Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Riduci al minimo i costi di pianificazione
Come discusso Argomenti chiave di Apache Spark, il driver Spark genera il piano di esecuzione. In base a tale piano, le attività vengono assegnate all'esecutore Spark per l'elaborazione distribuita. Tuttavia, il driver Spark può diventare un collo di bottiglia se è presente un gran numero di file di piccole dimensioni o se AWS Glue Data Catalog contiene un gran numero di partizioni. Per identificare un sovraccarico di pianificazione elevato, valuta le seguenti metriche.
CloudWatch metriche
Controlla l'utilizzo CPUdel carico e della memoria per le seguenti situazioni:
-
Il CPUcarico e l'utilizzo della memoria del driver Spark sono registrati come elevati. Normalmente, il driver Spark non elabora i dati, quindi il CPU carico e l'utilizzo della memoria non subiscono picchi. Tuttavia, se l'origine dati di Amazon S3 contiene troppi file di piccole dimensioni, elencare tutti gli oggetti S3 e gestire un gran numero di attività potrebbe causare un utilizzo elevato delle risorse.
-
C'è un lungo intervallo prima che l'elaborazione inizi in Spark Executor. Nella seguente schermata di esempio, il CPU carico dell'esecutore Spark è troppo basso fino alle 10:57, anche se il processo è iniziato alle 10:00. AWS Glue Ciò indica che il driver Spark potrebbe impiegare molto tempo per generare un piano di esecuzione. In questo esempio, recuperare il gran numero di partizioni nel Data Catalog ed elencare il gran numero di file di piccole dimensioni nel driver Spark richiede molto tempo.
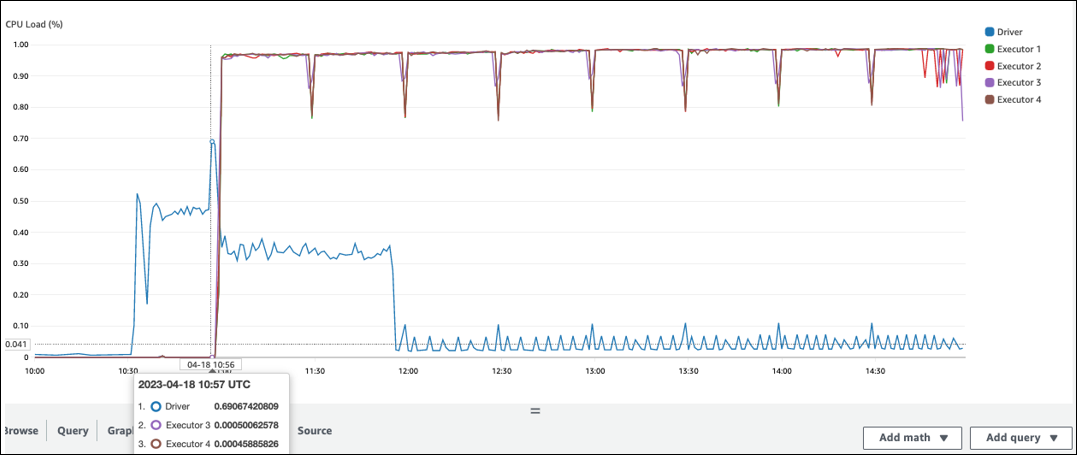
Interfaccia utente di Spark
Nella scheda Job dell'interfaccia utente Spark, puoi vedere l'ora di invio. Nell'esempio seguente, il driver Spark ha avviato job0 alle 10:56:46, anche se il lavoro è iniziato alle 10:00:00. AWS Glue

Puoi anche vedere le Attività (per tutte le fasi): Riuscito/Tempo totale nella scheda Job. In questo caso, il numero di attività viene registrato come. 58100 Come spiegato nella sezione Amazon S3 della pagina delle attività di Parallelize, il numero di attività corrisponde approssimativamente al numero di oggetti S3. Ciò significa che ci sono circa 58.100 oggetti in Amazon S3.
Per maggiori dettagli su questo lavoro e sulla tempistica, consulta la scheda Stage. Se riscontri un problema con il driver Spark, prendi in considerazione le seguenti soluzioni:
-
Quando Amazon S3 ha troppe partizioni, prendi in considerazione le indicazioni sul partizionamento eccessivo nella sezione Troppe partizioni Amazon S3 della pagina Riduci la quantità di scansione dei dati. Abilita gli indici di AWS Glue partizione se ci sono molte partizioni per ridurre la latenza per il recupero dei metadati delle partizioni dal Data Catalog. Per ulteriori informazioni, consulta Migliorare le prestazioni delle query utilizzando gli indici di partizione. AWS Glue
-
Se JDBC ha troppe partizioni, riduci il valore.
hashpartition -
Se DynamoDB ha troppe partizioni, riduci il valore.
dynamodb.splits -
Quando i job di streaming hanno troppe partizioni, riduci il numero di shard.
