Strumento di gestione degli incidenti AWS Systems Manager non è più aperto a nuovi clienti. I clienti esistenti possono continuare a utilizzare il servizio normalmente. Per ulteriori informazioni, vedi modifica della Strumento di gestione degli incidenti AWS Systems Manager disponibilità.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Preparazione agli incidenti in Incident Manager
La pianificazione di un incidente inizia molto prima del ciclo di vita dell'incidente. Come illustrato nella figura seguente, prima di iniziare a rispondere agli incidenti, è necessario prepararsi impostando i canali di chat, creando piani di escalation, specificando i contatti e determinando i runbook di automazione da utilizzare nella risposta agli incidenti. Quindi, utilizzate un piano di risposta che specifichi come avviene il monitoraggio e se le risposte sono automatizzate. Una volta completata la riparazione, è possibile analizzare l'incidente e la risposta all'incidente per affinare ulteriormente il piano di risposta per gli incidenti futuri.
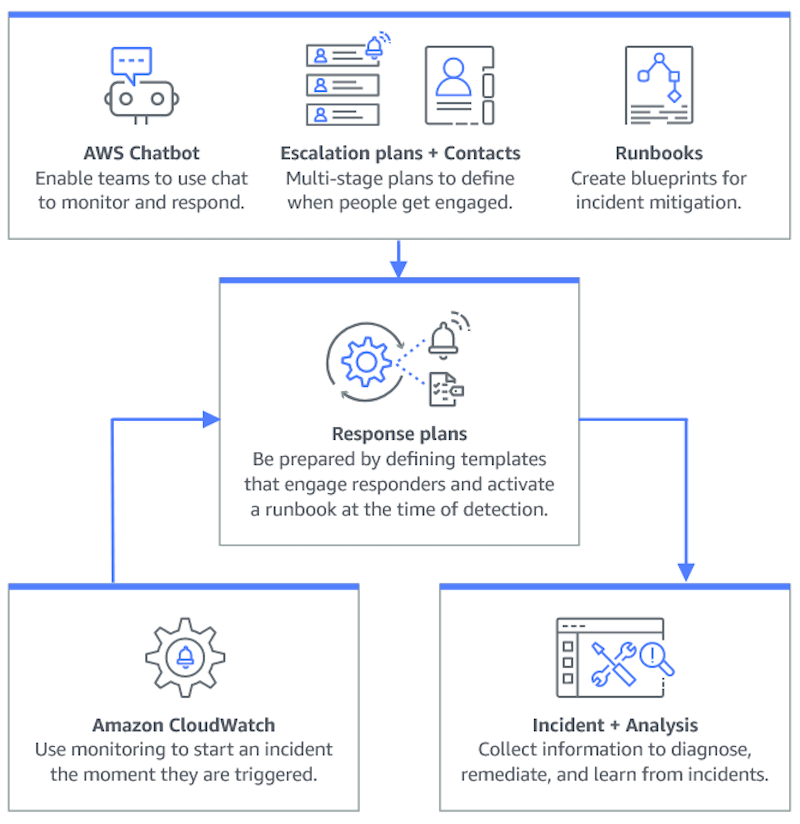
Argomenti
Configurazione dei set di replica e dei risultati in Incident Manager
Gestione delle rotazioni dei soccorritori con pianificazioni di chiamata in Incident Manager
Creazione di un piano di intensificazione per il coinvolgimento dei soccorritori in Incident Manager
Creazione e integrazione di canali di chat per i soccorritori in Incident Manager
Creazione e configurazione dei piani di risposta in Incident Manager
Monitoraggio
Il monitoraggio dello stato delle applicazioni AWS ospitate è fondamentale per garantire l'operatività e le prestazioni delle applicazioni. Nel determinare le soluzioni di monitoraggio, tenete presente quanto segue:
-
Criticità della funzionalità: in caso di guasto del sistema, quanto sarebbe importante l'impatto sugli utenti a valle.
-
Punti comuni di errore: con quale frequenza si verifica un guasto del sistema; i sistemi che richiedono un intervento frequente devono essere monitorati attentamente.
-
Aumento della latenza: quanto è aumentato o diminuito il tempo necessario per completare un'attività.
-
Metriche lato client e lato server: se esiste una discrepanza tra le metriche correlate sul client e sul server.
-
Errori legati alle dipendenze: errori a cui il team può e deve prepararsi.
Dopo aver creato i piani di risposta, puoi utilizzare le tue soluzioni di monitoraggio per tracciare automaticamente gli incidenti nel momento in cui si verificano nel tuo ambiente. Per ulteriori informazioni sul tracciamento e la creazione degli incidenti, vedereVisualizzazione dei dettagli dell'incidente nella console Incident Manager.
