기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
커넥터 이해
커넥터는 데이터 소스의 스트리밍 데이터를 Apache Kafka 클러스터로 지속적으로 복사하거나 클러스터의 데이터를 데이터 싱크로 지속적으로 복사하여 외부 시스템과 Amazon 서비스를 Apache Kafka와 통합합니다. 커넥터는 데이터를 대상에 전달하기 전에 변환, 형식 변환 또는 데이터 필터링과 같은 간단한 로직을 수행할 수도 있습니다. 소스 커넥터는 데이터 소스에서 데이터를 가져와서 해당 데이터를 클러스터로 푸시하고, 싱크 커넥터는 클러스터에서 데이터를 가져와서 해당 데이터를 데이터 싱크로 푸시합니다.
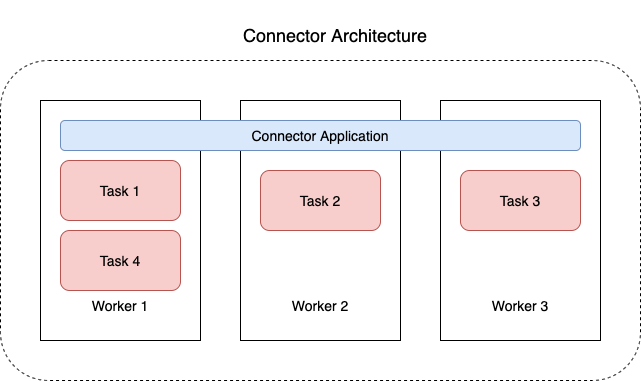
다음 다이어그램은 커넥터의 아키텍처를 보여줍니다. 작업자는 커넥터 로직을 실행하는 Java 가상 머신(JVM) 프로세스입니다. 각 작업자는 병렬 스레드에서 실행되는 일련의 작업을 생성하고 데이터 복사 작업을 수행합니다. 작업은 상태를 저장하지 않으므로 탄력적이고 규모를 조정할 수 있는 데이터 파이프라인을 제공하기 위해 언제든지 시작, 중지 또는 다시 시작할 수 있습니다.