기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
데이터 원본
이전 섹션에서는 스키마가 데이터의 형태를 정의한다는 것을 배웠습니다. 하지만 해당 데이터의 출처는 설명하지 않았습니다. 실제 프로젝트에서 스키마는 서버에 대한 모든 요청을 처리하는 게이트웨이와 같습니다. 요청이 생성되면 스키마는 클라이언트와 인터페이스하는 단일 엔드포인트 역할을 합니다. 스키마는 데이터 원본의 데이터에 액세스하며 데이터를 처리하고 다시 클라이언트로 전달합니다. 아래 인포그래픽을 참조하세요.
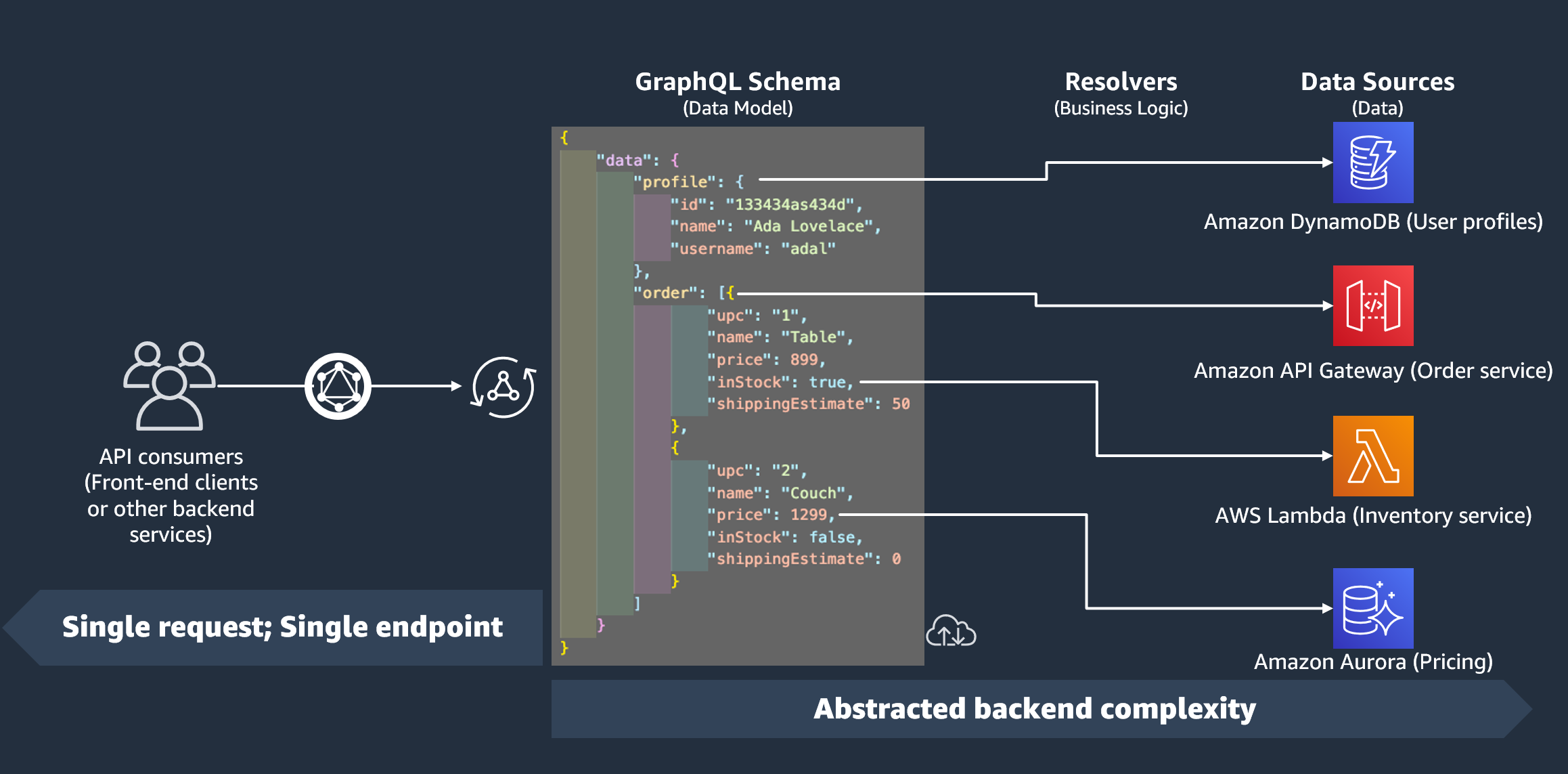
AWS AppSync 및 GraphQL은 프런트엔드용 백엔드(BFF) 솔루션을 완벽하게 구현합니다. 이러한 기능은 함께 작동하여 백엔드를 추상화하여 대규모로 복잡성을 줄입니다. 서비스가 다양한 데이터 원본 또는 마이크로서비스를 사용하는 경우 각 소스(서브그래프)의 데이터 형태를 단일 스키마(수퍼그래프)로 정의하여 기본적으로 복잡성을 어느 정도 추상화할 수 있습니다. 즉, GraphQL API는 하나의 데이터 원본을 사용하도록 제한되지 않습니다. 원하는 수의 데이터 원본을 GraphQL API와 연결하고 해당 데이터 원본이 서비스와 상호 작용하는 방식을 코드에 지정할 수 있습니다.
인포그래픽에서 볼 수 있듯이 GraphQL 스키마에는 클라이언트가 데이터를 요청하는 데 필요한 모든 정보가 포함되어 있습니다. 즉, REST의 경우처럼 여러 요청을 처리하는 대신 단일 요청으로 모든 작업을 처리할 수 있습니다. 이러한 요청은 서비스의 유일한 엔드포인트인 스키마를 거칩니다. 요청이 처리되면 해석기(다음 섹션에서 설명함)가 코드를 실행하여 관련 데이터 원본의 데이터를 처리합니다. 응답이 반환되면 데이터 원본에 연결된 서브그래프가 스키마의 데이터로 채워집니다.
AWS AppSync 는 다양한 데이터 소스 유형을 지원합니다. 아래 테이블에서는 각 유형에 대해 설명하고, 각 유형의 이점을 나열하고, 추가 컨텍스트를 위한 유용한 링크를 제공합니다.
| 데이터 소스 | 설명 | 이점 | 추가 정보 |
|---|---|---|---|
| Amazon DynamoDB | “Amazon DynamoDB는 완전관리형 NoSQL 데이터베이스 서비스로서 원활한 확장성과 함께 빠르고 예측 가능한 성능을 제공합니다. DynamoDB는 분산 데이터베이스를 운영하고 크기 조정하는 데 따른 관리 부담을 줄여서 하드웨어 프로비저닝, 설정 및 구성, 복제, 소프트웨어 패치 또는 클러스터 크기 조정에 대해 걱정할 필요가 없게 합니다. 또한 DynamoDB는 유휴 시 암호화를 제공하여 중요한 데이터 보호와 관련된 운영 부담 및 복잡성을 제거합니다.” |
|
|
| AWS Lambda | AWS Lambda "는 서버를 프로비저닝하거나 관리하지 않고도 코드를 실행할 수 있는 컴퓨팅 서비스입니다. Lambda는 고가용성 컴퓨팅 인프라에서 코드를 실행하고 서버와 운영 체제 유지 관리, 용량 프로비저닝 및 자동 조정, 코드 및 보안 패치 배포, 로깅 등 모든 컴퓨팅 리소스 관리를 수행합니다. Lambda를 사용하면 Lambda가 지원하는 언어 런타임 중 하나로 코드를 제공하기만 하면 됩니다.” |
|
|
| OpenSearch | “Amazon OpenSearch Service는 AWS 클라우드에서 OpenSearch 클러스터를 쉽게 배포, 운영 및 확장할 수 있는 관리형 서비스입니다. Amazon OpenSearch Service는 OpenSearch 및 레거시 Elasticsearch OSS(소프트웨어의 최종 오픈 소스 버전인 7.10까지)를 지원합니다. 클러스터를 생성할 때 어떤 검색 엔진을 사용할지 선택할 수 있습니다. OpenSearch는 로그 분석, 실시간 애플리케이션 모니터링, 클릭 스트림 분석 같은 사용 사례를 위한 완전한 오픈 소스 검색 및 분석 엔진입니다. 자세한 내용은 OpenSearch 설명서 Amazon OpenSearch Service는 OpenSearch 클러스터에 대한 모든 리소스를 프로비저닝하고 시작합니다. 또한 실패한 OpenSearch Service 노드를 자동으로 감지한 다음 교체해 자체 관리형 인프라와 관련된 오버헤드를 줄입니다. API를 한 번만 호출하거나 콘솔에서 몇 번만 클릭하여 클러스터를 조정할 수 있습니다.” |
|
|
| HTTP 엔드포인트 | HTTP 엔드포인트를 데이터 소스로 사용할 수 있습니다. AWS AppSync는 파라미터 및 페이로드와 같은 관련 정보를 사용하여 엔드포인트에 요청을 보낼 수 있습니다. HTTP 응답은 해석기에 노출되며, 해석기는 작업이 완료된 후 최종 응답을 반환합니다. |
|
|
| Amazon EventBridge | “EventBridge는 이벤트를 사용하여 애플리케이션 구성 요소를 서로 연결하는 서버리스 서비스로, 확장 가능한 이벤트 기반 애플리케이션을 더 쉽게 구축할 수 있습니다. 이를 사용하여 자체 개발 애플리케이션, AWS 서비스 및 타사 소프트웨어와 같은 소스의 이벤트를 조직 전체의 소비자 애플리케이션으로 라우팅할 수 있습니다. EventBridge는 이벤트를 수집, 필터링, 변환 및 전달하는 간단하고 일관된 방법을 제공하므로 새로운 애플리케이션을 빠르게 빌드할 수 있습니다.” |
|
|
| 관계형 데이터베이스 | “Amazon Relational Database Service(RDS)는 AWS 클라우드에서 관계형 데이터베이스를 더 쉽게 설정, 운영 및 확장할 수 있는 웹 서비스입니다. 이 서비스는 산업 표준 관계형 데이터베이스를 위한 경제적이고 크기 조절이 가능한 용량을 제공하고 공통 데이터베이스 관리 작업을 관리합니다.” |
|
|
| 데이터 원본 사용 안 함 | 데이터 원본 서비스를 사용할 계획이 없다면 none으로 설정할 수 있습니다. 명시적으로는 여전히 데이터 소스로 분류되지만 none 데이터 원본은 저장 매체가 아닙니다. 그럼에도 불구하고 특정 상황에서는 데이터 조작 및 패스스루에 여전히 유용합니다. |
|
작은 정보
데이터 소스가 상호 작용하는 방식에 대한 자세한 내용은 데이터 소스 연결을 AWS AppSync참조하세요. https://docs.aws.amazon.com//appsync/latest/devguide/attaching-a-data-source.html
