Amazon Redshift non supporterà più la creazione di nuove UDF Python a partire dalla Patch 198. Le UDF Python esistenti continueranno a funzionare fino al 30 giugno 2026. Per ulteriori informazioni, consulta il post del blog
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Nozioni di base sui data warehouse Amazon Redshift serverless
Se utilizzi Amazon Redshift Serverless per la prima volta, consigliamo di iniziare leggendo le seguenti sezioni: Il flusso di base di Amazon Redshift serverless consiste nel creare risorse serverless, connettersi ad Amazon Redshift serverless, caricare dati di esempio e quindi eseguire query sui dati. In questa guida, è possibile scegliere di caricare dati di esempio da Amazon Redshift serverless o da un bucket Amazon S3. I dati di esempio vengono utilizzati in tutta la documentazione di Amazon Redshift per illustrare le funzionalità. Per iniziare a utilizzare i data warehouse con provisioning Amazon Redshift, consulta Nozioni di base sui data warehouse con provisioning Amazon Redshift.
Iscriviti per un Account AWS
Per iniziare AWS, hai bisogno di un Account AWS. Per informazioni sulla creazione di un Account AWS, vedi Guida introduttiva a un Account AWS nella Guida Gestione dell’account AWS di riferimento.
Creazione di un data warehouse con Amazon Redshift serverless
La prima volta che accedi alla console Amazon Redshift serverless, viene richiesto di accedere all'esperienza introduttiva, che puoi utilizzare per creare e gestire risorse serverless. In questa guida, creerai risorse serverless utilizzando le impostazioni predefinite di Amazon Redshift serverless.
Per un controllo più granulare della configurazione, scegli Customize settings (Personalizza impostazioni).
Nota
Redshift serverless richiede un VPC Amazon con tre sottoreti in tre zone di disponibilità diverse. Redshift serverless richiede inoltre almeno tre indirizzi IP disponibili. Prima di continuare, assicurati che il VPC Amazon che utilizzi per Redshift serverless abbia tre sottoreti in tre zone di disponibilità diverse e almeno tre indirizzi IP disponibili. Per ulteriori informazioni sulla creazione di sottoreti in un VPC Amazon, consulta Creare una sottorete nella Guida per l’utente di Amazon VPC. Per ulteriori informazioni sugli indirizzi IP in un VPC Amazon, consulta Indirizzamento IP per i VPC e le sottoreti.
Per configurare utilizzando le impostazioni predefinite:
Accedi a AWS Management Console e apri la console Amazon Redshift all'indirizzo. https://console.aws.amazon.com/redshiftv2/
Scegli Prova la versione di prova gratuita di Redshift serverless.
-
In Configuration (Configurazione), scegli Use default settings (Utilizza impostazioni predefinite). Amazon Redshift serverless crea un namespace predefinito a cui è associato un gruppo di lavoro predefinito. Seleziona Save configuration (Salva configurazione).
Nota
Un namespace è una raccolta di oggetti di database e utenti. I namespace raggruppano tutte le risorse utilizzate in Amazon Redshift serverless, come schemi, tabelle, utenti, unità di condivisione dati e snapshot.
Un gruppo di lavoro è una raccolta di risorse di calcolo. I gruppi di lavoro includono le risorse di calcolo utilizzate da Amazon Redshift serverless per eseguire attività di calcolo.
La schermata seguente mostra le impostazioni predefinite per Amazon Redshift Serverless.
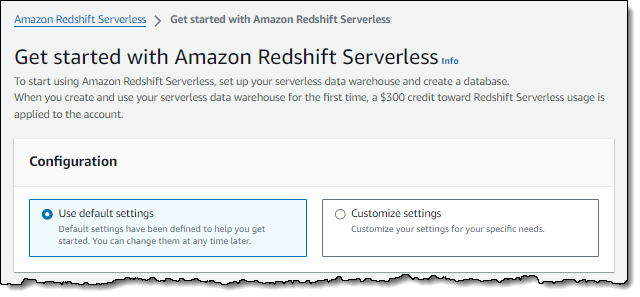
-
Una volta completata la configurazione, scegliere Continue (Continua) per andare a Serverless dashboard (Pannello di controllo serverless). Puoi vedere che il gruppo di lavoro e lo spazio dei nomi serverless sono disponibili.
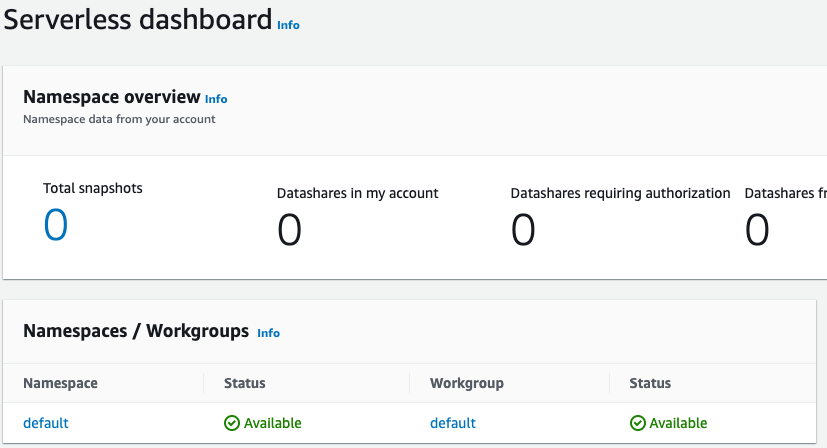
Nota
Se Redshift serverless non crea correttamente il gruppo di lavoro, puoi fare quanto segue:
Risolvi eventuali errori segnalati da Redshift serverless, come la presenza di un numero insufficiente di sottoreti nel VPC Amazon.
Per eliminare il namespace, scegli default-namespace nella dashboard di Redshift serverless e quindi Operazioni, Elimina spazio dei nomi. L’eliminazione di un namespace richiede diversi minuti.
Quando apri di nuovo la console Redshift serverless, viene visualizzata la schermata di benvenuto.
Caricamento di dati di esempio
Ora che è stato configurato il data warehouse con Amazon Redshift Serverless, puoi utilizzare l'editor di query Amazon Redshift v2 per caricare dati di esempio.
-
Per avviare l'editor di query v2 dalla console Amazon Redshift Serverless, scegli Esegui query sui data. Quando richiami l'editor di query v2 dalla console di Amazon Redshift Serverless, viene visualizzata una nuova scheda del browser con l'editor di query. L'editor di query v2 si connette dal computer client all'ambiente Amazon Redshift Serverless.
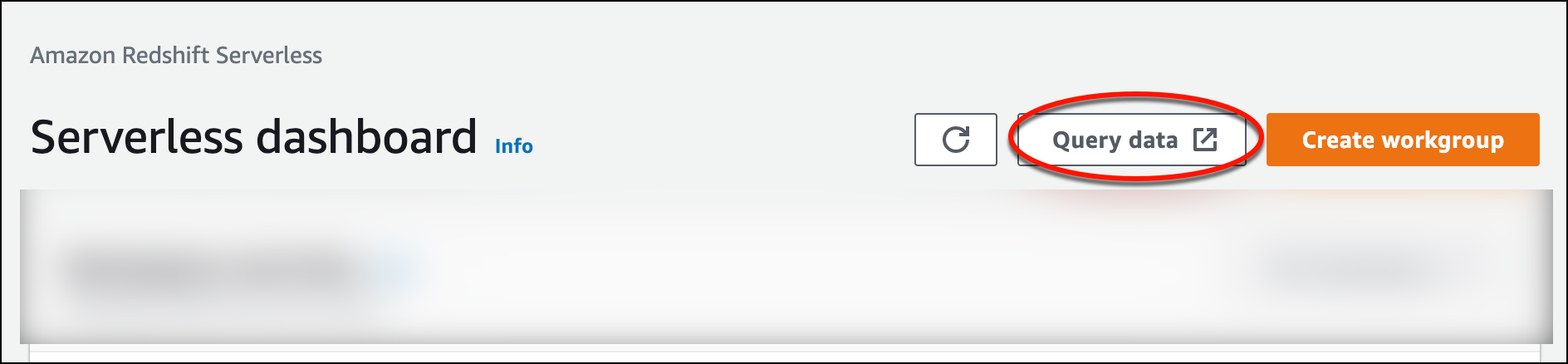
-
Per questa guida, utilizzerai il tuo account AWS amministratore e quello predefinito AWS KMS key. Per ulteriori informazioni sulla configurazione di Query Editor V2, incluse le autorizzazioni necessarie, consulta Configurazione dell’ Account AWS nella Guida alla gestione di Amazon Redshift. Per informazioni sulla configurazione di Amazon Redshift per l'utilizzo di una chiave gestita dal cliente o per modificare la chiave KMS utilizzata da Amazon Redshift, consulta AWS KMS Changing the key for a namespace.
-
Per connettersi a un gruppo di lavoro, scegliere il nome del gruppo di lavoro nel pannello con struttura ad albero.
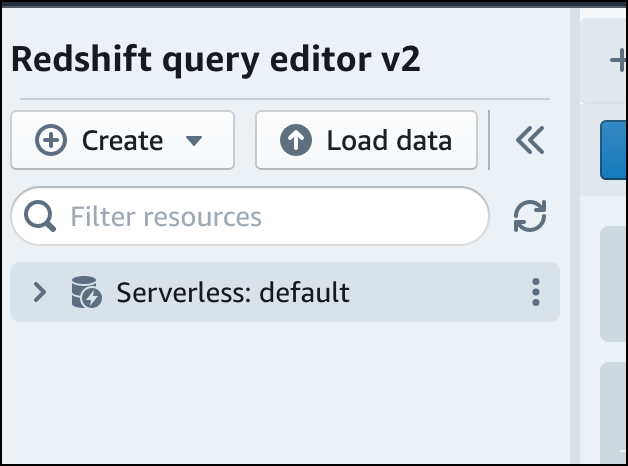
-
Quando ti connetti a un nuovo gruppo di lavoro per la prima volta nell'editor di query v2, devi selezionare il tipo di autenticazione da utilizzare per connetterti al gruppo di lavoro. Per questa guida, lascia selezionato Utente federato e scegli Crea connessione.
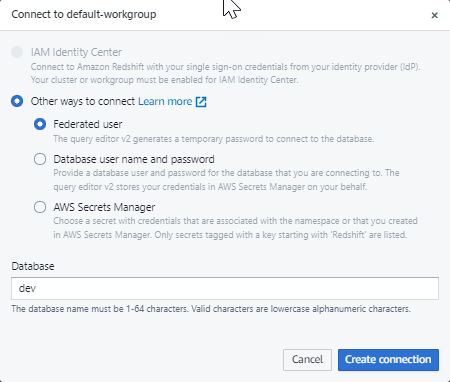
Una volta connesso, puoi scegliere di caricare dati di esempio da Amazon Redshift serverless o da un bucket Amazon S3.
-
Nel gruppo di lavoro Amazon Redshift Serverless predefinito, espandi il database sample_data_dev. Esistono tre schemi di esempio corrispondenti a tre set di dati di esempio che puoi caricare nel database Amazon Redshift serverless. Scegli il set di dati di esempio che desideri caricare e scegli Apri notebook di esempio.
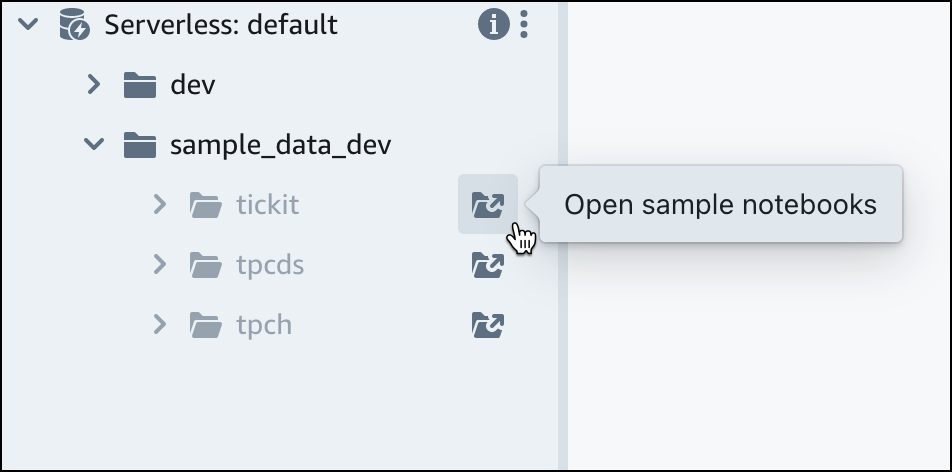
Nota
Un notebook SQL è un container per le celle SQL e Markdown. Puoi utilizzare i notebook per organizzare, annotare e condividere più comandi SQL in un singolo documento.
-
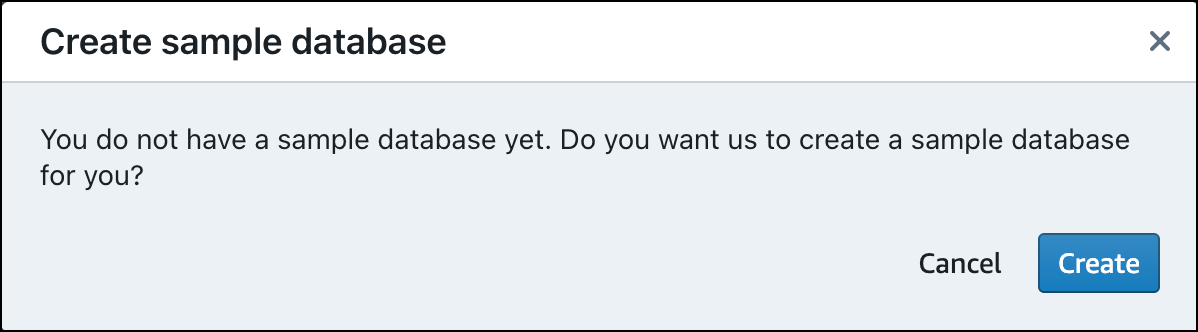
Quando si caricano i dati per la prima volta, l'editor di query v2 richiederà di creare un database di esempio. Scegli Create (Crea).
Esecuzione di query di esempio
Dopo aver configurato Amazon Redshift serverless, puoi iniziare a utilizzare un set di dati di esempio in Amazon Redshift serverless. Amazon Redshift serverless carica automaticamente il set di dati di esempio, ad esempio il set di dati tickit, ed è possibile eseguire immediatamente le query sui dati.
-
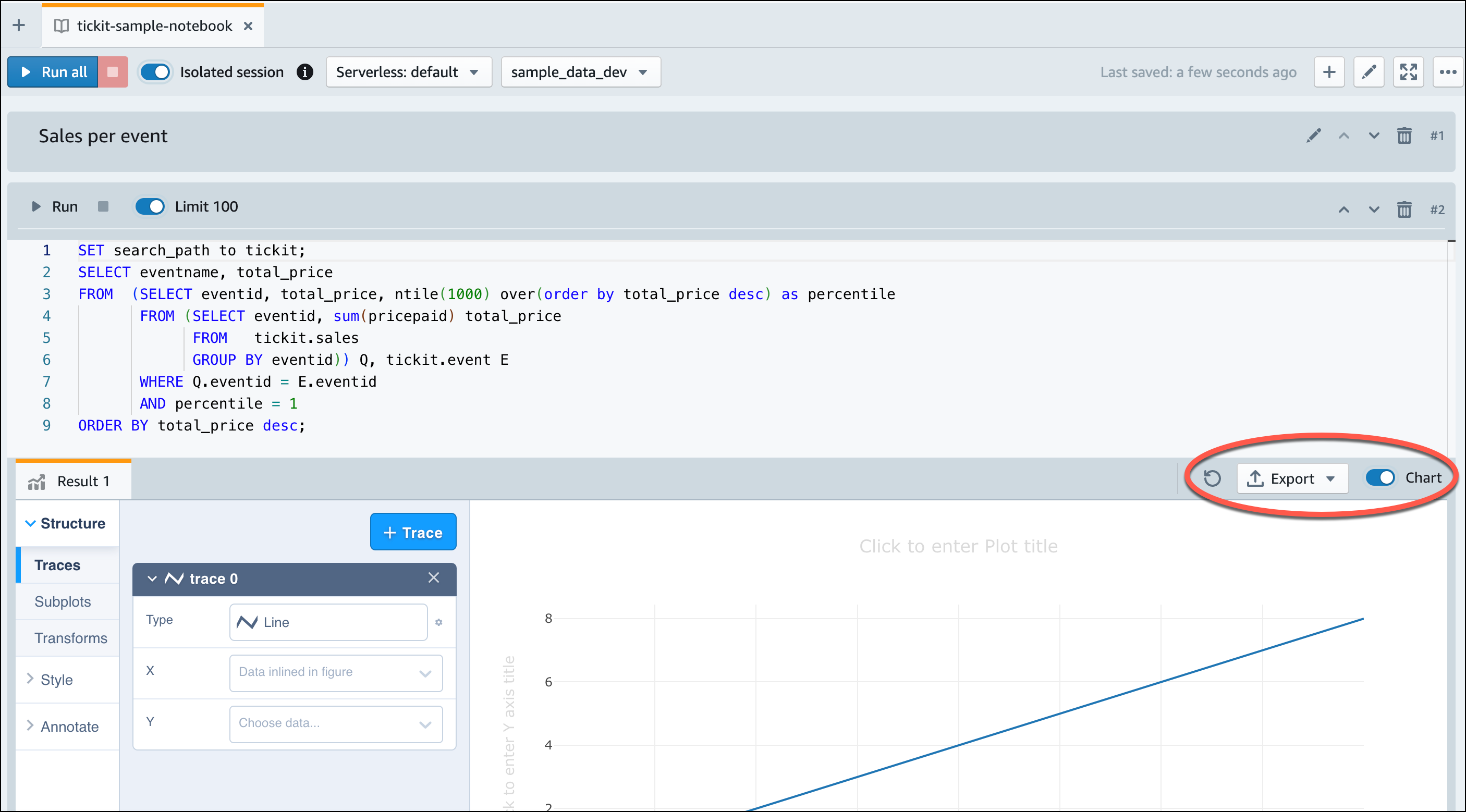
Una volta che Amazon Redshift serverless ha terminato il caricamento dei dati di esempio, tutte le query di esempio vengono caricate nell'editor. Puoi scegliere Esegui tutto per eseguire tutte le query dai notebook di esempio.
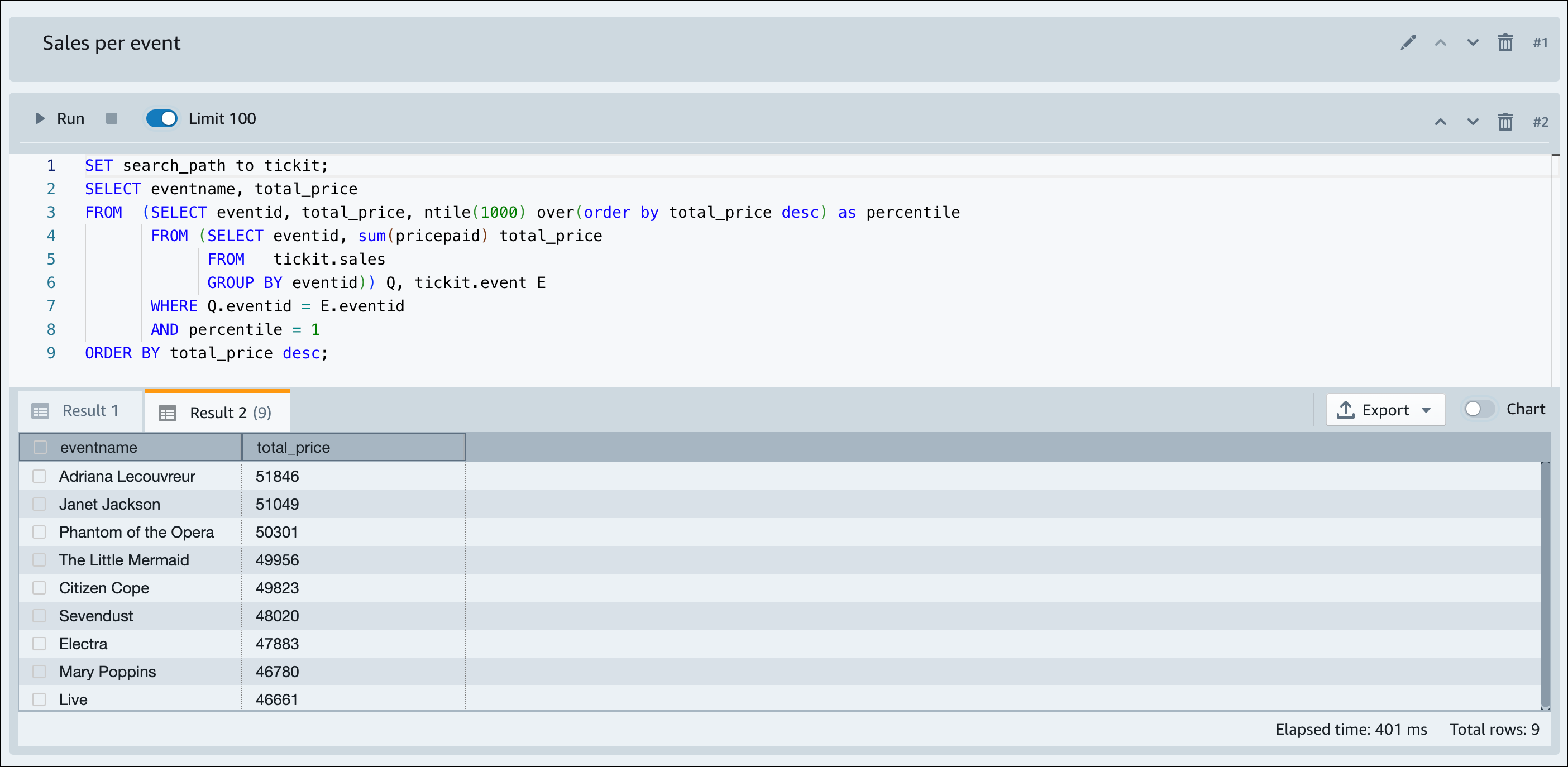
Puoi anche esportare i risultati come file JSON o CSV o visualizzarli in un grafico.
Puoi anche caricare i dati da un bucket Amazon S3. Per ulteriori informazioni, consulta Caricamento di dati da Amazon S3.
Caricamento di dati da Amazon S3
Una volta creato il data warehouse, puoi caricare i dati da Amazon S3.
A questo punto, disponi di un database denominato dev. Successivamente, crea alcune tabelle nel database, carica i dati nelle tabelle e prova a eseguire una query. Per maggiore praticità, i dati di esempio da caricare sono disponibili in un bucket Amazon S3.
-
Prima di poter caricare i dati da Amazon S3, è necessario prima creare un ruolo IAM con le autorizzazioni necessarie e collegarlo al proprio spazio dei nomi serverless. A tale scopo torna alla console Redshift serverless e scegli Configurazione del namespace. Dal menu di navigazione scegli il namespace e quindi Sicurezza e crittografia. Scegli Gestisci ruoli IAM.
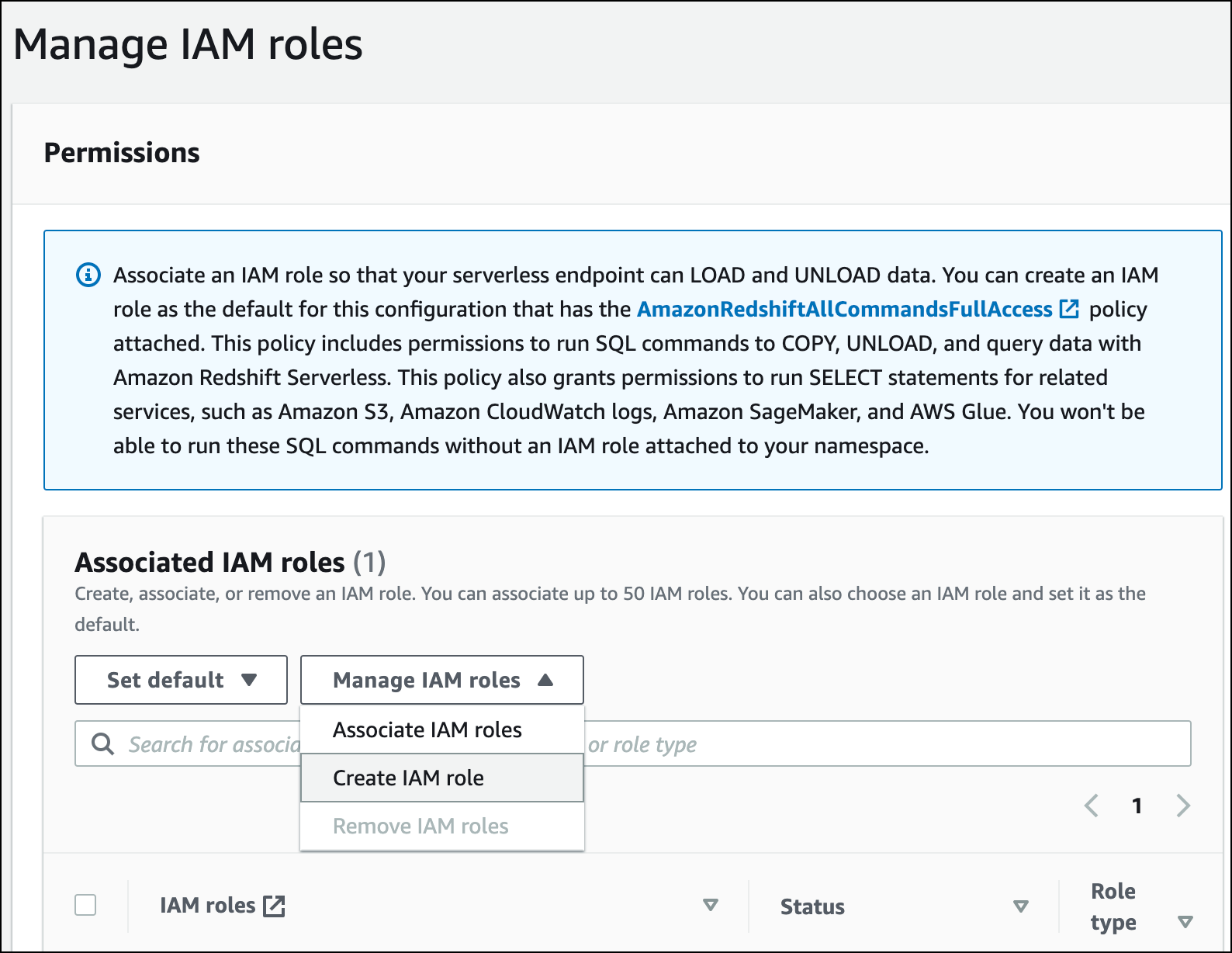
Espandi il menu Gestisci ruoli IAM e scegli Crea ruolo IAM.
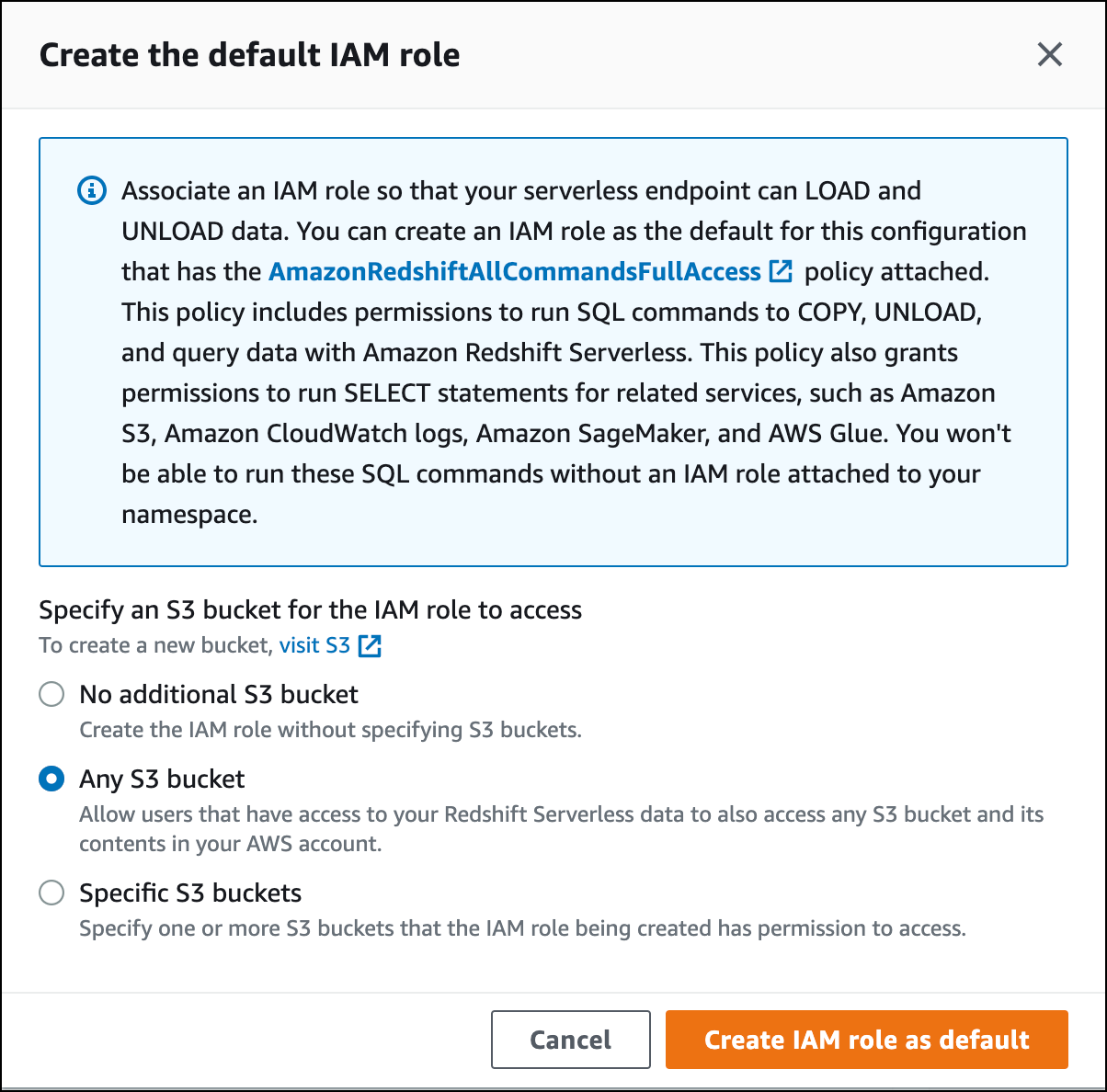
Scegli il livello di accesso al bucket S3 che desideri concedere a questo ruolo e scegli Crea ruolo IAM come default.
-
Scegli Save changes (Salva modifiche). È ora possibile caricare i dati di esempio da Amazon S3.
Le fasi seguenti utilizzano i dati all'interno di un bucket S3 pubblico di Amazon Redshift, ma è possibile replicare le stesse fasi utilizzando il proprio bucket S3 e i propri comandi SQL.
Caricamento di dati di esempio da Amazon S3
-
Nell'editor di query v2, scegli
 Aggiungi, quindi scegli Notebook per creare un nuovo notebook SQL.
Aggiungi, quindi scegli Notebook per creare un nuovo notebook SQL.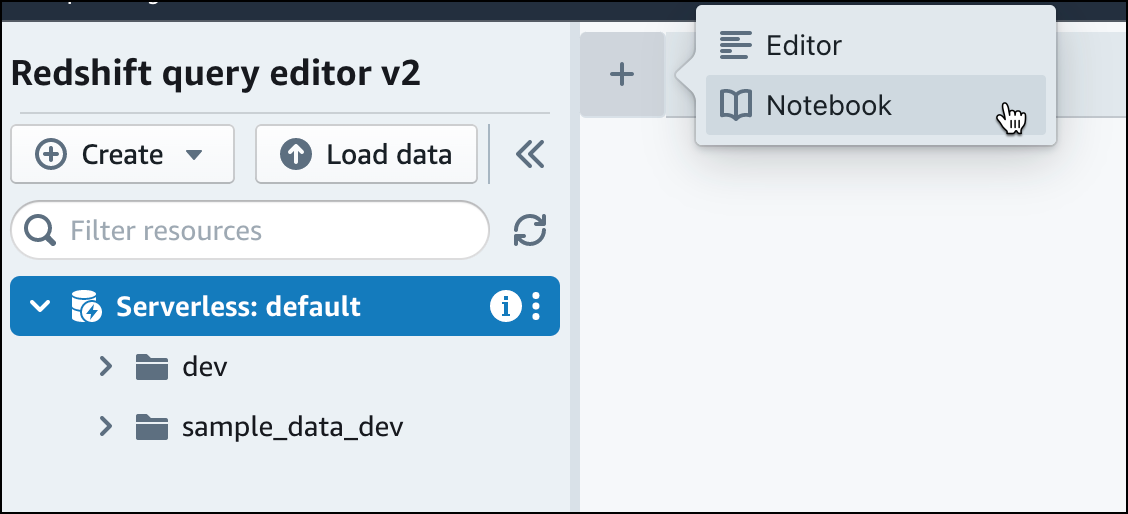
-
Passaggio al database
dev.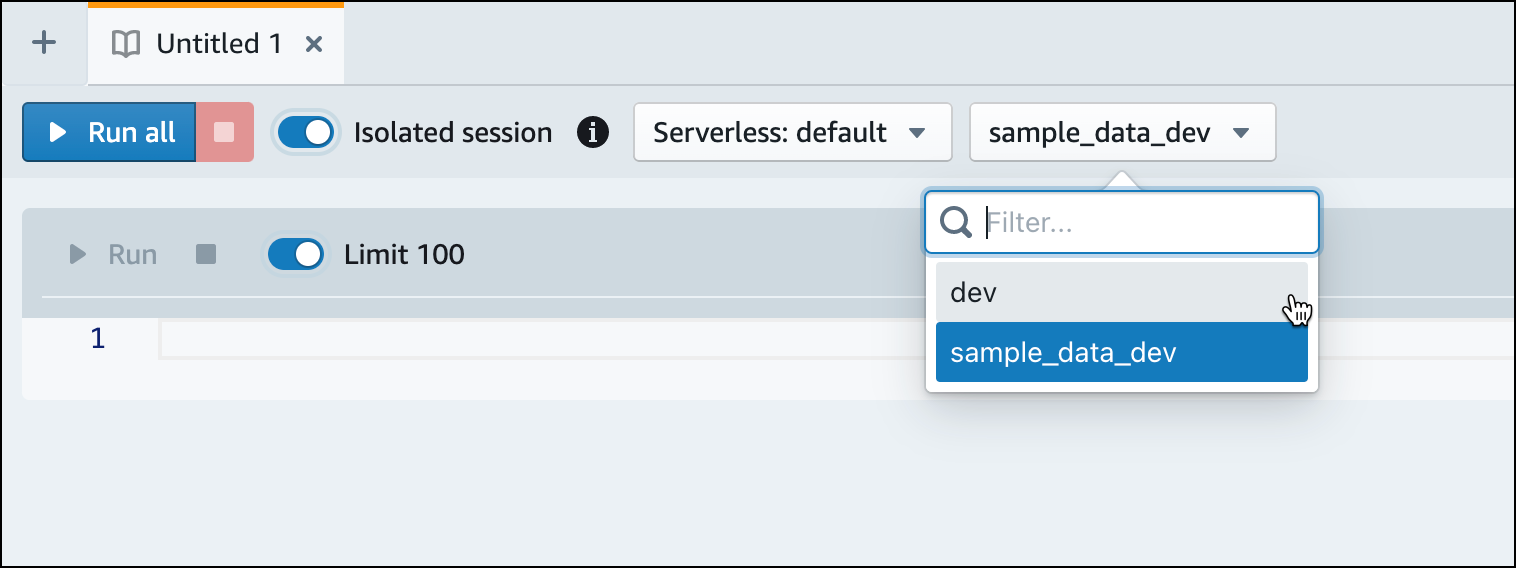
-
Per creare le tabelle.
Se utilizzi l'editor di query v2, copia ed esegui le seguenti istruzioni per la creazione delle tabelle nel database
dev. Per ulteriori informazioni sulla sintassi, consultare CREATE TABLE nella Guida per gli sviluppatori di database di Amazon Redshift.create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp); -
Nell'editor di query v2, crea una nuova cella SQL nel notebook.
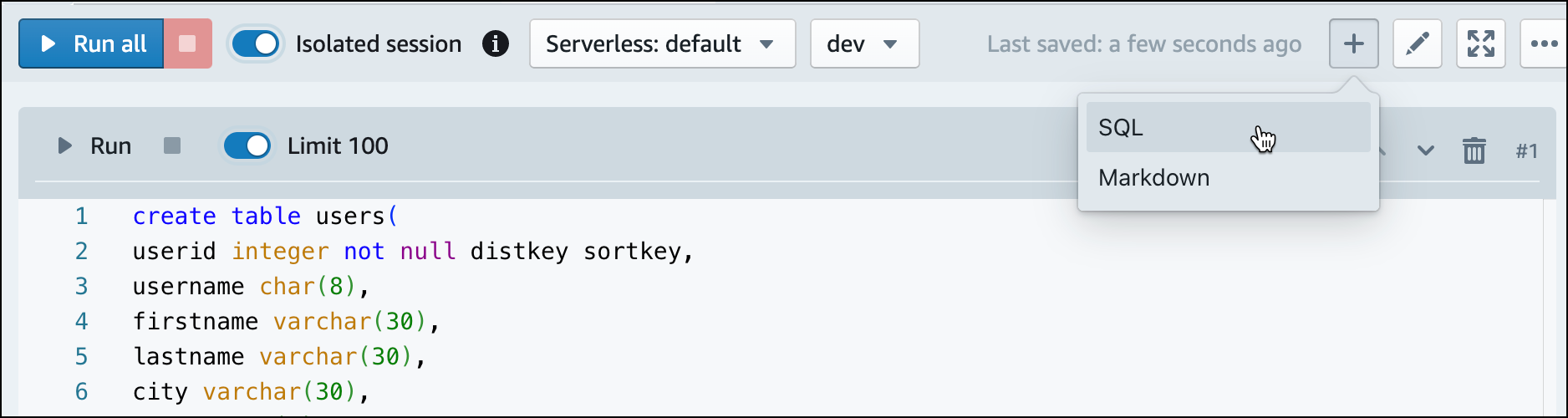
-
Utilizza ora il comando COPY nell'editor di query v2 per caricare set di dati di grandi dimensioni da Amazon S3 o da Amazon DynamoDB in Amazon Redshift. Per ulteriori informazioni sulla sintassi di COPY, consultare COPY nella Guida per gli sviluppatori di database di Amazon Redshift.
Puoi eseguire il comando COPY con alcuni dati di esempio disponibili in un bucket S3 pubblico. Esegui i seguenti comandi SQL nell'editor di query v2.
COPY users FROM 's3://redshift-downloads/tickit/allusers_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY event FROM 's3://redshift-downloads/tickit/allevents_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY sales FROM 's3://redshift-downloads/tickit/sales_tab.txt' DELIMITER '\t' TIMEFORMAT 'MM/DD/YYYY HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; -
Dopo aver caricato i dati, crea un'altra cella SQL nel notebook e prova alcune query di esempio. Per ulteriori informazioni sull'utilizzo del comando SELECT, consultare SELECT nella Guida per gli sviluppatori di database di Amazon Redshift. Per comprendere la struttura e gli schemi dei dati di esempio, esplora l'utilizzo dell'editor di query v2.
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; -- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc;
Ora che sono stati caricati i dati ed eseguito alcune query di esempio, puoi esplorare altre aree di Amazon Redshift serverless. Consulta l'elenco seguente per ulteriori informazioni su come utilizzare Amazon Redshift serverless.
-
Puoi caricare i dati da un bucket Amazon S3. Per ulteriori informazioni, consulta Caricamento dei dati da Amazon S3.
-
Puoi utilizzare l'editor di query v2 per caricare dati da un file locale separato da caratteri di dimensioni inferiori a 5 MB. Per ulteriori informazioni, consulta la sezione relativa al caricamento di dati da un file locale.
-
Puoi connetterti ad Amazon Redshift serverless con strumenti SQL di terze parti con i driver JDBC e ODBC. Per ulteriori informazioni, consulta Connessione ad Amazon Redshift serverless.
-
Puoi anche utilizzare l'Amazon Redshift Data API per connetterti ad Amazon Redshift Serverless. Per ulteriori informazioni, consulta Uso dell'API dati di Amazon Redshift
. -
Puoi utilizzare i dati in Amazon Redshift serverless con Redshift ML per creare modelli di machine learning con il comando CREATE MODEL. Consulta il tutorial: Building customer churn models (Creazione di modelli di abbandono dei clienti) per informazioni su come creare un modello ML di Redshift.
-
Puoi eseguire query sui dati da un data lake Amazon S3 senza caricare i dati in Amazon Redshift serverless. Per ulteriori informazioni, consulta Esecuzione di query in un data lake.
