기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
사용자 지정 데이터 식별자를 사용하면 Amazon Simple Storage Service(Amazon S3) 객체의 민감한 데이터를 감지하기 위한 사용자 지정 기준을 정의할 수 있습니다. Amazon Macie가 제공하는 관리형 데이터 식별자를 보완하고 조직의 특정 시나리오, 지적 재산 또는 독점 데이터를 반영하는 민감한 데이터를 감지할 수 있습니다.
각 사용자 지정 데이터 식별자는 식별자가 생성하는 조사 결과에 대한 감지 기준 및 선택적으로 심각도 설정을 지정합니다. 감지 기준은 S3 객체에서 일치시킬 텍스트 패턴을 정의하는 정규 표현식을 지정합니다. 또한 이 기준은 결과를 구체화하는 문자 시퀀스와 근접 규칙을 지정할 수 있습니다. 심각도 설정은 조사 결과에 할당할 심각도를 지정합니다. 심각도는 식별자의 감지 기준과 일치하는 텍스트 발생 횟수를 기반으로 할 수 있습니다.
감지 기준
사용자 지정 데이터 식별자를 생성할 때 일치시킬 텍스트 패턴을 정의하는 정규 표현식(정규식)을 지정합니다. 또한 단어 및 구문과 같은 문자 시퀀스와 근접 규칙을 지정하여 결과를 세분화할 수 있습니다. 문자 시퀀스는 정규식과 일치하는 텍스트 근처에 있어야 하는 단어 또는 구문인 키워드이거나 결과에서 제외할 단어 또는 구문인 단어 무시일 수 있습니다.
정규석의 경우 Amazon Macie는 펄 호환 정규 표현식(PCRE) 라이브러리
-
역참조
-
캡처 그룹
-
조건 패턴
-
임베디드 코드
-
글로벌 패턴 플래그(예:
/i,/m및/x) -
재귀 패턴
-
포지티브 및 네가티브 후방탐색 및 전방탐색 제로 폭 어설션(예:
?=,?!,?<=및?<!)
Regex는 최대 512자까지 포함할 수 있습니다.
사용자 지정 데이터 식별자를 위한 효과적인 정규식 패턴을 만들려면 다음 팁과 권장 사항을 참고하세요.
-
패턴이 줄의 시작이나 끝이 아닌 파일의 시작이나 끝에 나타날 것으로 예상되는 경우에만 앵커(
^또는$)를 사용하세요. -
성능상의 이유로 Macie는 제한된 반복 그룹의 크기를 제한합니다. 예를 들어, Macie에서는
\d{100,1000}컴파일되지 않습니다. 다음과 같은 서술형 반복을 사용하면 이 함수의 근사치를 계산할 수 있습니다(예:\d{100,}). -
패턴의 일부를 대소문자를 구분하지 않도록 하려면
/i플래그 대신(?i)구문을 사용할 수 있습니다. -
접두사나 대체를 수동으로 최적화할 필요가 없습니다. 예를 들어
/h(?:ello|i|ey)/를/hello|hi|hey/로 변경해도 성능이 향상되지 않습니다. -
성능상의 이유로 Macie는 반복되는 와일드카드 수를 제한합니다. 예를 들어, Macie에서는
a*b*a*컴파일되지 않습니다.
형식이 잘못되었거나 오래 실행되는 식을 방지하기 위해 Macie는 사용자 지정 데이터 식별자를 생성할 때 샘플 텍스트 모음을 기준으로 정규식 패턴을 자동으로 테스트합니다. 정규식에 문제가 있는 경우 Macie는 문제를 설명하는 오류를 반환합니다.
정규식 외에도 선택적으로 문자 시퀀스와 근접 규칙을 지정하여 결과를 구체화할 수 있습니다.
- 키워드
-
이는는 정규식 패턴과 일치하는 텍스트와 근접해야 하는 특정 문자 시퀀스입니다. 근접성 요구 사항은 S3 객체의 스토리지 형식 또는 파일 유형에 따라 달라집니다.
-
구조화된 열 기반 데이터 - Macie는 텍스트가 정규식 패턴과 일치하고 키워드가 텍스트를 저장하는 필드 또는 열의 이름에 있거나 텍스트 앞에 동일한 필드 또는 셀 값에 있는 키워드의 최대 일치 거리 내에 있는 경우 결과를 포함합니다. Microsoft Excel 통합 문서, CSV 파일 및 TSV 파일이 여기에 해당합니다.
-
구조화된 레코드 기반 데이터 - Macie는 텍스트가 정규식 패턴과 일치하고 텍스트가 키워드의 최대 일치 거리 내에 있는 경우 결과를 포함합니다. 키워드는 텍스트를 저장하는 필드 또는 배열의 경로에 있는 요소 이름에 포함되거나 텍스트를 저장하는 필드 또는 배열에서 동일한 값의 앞에 올 수도 있고 그 값의 일부일 수도 있습니다. Apache Avro 객체 컨테이너, Apache Parquet 파일, JSON 파일 및 JSON 행 파일이 여기에 해당합니다.
-
비정형 데이터 - Macie는 텍스트가 정규식 패턴과 일치하고 텍스트 앞에 키워드의 최대 일치 거리 이내에 있거나 키워드의 최대 일치 거리 내에 있는 경우, 결과를 포함합니다. CSV, JSON, JSON Lines 및 TSV 파일을 제외한 Adobe Portable Document Format 형식 파일, Microsoft Word 문서, 이메일 메시지 및 바이너리가 아닌 텍스트 파일이 여기에 해당합니다. 여기에는 이러한 유형의 파일에 있는 모든 정형 데이터(예: 표)가 포함됩니다.
최대 50개의 키워드를 지정할 수 있습니다. 각 키워드는 3~90개의 UTF-8 문자를 포함할 수 있습니다. 키워드는 대/소문자를 구분하지 않습니다
-
- 최대 일치 거리
-
키워드에 대한 문자 기반 근접성 규칙입니다. Macie는 이 설정을 사용하여 정규식 패턴과 일치하는 텍스트에 대한 키워드가 앞에 있는지 확인합니다. 설정은 전체 키워드의 끝과 정규식 패턴과 일치하는 텍스트의 끝 사이에 존재할 수 있는 최대 문자 수를 정의합니다. Macie는 텍스트가 다음과 같은 경우 결과를 포함합니다.
-
정규식 패턴과 일치
-
하나 이상의 전체 키워드 이후에 발생
-
키워드의 지정된 거리 내에서 발생
그렇지 않으면 Macie는 결과에서 텍스트를 제외합니다.
1~300자의 거리를 지정할 수 있습니다. 기본 거리는 50자입니다. 최상의 결과를 얻으려면 이 거리가 정규식이 감지하도록 설계된 텍스트의 최소 문자 수보다 커야 합니다. 텍스트의 일부만 키워드의 최대 일치 거리 내에 있는 경우 Macie는 결과에 포함하지 않습니다.
-
- 단어 무시
-
이는 결과에서 제외할 특정 문자 시퀀스입니다. 텍스트가 정규식 패턴과 일치하지만 무시 단어가 포함된 경우 Macie는 결과에 포함하지 않습니다.
최대 10개의 단어 무시를 지정할 수 있습니다. 각 단어 무시는 4~90개의 UTF-8 문자를 포함할 수 있습니다. 단어 무시는 대/소문자를 구분합니다.
참고
사용자 지정 데이터 식별자를 생성하기 전에 샘플 데이터로 감지 기준을 테스트하고 구체화하는 것이 좋습니다. 사용자 지정 데이터 식별자는 민감한 데이터 검색 작업에서 사용되므로 사용자 지정 데이터 식별자를 생성한 후에는 변경할 수 없습니다. 이를 통해 수행하는 데이터 프라이버시 및 보호 감사 또는 조사에 대한 민감한 데이터 조사 결과 및 검색 결과에 대한 변경 불가능한 기록이 있는지 확인할 수 있습니다.
Amazon Macie 콘솔 또는 Amazon Macie API를 사용하여 감지 기준을 테스트할 수 있습니다. 콘솔을 사용하여 기준을 테스트하려면 사용자 지정 데이터 식별자를 생성하는 동안 평가 섹션의 옵션을 사용합니다. 프로그래밍 방식으로 기준을 테스트하려면 Amazon Macie API의 TestCustomDataIdentifier 작업을 사용합니다. 를 사용하는 경우 test-custom-data-identifier 명령을 AWS Command Line Interface실행하여 기준을 테스트합니다.
키워드를 사용하여 민감한 데이터를 찾고 오탐을 방지하는 방법에 대한 데모를 보려면 다음 동영상을 시청하세요.
조사 결과의 심각도 설정
사용자 지정 데이터 식별자를 생성할 때 식별자가 생성하는 민감한 데이터 조사 결과에 대한 사용자 지정 심각도 설정을 지정할 수도 있습니다. 기본적으로 Amazon Macie는 사용자 지정 데이터 식별자가 생성하는 모든 조사 결과에 중간 심각도를 할당합니다. S3 객체에 탐지 기준과 일치하는 텍스트가 하나라도 포함되어 있으면 Macie는 자동으로 최종 조사 결과에 중간 심각도를 할당합니다.
사용자 지정 심각도 설정을 사용하면 탐지 기준과 일치하는 텍스트 발생 횟수를 기반으로 할당할 심각도를 지정합니다. 심각도 수준 낮음(가장 낮음), 중간, 높음(가장 심각)의 최대 세 가지 심각도 수준에 대한 발생 임계값을 정의할 수 있습니다. 발생 임곗값은 지정된 심각도의 조사 결과를 생성하기 위해 S3 객체에 존재해야 하는 최소 일치 항목 수입니다. 임곗값을 두 개 이상 지정하는 경우, 임곗값은 심각도에 따라 오름차순으로 낮음에서 높음으로 이동해야 합니다.
예를 들어, 다음 이미지는 Macie가 지원하는 심각도 수준별로 하나씩 총 세 개의 발생 임계값을 지정하는 심각도 설정을 보여줍니다.
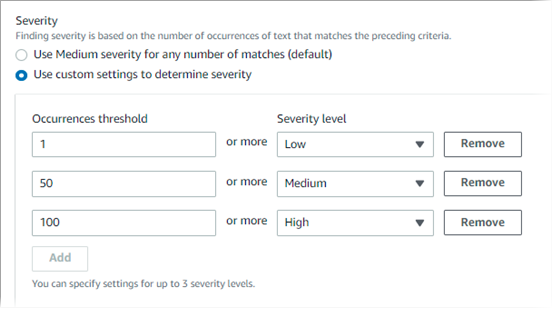
다음 표는 사용자 지정 데이터 식별자가 생성하는 조사 결과의 심각도를 나타냅니다.
| 발생 임곗값 | 심각도 수준 | 결과 |
|---|---|---|
| 1 | 낮음 | S3 객체에 탐지 기준과 일치하는 1~49개의 텍스트가 포함된 경우, 결과적인 조사 결과의 심각도는 낮음입니다. |
| 50 | 중간 | S3 객체에 탐지 기준과 일치하는 텍스트가 50~99개 포함되어 있는 경우, 결과적인 조사 결과의 심각도는 중간입니다. |
| 100 | 높음 | S3 객체에 탐지 기준과 일치하는 텍스트가 100개 이상 포함된 경우, 결과적인 조사 결과의 심각도는 높음입니다. |
또한 심각도 설정을 사용하여 조사 결과를 생성할지 여부를 지정할 수 있습니다. S3 객체의 발생 횟수가 최저 발생 임곗값보다 적은 경우, Macie는 조사 결과를 생성하지 않습니다.
