Oracle トランスポータブル表領域を使用した移行
Oracle トランスポータブル表領域機能を使用して、オンプレミスの Oracle データベースから RDS for Oracle DB インスタンスにテーブルスペースのセットをコピーできます。物理レベルでは、Amazon EFS または Amazon S3 を使用して、ソースデータファイルとメタデータファイルをターゲット DB インスタンスに転送します。トランスポータブルテーブルスペース機能は rdsadmin.rdsadmin_transport_util パッケージを使用します。このプロシージャの構文とセマンティクスについては、「テーブルスペースの転送」を参照してください。
表領域をトランスポートする方法を説明したブログ記事については、「Migrate Oracle Databases to AWS using transportable tablespace
トピック
Oracle トランスポータブル表領域の概要
トランスポータブル表領域セットは、トランスポートされる表領域セットのデータファイルと、表領域メタデータを含むエクスポートダンプファイルで構成されます。トランスポータブル表領域などの物理的な移行ソリューションでは、物理ファイル (データファイル、構成ファイル、Data Pump ダンプファイル) を転送します。
トランスポータブル表領域のメリットとデメリット
ダウンタイムを最小限に抑えて 1 つ以上の大きな表領域を RDS に移行する必要がある場合は、トランスポータブル表領域を使用することをお勧めします。トランスポータブル表領域には、論理移行に比べて次のような利点があります。
-
ダウンタイムは他のほとんどの Oracle 移行ソリューションよりも短いです。
-
トランスポータブル表領域機能は物理ファイルのみをコピーするため、論理移行で発生する可能性のあるデータ整合性エラーや論理的な破損を回避できます。
-
追加のライセンスは必要ありません。
-
例えば、Oracle Solaris プラットフォームから Linux など、さまざまなプラットフォームやエンディアンネスタイプにわたって表領域のセットを移行できます。ただし、Windows サーバーとの間で表領域を転送したり、Windows サーバーから転送することはサポートされていません。
注記
Linux は完全にテスト済みでサポートされています。すべての UNIX バリエーションでテストされているわけではありません。
トランスポータブル表領域を使用する場合は、Amazon S3 または Amazon EFS を使用してデータを転送できます。
-
EFS を使用する場合、バックアップはインポート中も EFS ファイルシステムに残ります。ファイルは後で削除できます。この手法では、DB インスタンスに EBS ストレージをプロビジョニングする必要はありません。このため、S3 ではなく Amazon EFS を使用することをお勧めします。詳細については、「Amazon EFS の統合」を参照してください。
-
S3 を使用する場合、DB インスタンスに接続された EBS ストレージに RMAN バックアップをダウンロードします。インポート中、ファイルは EBS ストレージに残ります。インポート後にこのスペースを解放できます。このスペースは DB インスタンスに割り当てられたままです。
トランスポータブル表領域の主な欠点は、Oracle Database に関する比較的高度な知識が必要なことです。詳細は、Oracle Database 管理者ガイドの「データベース間での表領域のトランスポート
トランスポータブル表領域の制限事項
RDS for Oracle でこの機能を使用する場合、Oracle データベースのトランスポータブル表領域の制限が適用されます。詳細は、Oracle Database 管理者ガイドの「トランスポータブル表領域の制限
-
ソースデータベースとターゲットデータベースのどちらも Standard Edition 2 (SE2) を使用できません。Enterprise Edition のみがサポートされています。
-
Oracle Database 11g データベースをソースとして使用することはできません。RMAN クロスプラットフォームトランスポータブルテーブルスペース機能は、Oracle Database 11g がサポートしていない RMAN トランスポートメカニズムに依存しています。
-
トランスポータブル表領域を使用して RDS for Oracle DB インスタンスからデータを移行することはできません。トランスポータブル表領域は、データを RDS for Oracle DB インスタンスに移行するときのみに使用できます。
-
Windows オペレーティングシステムはサポートされていません。
-
表領域を下位リリースレベルのデータベースにトランスポートすることはできません。ターゲットデータベースは、ソースデータベースと同じかそれ以降のリリースレベルでなければいけません。例えば、表領域を Oracle Database 21c から Oracle Database 19c にトランスポートすることはできません。
-
SYSTEMおよびSYSAUXなどの管理上の表領域はトランスポートできません。 -
PL/SQL パッケージ、Java クラス、ビュー、トリガー、シーケンス、ユーザー、ロール、一時テーブルなどの非データオブジェクトは転送できません。データ以外のオブジェクトを転送するには、手動で作成するか、Data Pump メタデータのエクスポートとインポートを使用します。詳細については、「Oracle サポートノート 1454872.1
」を参照してください。 -
暗号化された表領域や暗号化された列を使用する表領域はトランスポートできません。
-
Amazon S3 を使用してファイルを転送する場合、サポートされる最大ファイルサイズは 5 TiB です。
-
ソースデータベースが Spatial などの Oracle オプションを使用している場合は、ターゲットデータベースで同じオプションが設定されていない限り、表領域をトランスポートできません。
-
Oracle レプリカ構成の RDS for Oracle DB インスタンスに表領域をトランスポートできません。回避策としては、すべてのレプリカを削除し、表領域をトランスポートしてから、レプリカを再作成できます。
トランスポータブル表領域の前提条件
開始する前に、以下のタスクを完了します。
-
My Oracle Support の次のドキュメントに記載されているトランスポータブル表領域の要件を確認してください。
-
エンディアンネス変換の計画 ソースプラットフォーム ID を指定すると、RDS for Oracle はエンディアンネスを自動的に変換します。プラットフォーム ID の確認方法については、「同一 Data Guard 構成の異機種間プライマリおよびフィジカルスタンバイに関する Data Guard のサポート(Doc ID 413484.1)
」を参照してください。 -
ターゲット DB インスタンスでトランスポータブル表領域機能が有効になっていることを確認してください。この機能は、次のクエリを実行しても
ORA-20304エラーが表示されない場合にのみ有効になります。SELECT * FROM TABLE(rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files);トランスポータブル表領域機能が有効になっていない場合は、DB インスタンスを再起動します。詳細については、「 DB インスタンスの再起動」を参照してください。
-
タイムゾーンファイルがソースとターゲットのデータベース間で同じであることを確認します。
-
ソースとターゲットのデータベースの文字セットが、次のいずれかの要件を満たしていることを確認します。
-
文字セットは同じです。
-
文字セットに互換性があります。互換性要件のリストについては、Oracle データベースドキュメントの「General Limitations on Transporting Data
」を参照してください。
-
-
Amazon S3 を使用してファイルを転送する予定がある場合は、以下を実行してください。
-
Amazon S3 バケットをファイル転送に使用でき、この Amazon S3 バケットが、DB インスタンスと同じ AWS リージョン内にあることを確認します。手順については、Amazon Simple Storage Service 入門ガイドの「バケットの作成」を参照してください。
-
Amazon RDS 統合用の Amazon S3 バケットは、「Amazon S3 と RDS for Oracle を統合する IAM アクセス許可の設定」の手順に従って準備してください。
-
-
Amazon EFS を使用してファイルを転送する場合は、Amazon EFS の統合 の手順に従って EFS を設定したことを確認してください。
-
ターゲット DB インスタンスで自動バックアップを有効にすることを強くお勧めします。メタデータのインポートステップは失敗する可能性があるため、DB インスタンスをインポート前の状態に復元できることが重要です。それによって、表領域を再度バックアップ、転送、インポートする必要がなくなります。
フェーズ 1: ソースホストをセットアップする
このステップでは、My Oracle Support から提供されているトランスポート表領域スクリプトをコピーし、必要な構成ファイルを設定します。次のステップでは、ソースホストは、ターゲットインスタンスにトランスポートされる表領域を含むデータベースを実行しています。
ソースホストを設定するには
-
Oracle ホームのオーナーとしてソースホストにログインします。
-
ORACLE_HOMEおよびORACLE_SID環境変数がソースデータベースを指していることを確認してください。 -
管理者としてデータベースにログインし、タイムゾーンバージョン、DB 文字セット、および各国語文字セットがターゲットデータベースと同じであることを確認します。
SELECT * FROM V$TIMEZONE_FILE; SELECT * FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER IN ('NLS_CHARACTERSET','NLS_NCHAR_CHARACTERSET'); -
Oracle Support ノート 2471245.1
の説明に従って、トランスポータブル表領域ユーティリティを設定します。 セットアップには、ソースホスト上の
xtt.propertiesファイルの編集が含まれます。次のサンプルxtt.propertiesファイルは、/dsk1/backupsディレクトリ内の 3 つの表領域のバックアップを指定しています。これらは、ターゲット DB インスタンスにトランスポートする予定の表領域です。また、エンディアンネスを自動的に変換するソースプラットフォーム ID も指定します。注記
有効なプラットフォーム ID については、「同一 Data Guard 構成の異機種間プライマリおよびフィジカルスタンバイに関する Data Guard のサポート(Doc ID 413484.1)
」を参照してください。 #linux system platformid=13#list of tablespaces to transport tablespaces=TBS1,TBS2,TBS3#location where backup will be generated src_scratch_location=/dsk1/backups#RMAN command for performing backup usermantransport=1
フェーズ 2: 表領域のフルバックアップを準備する
このフェーズでは、初めて表領域をバックアップし、そのバックアップをターゲットホストに転送してから、プロシージャ rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces を使用して表領域を復元します。このフェーズが完了すると、最初の表領域バックアップはターゲット DB インスタンスに保存され、増分バックアップで更新できます。
トピック
ステップ 1: ソースホストの表領域をバックアップする
このステップでは、xttdriver.pl スクリプトを使用して表領域のフルバックアップを作成します。xttdriver.pl の出力は、TMPDIR 環境変数に格納されます。
表領域をバックアップするには
-
表領域が読み取り専用モードの場合は、
ALTER TABLESPACE権限を持つユーザーとしてソースデータベースにログインし、表領域を読み取り/書き込みモードにします。それ以外の場合は、次のステップに進みます。次の例では
tbs1、tbs2、tbs3を読み取り/書き込みモードにします。ALTER TABLESPACE tbs1 READ WRITE; ALTER TABLESPACE tbs2 READ WRITE; ALTER TABLESPACE tbs3 READ WRITE; -
xttdriver.plスクリプトを使用して表領域をバックアップします。オプションで、--debugを指定してデバッグモードでスクリプトを実行できます。export TMPDIR=location_of_log_filescdlocation_of_xttdriver.pl$ORACLE_HOME/perl/bin/perl xttdriver.pl --backup
ステップ 2: バックアップファイルをターゲット DB インスタンスに転送する
このステップでは、バックアップファイルと設定ファイルをスクラッチの場所からターゲット DB インスタンスにコピーします。以下のオプションのいずれかを選択してください。
-
ソースホストとターゲットホストが Amazon EFS ファイルシステムを共有する場合は、
cpなどのオペレーティングシステムユーティリティを使用して、バックアップファイルとres.txtファイルをスクラッチの場所から共有ディレクトリにコピーします。その後、ステップ 3: ターゲット DB インスタンスに表領域をインポートするに進みます。 -
バックアップを Amazon S3 バケットにステージングする必要がある場合は、以下の手順を実行してください。
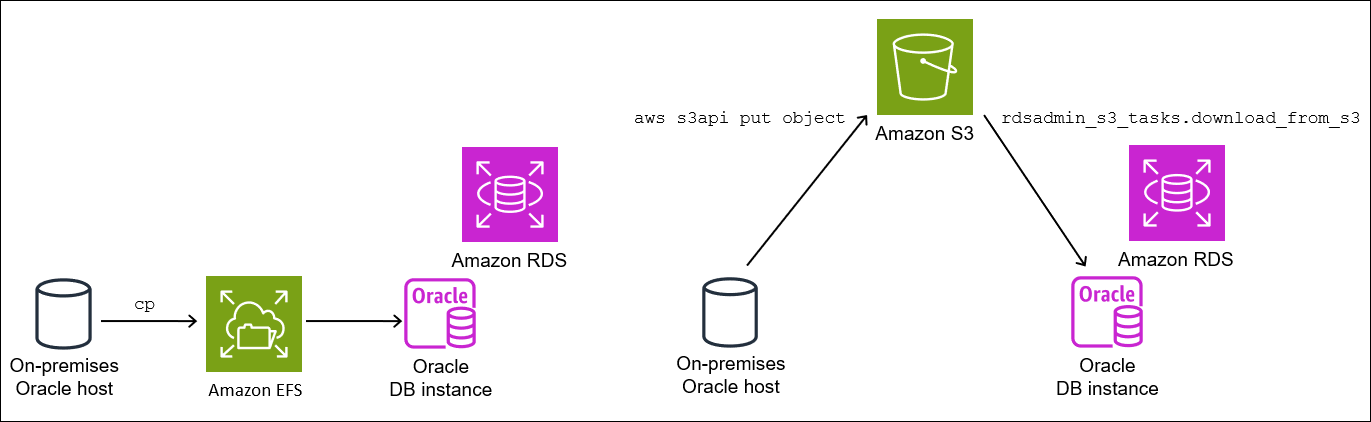
ステップ 2.2: Amazon S3 バケットにダンプファイルをアップロードする
バックアップと res.txt ファイルをスクラッチディレクトリから Amazon S3 バケットにアップロードします。詳細については、Amazon Simple Storage Service 開発者ガイドの「オブジェクトのアップロード」を参照してください。
ステップ 2.3: バックアップを Amazon S3 バケットからターゲット DB インスタンスにダウンロードする
このステップでは、プロシージャ rdsadmin.rdsadmin_s3_tasks.download_from_s3 を使用して RDS for Oracle DB インスタンスにバックアップをダウンロードします。
Amazon S3 バケットからバックアップをダウンロードするには
-
SQL*Plus または Oracle SQL Developer を起動し、RDS for Oracle DB インスタンスにログインします。
-
Amazon S3 バケットからターゲット DB インスタンスにバックアップをダウンロードします。これには、Amazon S3 バケットからターゲット DB インスタンスにファイルをダウンロードするための Amazon RDS プロシージャ
rdsadmin.rdsadmin_s3_tasks.download_from_s3を使用します。次の例では、amzn-s3-demo-bucketDATA_PUMP_DIREXEC UTL_FILE.FREMOVE ('DATA_PUMP_DIR', 'res.txt'); SELECT rdsadmin.rdsadmin_s3_tasks.download_from_s3( p_bucket_name => 'amzn-s3-demo-bucket', p_directory_name => 'DATA_PUMP_DIR') AS TASK_ID FROM DUAL;SELECTステートメントでは、データ型VARCHAR2のタスクの ID が返ります。詳細については、「Amazon S3 バケットから Oracle DB インスタンスにファイルをダウンロードする」を参照してください。
ステップ 3: ターゲット DB インスタンスに表領域をインポートする
プロシージャ rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces を使用して、表領域をターゲット DB インスタンスに復元します。このプロシージャは、データファイルを正しいエンディアン形式に自動的に変換します。
Linux 以外のプラットフォームからインポートする場合は、import_xtts_tablespaces を呼び出すときに p_platform_id パラメータを使用してソースプラットフォームを指定します。指定するプラットフォーム ID が、ステップ 2: ソースホストに表領域メタデータをエクスポートする の xtt.properties ファイルで指定されたものと一致していることを確認してください。
ターゲット DB インスタンスに表領域をインポートする
-
Oracle SQL クライアントを起動し、ターゲット RDS for Oracle DB インスタンスにマスターユーザーとしてログインします。
-
インポートする表領域とバックアップを含むディレクトリを指定して、
rdsadmin.rdsadmin_transport_util.import_xtts_tablespacesプロシージャを実行します。以下の例では、表領域
TBS1、TBS2、およびTBS3をディレクトリDATA_PUMP_DIRからインポートします。ソースプラットフォームは AIX ベースのシステム (64 ビット) で、プラットフォーム ID は6です。プラットフォーム ID は、V$TRANSPORTABLE_PLATFORMをクエリすることで確認できます。VAR task_id CLOB BEGIN :task_id:=rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces( 'TBS1,TBS2,TBS3', 'DATA_PUMP_DIR', p_platform_id => 6); END; / PRINT task_id -
(オプション) テーブル
rdsadmin.rds_xtts_operation_infoにクエリを実行して進行状況を監視します。xtts_operation_state列には、EXECUTING、COMPLETED、またはFAILEDという値が表示されます。SELECT * FROM rdsadmin.rds_xtts_operation_info;注記
実行時間が長い操作の場合は、
V$SESSION_LONGOPS、V$RMAN_STATUS、V$RMAN_OUTPUTにクエリを実行することもできます。 -
前のステップのタスク ID を使用して、完了したインポートのログを表示します。
SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file('BDUMP', 'dbtask-'||'&task_id'||'.log'));インポートが正常に完了したことを確認してから、次の手順に進みます。
フェーズ 3: 増分バックアップを作成および転送する
このフェーズでは、ソースデータベースがアクティブな間、定期的に増分バックアップを作成して転送します。この手法を実行することで、最終的な表領域バックアップのサイズが小さくなります。複数の増分バックアップを行う場合、最後の増分バックアップの後に res.txt ファイルをコピーしてから、ターゲットインスタンスに適用する必要があります。
手順は フェーズ 2: 表領域のフルバックアップを準備する と同じですが、インポートの手順が任意である点が異なります。
フェーズ 4: 表領域をトランスポートする
このフェーズでは、読み取り専用の表領域をバックアップし、Data Pump メタデータをエクスポートし、これらのファイルをターゲットホストに転送して、表領域とメタデータの両方をインポートします。
トピック
ステップ 1: 読み取り専用の表領域をバックアップする
このステップは ステップ 1: ソースホストの表領域をバックアップする と同じですが、重要な違いが 1 つあります。最後に表領域をバックアップする前に、表領域を読み取り専用モードにします。
次の例では、tbs1、tbs2、tbs3 を読み取り専用モードにします。
重要
テーブルスペースを読み取り専用モードに設定すると、移行のためのダウンタイムウィンドウが開始されます。この時点から、アプリケーションはソースデータベース上のこれらのテーブルスペースに書き込むことができなくなります。このステップはメンテナンスウィンドウ中に計画します。
ALTER TABLESPACE tbs1 READ ONLY; ALTER TABLESPACE tbs2 READ ONLY; ALTER TABLESPACE tbs3 READ ONLY;
ステップ 2: ソースホストに表領域メタデータをエクスポートする
ソースホストで expdp ユーティリティを実行して、表領域メタデータをエクスポートします。次の例では、表領域 TBS1、TBS2、および TBS3 を DATA_PUMP_DIR ディレクトリのダンプファイル xttdump.dmp にエクスポートします。
expdpusername/pwd\ dumpfile=xttdump.dmp\ directory=DATA_PUMP_DIR\ statistics=NONE \ transport_tablespaces=TBS1,TBS2,TBS3\ transport_full_check=y \ logfile=tts_export.log
DATA_PUMP_DIR が Amazon EFS の共有ディレクトリである場合は、スキップして ステップ 4: ターゲット DB インスタンスに表領域をインポートする に進んでください。
ステップ 3: (Amazon S3 のみ) バックアップファイルとエクスポートファイルをターゲット DB インスタンスに転送する
Amazon S3 を使用して表領域バックアップと Data Pump エクスポートファイルをステージングする場合は、次の手順を実行してください。
ステップ 3.1: バックアップとダンプファイルをソースホストから Amazon S3 バケットにアップロードする
バックアップとダンプファイルをソースホストから Amazon S3 バケットにアップロードします。詳細については、Amazon Simple Storage Service 開発者ガイドの「オブジェクトのアップロード」を参照してください。
ステップ 3.2: バックアップとダンプファイルを Amazon S3 バケットからターゲット DB インスタンスにダウンロードする
このステップでは、プロシージャ rdsadmin.rdsadmin_s3_tasks.download_from_s3 を使用して RDS for Oracle DB インスタンスにバックアップとダンプファイルをダウンロードします。「ステップ 2.3: バックアップを Amazon S3 バケットからターゲット DB インスタンスにダウンロードする」のステップを実行してください。
ステップ 4: ターゲット DB インスタンスに表領域をインポートする
rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces プロシージャを使用して表領域を復元します。このプロシージャの構文とセマンティクスについては、「転送されたテーブルスペースを DB インスタンスにインポートする」を参照してください。
重要
最後の表領域のインポートが完了したら、次のステップは Oracle Data Pump メタデータのインポートです。インポートが失敗した場合、DB インスタンスを失敗前の状態に戻すことが重要です。そのため、Amazon RDS のシングル AZ DB インスタンスの DB スナップショットの作成 の手順に従って DB インスタンスの DB スナップショットを作成することをお勧めします。スナップショットにはインポートされたすべての表領域が含まれるため、インポートが失敗した場合でも、バックアップとインポートのプロセスを繰り返す必要はありません。
ターゲット DB インスタンスで自動バックアップがオンになっていて、メタデータをインポートする前に有効なスナップショットが開始されたことを Amazon RDS が検出しない場合、RDS はスナップショットの作成を試みます。インスタンスのアクティビティに応じて、このスナップショットは成功する場合と成功しない場合があります。有効なスナップショットが検出されないか、スナップショットを開始できない場合、メタデータのインポートはエラーを出して終了します。
ターゲット DB インスタンスに表領域をインポートする
-
Oracle SQL クライアントを起動し、ターゲット RDS for Oracle DB インスタンスにマスターユーザーとしてログインします。
-
インポートする表領域とバックアップを含むディレクトリを指定して、
rdsadmin.rdsadmin_transport_util.import_xtts_tablespacesプロシージャを実行します。以下の例では、表領域
TBS1、TBS2、およびTBS3をディレクトリDATA_PUMP_DIRからインポートします。BEGIN :task_id:=rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces('TBS1,TBS2,TBS3','DATA_PUMP_DIR'); END; / PRINT task_id -
(オプション) テーブル
rdsadmin.rds_xtts_operation_infoにクエリを実行して進行状況を監視します。xtts_operation_state列には、EXECUTING、COMPLETED、またはFAILEDという値が表示されます。SELECT * FROM rdsadmin.rds_xtts_operation_info;注記
実行時間が長い操作の場合は、
V$SESSION_LONGOPS、V$RMAN_STATUS、V$RMAN_OUTPUTにクエリを実行することもできます。 -
前のステップのタスク ID を使用して、完了したインポートのログを表示します。
SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file('BDUMP', 'dbtask-'||'&task_id'||'.log'));インポートが正常に完了したことを確認してから、次の手順に進みます。
-
Amazon RDS のシングル AZ DB インスタンスの DB スナップショットの作成 の指示に従って DB スナップショットを手動で作成します。
ステップ 5: ターゲット DB インスタンスに表領域メタデータをインポートする
このステップでは、rdsadmin.rdsadmin_transport_util.import_xtts_metadata プロシージャを使用して RDS for Oracle DB インスタンスにトランスポータブル表領域メタデータをインポートします。このプロシージャの構文とセマンティクスについては、「転送可能テーブルスペースメタデータを DB インスタンスにインポートする」を参照してください。操作中、インポートのステータスがテーブル rdsadmin.rds_xtts_operation_info に表示されます。
重要
メタデータをインポートする前に、表領域をインポートした後に DB スナップショットが正常に作成されたことを確認することを強くお勧めします。インポートステップが失敗した場合は、DB インスタンスを復元し、インポートエラーに対処してから、インポートを再試行してください。
データポンプメタデータを RDS for Oracle DB インスタンスにインポートします
-
Oracle SQL クライアントを起動し、ターゲット DB インスタンスにマスターユーザーとしてログインします。
-
トランスポートされた表領域にスキーマを所有するユーザーがまだ存在しない場合は、それらのユーザーを作成します。
CREATE USERtbs_ownerIDENTIFIED BYpassword; -
ダンプファイルの名前とディレクトリの場所を指定して、メタデータをインポートします。
BEGIN rdsadmin.rdsadmin_transport_util.import_xtts_metadata('xttdump.dmp','DATA_PUMP_DIR'); END; / -
(オプション) トランスポータブル表領域の履歴テーブルにクエリを実行して、メタデータインポートのステータスを確認します。
SELECT * FROM rdsadmin.rds_xtts_operation_info;このオペレーションが完了すると、表領域は読み取り専用モードになります。
-
(オプション) ログファイルを表示します。
次の例では、BDUMP ディレクトリの内容を一覧表示し、インポートログをクエリします。
SELECT * FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => 'BDUMP')); SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file( p_directory => 'BDUMP', p_filename => 'rds-xtts-import_xtts_metadata-2023-05-22.01-52-35.560858000.log'));
フェーズ 5: 転送された表領域を検証する
このオプションのステップでは、rdsadmin.rdsadmin_rman_util.validate_tablespace プロシージャを使用してトランスポートされた表領域を検証し、表領域を読み取り/書き込みモードにします。
転送されたデータを検証するには
-
SQL*Plus または SQL Developer を起動し、ターゲット DB インスタンスにマスターユーザーとしてログインします。
-
rdsadmin.rdsadmin_rman_util.validate_tablespaceプロシージャを使用して表領域を検証します。SET SERVEROUTPUT ON BEGIN rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS1', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS2', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS3', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); END; / -
表領域を読み取り/書き込みモードにします。
ALTER TABLESPACETBS1READ WRITE; ALTER TABLESPACETBS2READ WRITE; ALTER TABLESPACETBS3READ WRITE;
フェーズ 6: 残ったファイルをクリーンアップする
このオプションのステップでは、不要なファイルをすべて削除します。rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files プロシージャを使用して、テーブルスペースのインポート後に孤立したデータファイルを一覧表示して、rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_import プロシージャを使用して削除します。これらのプロシージャの構文とセマンティクスについては、「テーブルスペースのインポート後の孤立ファイルを一覧表示する」および「テーブルスペースのインポート後に孤立したデータファイルを削除する」を参照してください。
残ったファイルをクリーンアップするには
-
次のように
DATA_PUMP_DIRの古いバックアップを削除します。-
rdsadmin.rdsadmin_file_util.listdirを実行してバックアップファイルを一覧表示します。SELECT * FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => 'DATA_PUMP_DIR')); -
UTL_FILE.FREMOVEを呼び出して、バックアップを 1 つずつ削除します。EXEC UTL_FILE.FREMOVE ('DATA_PUMP_DIR', 'backup_filename');
-
-
表領域をインポートしたが、これらの表領域のメタデータをインポートしなかった場合は、孤立したデータファイルを次のように削除できます。
-
削除する必要のある孤立したデータファイルを一覧表示します。次の例では、
rdsadmin.rdsadmin_transport_util.list_xtts_orphan_filesプロシージャを呼び出します。SQL> SELECT * FROM TABLE(rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files); FILENAME FILESIZE -------------- --------- datafile_7.dbf 104865792 datafile_8.dbf 104865792 -
rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_importプロシージャを実行して、孤立したファイルを削除します。BEGIN rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_import('DATA_PUMP_DIR'); END; /クリーンアップ操作により、
BDUMPディレクトリに名前形式rds-xtts-delete_xtts_orphaned_files-を使用するログファイルが生成されます。YYYY-MM-DD.HH24-MI-SS.FF.log -
前のステップで生成されたログファイルを読み込みます。次の例ではログ
rds-xtts-delete_xtts_orphaned_files-を読み取ります。2023-06-01.09-33-11.868894000.logSELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file( p_directory => 'BDUMP', p_filename => 'rds-xtts-delete_xtts_orphaned_files-2023-06-01.09-33-11.868894000.log')); TEXT -------------------------------------------------------------------------------- orphan transported datafile datafile_7.dbf deleted. orphan transported datafile datafile_8.dbf deleted.
-
-
表領域をインポートし、これらの表領域のメタデータをインポートしたものの、互換性エラーやその他の Oracle Data Pump の問題が発生した場合は、次のように部分的にトランスポートされたデータファイルをクリーンアップします。
-
DBA_TABLESPACESクエリを実行して、部分的にトランスポートされたデータファイルを含む表領域を一覧表示します。SQL> SELECT TABLESPACE_NAME FROM DBA_TABLESPACES WHERE PLUGGED_IN='YES'; TABLESPACE_NAME -------------------------------------------------------------------------------- TBS_3 -
表領域と部分的にトランスポートされたデータファイルを削除します。
DROP TABLESPACETBS_3INCLUDING CONTENTS AND DATAFILES;
-
