se non si fornisce questo nome campo, è possibile creare una colonna per ogni attributo di metadati nei file e specificare il tipo di dati (testo, numero o booleano). Ad esempio, se l’attributo
genreesiste nell’origine dati, è necessario aggiungere una colonna denominatagenree specificaretextcome tipo di dati. Durante l’importazione, queste colonne separate vengono popolate con i valori degli attributi corrispondenti.
-
Se hai documenti PDF nella tua fonte di dati e utilizzi Amazon OpenSearch Serverless o Amazon Aurora per il tuo archivio vettoriale: le knowledge base di Amazon Bedrock genereranno i numeri di pagina dei documenti e li memorizzeranno in un metadato chiamato x-amz-bedrock-kb-document-page-number. field/attribute Tenere presente che i numeri di pagina archiviati in un campo di metadati non sono supportati qualora si scelga di non applicare il chunking per i documenti.
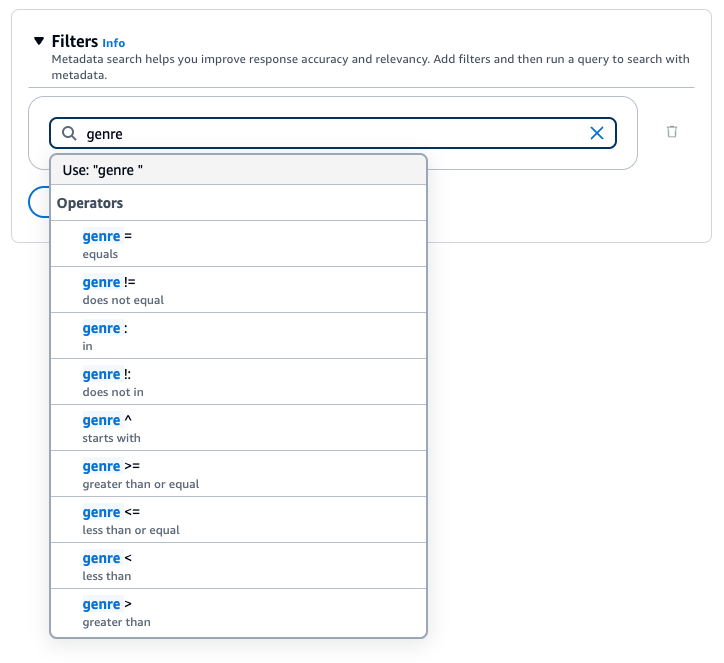
Per filtrare i risultati delle query, è possibile utilizzare i seguenti operatori di filtro:
| Operatore | Console | Nome del filtro API | Tipi di dati degli attributi supportati | Risultati filtrati |
|---|---|---|---|---|
| Equals | = | equals | stringa, numero, valore booleano | L’attributo corrisponde al valore fornito |
| Not equals | != | notEquals | stringa, numero, valore booleano | L’attributo non corrisponde al valore fornito |
| Greater than | > | Maggiore di | numero | L’attributo è maggiore del valore fornito |
| Greater than or equals | >= | maggiore ThanOrEquals | numero | L’attributo è maggiore del o uguale al valore fornito |
| Less than | < | Meno di | numero | L’attributo è minore del valore fornito |
| Less than or equals | <= | meno ThanOrEquals | numero | L’attributo è minore del o uguale al valore fornito |
| In | : | in | elenco di stringhe | L'attributo è nell'elenco fornito (attualmente è meglio supportato con gli archivi vettoriali GraphRag di Amazon OpenSearch Serverless e Neptune Analytics) |
| Non in | !: | notIn | elenco di stringhe | L'attributo non è nell'elenco fornito (attualmente è meglio supportato con gli archivi vettoriali GraphRag di Amazon OpenSearch Serverless e Neptune Analytics) |
| String contains | Non disponibile | stringContains | stringa | L’attributo deve essere una stringa. Il nome dell'attributo corrisponde alla chiave e il cui valore è una stringa che contiene il valore che hai fornito come sottostringa o un elenco con un membro che contiene il valore che hai fornito come sottostringa (attualmente è meglio supportato con Amazon OpenSearch Serverless vector store). L'archivio vettoriale GraphRag di Neptune Analytics supporta la variante string (ma non la variante list di questo filtro). |
| List contains | Non disponibile | listContains | stringa | L’attributo deve essere un elenco di stringhe. Il nome dell'attributo corrisponde alla chiave e il cui valore è un elenco che contiene il valore che hai fornito come uno dei suoi membri (attualmente è meglio supportato con Amazon OpenSearch Serverless vector stores). |
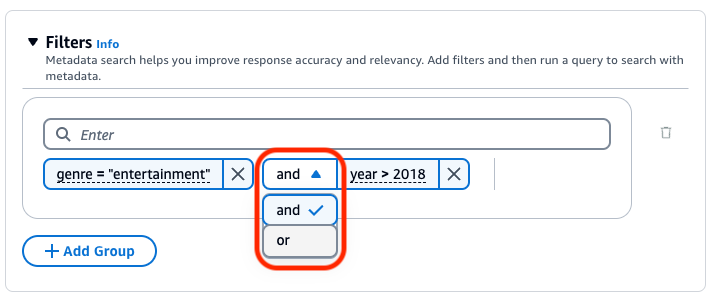
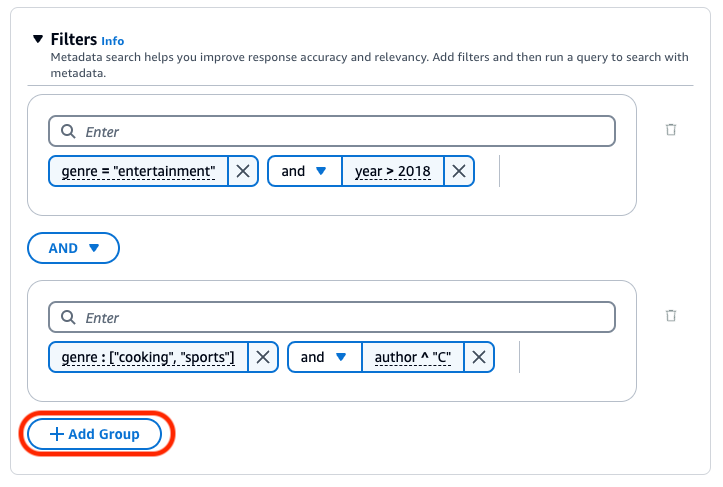
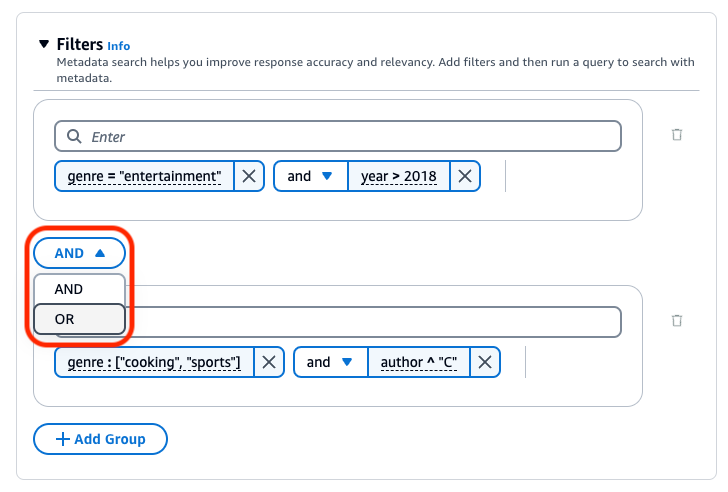
Per combinare gli operatori di filtro, è possibile utilizzare i seguenti operatori logici:
Per informazioni su come filtrare i risultati utilizzando i metadati, scegli la scheda relativa al metodo che preferisci, quindi segui la procedura:

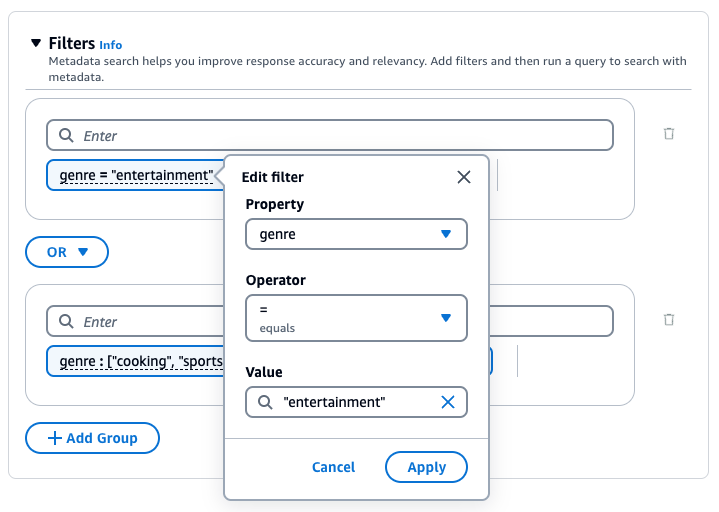
Knowledge Base per Amazon Bedrock genera e applica un filtro di recupero basato sulla query dell’utente e su uno schema di metadati.
Nota
Il filtraggio implicito dei metadati è supportato dai modelli. Anthropic Claude Per ulteriori informazioni sui modelli supportati, consulta la sezione Modelli a colpo d'occhio.
L’elemento implicitFilterConfiguration è specificato nell’oggetto vectorSearchConfiguration del corpo della richiesta Retrieve. Include i seguenti campi:
-
metadataAttributes: in questo array, fornisci gli schemi che descrivono gli attributi dei metadati per cui il modello genererà un filtro. -
modelArn: ARN del modello da utilizzare.
Di seguito viene mostrato un esempio di schemi di metadati che è possibile aggiungere all’array in metadataAttributes.
[ { "key": "company", "type": "STRING", "description": "The full name of the company. E.g. `Amazon.com, Inc.`, `Alphabet Inc.`, etc" }, { "key": "ticker", "type": "STRING", "description": "The ticker name of a company in the stock market, e.g. AMZN, AAPL" }, { "key": "pe_ratio", "type": "NUMBER", "description": "The price to earning ratio of the company. This is a measure of valuation of a company. The lower the pe ratio, the company stock is considered chearper." }, { "key": "is_us_company", "type": "BOOLEAN", "description": "Indicates whether the company is a US company." }, { "key": "tags", "type": "STRING_LIST", "description": "Tags of the company, indicating its main business. E.g. `E-commerce`, `Search engine`, `Artificial intelligence`, `Cloud computing`, etc" } ]
È possibile implementare protezioni per la knowledge base per i casi d’uso specifici e le policy di IA responsabile. Si possono creare più guardrail su misura per diversi casi d’uso e applicarli a più condizioni di richiesta e risposta, fornendo un’esperienza utente coerente e standardizzando i controlli di sicurezza nella knowledge base. Si possono anche configurare argomenti da negare per impedire argomenti indesiderati e filtri di contenuto per bloccare contenuti dannosi negli input e nelle risposte dei modelli. Per ulteriori informazioni, consulta Rilevare e filtrare contenuti dannosi utilizzando Guardrail per Amazon Bedrock.
Nota
L’uso di guardrail con correlazione contestuale per knowledge base non è attualmente supportato in Claude 3 Sonnet e Haiku.
Per linee guida generali sulla progettazione dei prompt, consulta Concetti di progettazione dei prompt.
Scegli la scheda relativa al metodo che preferisci, quindi segui la procedura:
È possibile utilizzare un modello di riclassificazione per riclassificare i risultati delle query della knowledge base. Segui i passaggi per la console indicati in Interrogare una knowledge base e recuperare dei dati o in Interrogare una knowledge base e generare risposte basate sui dati recuperati. Quando apri il riquadro Configurazioni, espandi la sezione Riclassificazione. Seleziona un modello di riclassificazione, aggiorna le autorizzazioni, se necessario e modifica eventuali opzioni aggiuntive. Immetti un prompt e seleziona Esegui per testare i risultati dopo la riclassificazione.
La scomposizione delle query è una tecnica utilizzata per suddividere query complesse in sottoquery più piccole e più gestibili. Questo approccio consente di recuperare informazioni più precise e pertinenti, soprattutto quando la query iniziale è complessa o troppo ampia. L’attivazione di questa opzione può comportare l’esecuzione di più query sulla knowledge base e di conseguenza può contribuire a una risposta finale più accurata.
Ad esempio, per una domanda come «Chi ha ottenuto il punteggio più alto nella Coppa del Mondo FIFA 2022, in Argentina o in Francia?» , le knowledge base di Amazon Bedrock possono generare innanzitutto le seguenti sottoquery, prima di generare una risposta finale:
-
Quanti gol ha segnato l’Argentina nella finale della Coppa del Mondo FIFA 2022?
-
Quanti gol ha segnato la Francia nella finale della Coppa del Mondo FIFA 2022?
Quando si generano risposte basate sul recupero di informazioni, è possibile utilizzare i parametri di inferenza per ottenere un maggiore controllo sul comportamento del modello durante l’inferenza e per influenzare i risultati del modello.
Per informazioni sulla modifica dei parametri di inferenza, scegli la scheda relativa al metodo che preferisci, quindi segui la procedura:
Quando si eseguono query su una knowledge base e si richiede la generazione della risposta, Amazon Bedrock utilizza un modello di prompt che abbina istruzioni, informazioni recuperate e contesto alla query dell’utente per creare il prompt inviato al modello per la generazione della risposta. È anche possibile personalizzare il prompt di orchestrazione, che trasforma il prompt dell’utente in una query di ricerca. Per progettare i modelli di prompt, utilizza gli strumenti seguenti:
-
Segnaposti rapidi: variabili Pre-defined nelle Knowledge Base di Amazon Bedrock che vengono compilate dinamicamente in fase di esecuzione durante l'interrogazione della knowledge base. Nel prompt di sistema, i segnaposto circondati dal simbolo
$. Nell’elenco seguente vengono descritti i segnaposto che è possibile utilizzare:Nota
Il segnaposto
$output_format_instructions$è un campo obbligatorio per le citazioni da visualizzare nella risposta.Variabile Modello di prompt Sostituita da Modello Obbligatorio? $query$ Orchestrazione, generazione Query dell’utente inviata alla knowledge base. Anthropic Claude Instant, Anthropic Claude v2.x Sì Anthropic Claude 3 Sonnet No (incluso automaticamente nell’input del modello) $search_results$ Generazione Risultati recuperati per la query dell’utente. Tutti Sì $output_format_instructions$ Orchestrazione Istruzioni di base per la formattazione della generazione di risposte e delle citazioni. Differisce in base al modello. Se si definiscono le istruzioni di formattazione, si consiglia di rimuovere questo segnaposto. Senza il segnaposto, la risposta non contiene citazioni. Tutti Sì $current_time$ Orchestrazione, generazione Ora corrente. Tutti No -
Tag XML: i modelli Anthropic supportano l’uso di tag XML per strutturare e delineare i prompt. Utilizza nomi di tag descrittivi per risultati ottimali. Ad esempio, nel prompt di sistema predefinito, il tag
<database>viene utilizzato per delineare un database di domande poste in precedenza. Per ulteriori informazioni, consulta Utilizzare i tag XMLnella Guida per l’utente di Anthropic .
Per linee guida generali sulla progettazione dei prompt, consulta Concetti di progettazione dei prompt.
Nota
Quando non fornisci un modello di prompt personalizzato, Amazon Bedrock utilizza un prompt di sistema predefinito che include contenuti di esempio generici (come domande e risposte di esempio su argomenti non correlati) per guidare la formattazione delle risposte del modello. Questo prompt predefinito è visibile nei log di invocazione del modello. Il contenuto di esempio nel prompt predefinito non proviene dai dati di altri clienti, ma è un modello statico fornito da Amazon Bedrock. Puoi sovrascrivere il prompt predefinito specificandone uno personalizzato. textPromptTemplate
Scegli la scheda relativa al metodo che preferisci, quindi segui la procedura:
