기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
계획 오버헤드 최소화
Apache Spark의 주요 주제에 대해 설명한 대로 Spark 드라이버는 실행 계획을 생성합니다. 이 계획에 따라 분산 처리를 위해 Spark 실행기에 작업이 할당됩니다. 그러나 작은 파일이 많거나에 파티션이 많이 포함된 경우 AWS Glue Data Catalog Spark 드라이버는 병목 현상이 발생할 수 있습니다. 고계획 오버헤드를 식별하려면 다음 지표를 평가하세요.
CloudWatch 지표
다음 상황에서 CPU 로드 및 메모리 사용률을 확인합니다.
-
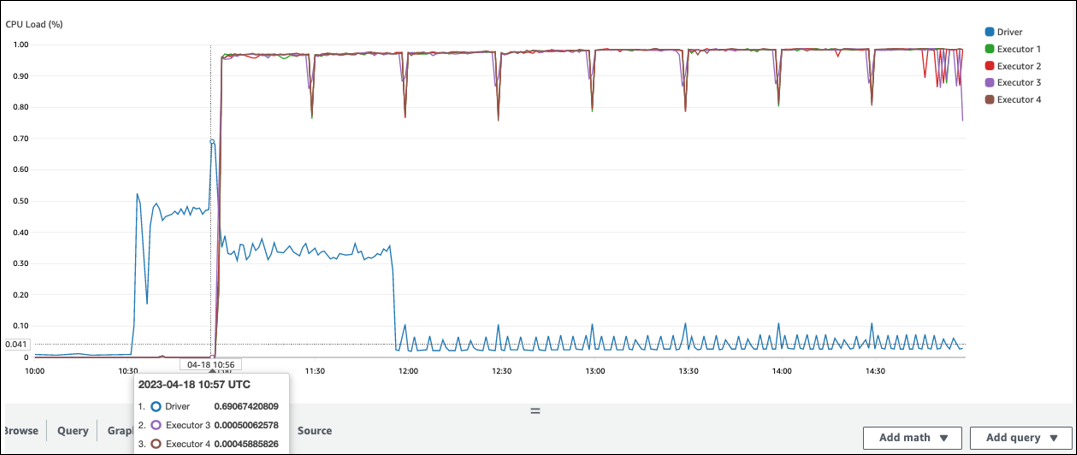
Spark 드라이버 CPU Load 및 Memory Utilization은 높음으로 기록됩니다. 일반적으로 Spark 드라이버는 데이터를 처리하지 않으므로 CPU 로드 및 메모리 사용률이 급증하지 않습니다. 그러나 Amazon S3 데이터 소스에 작은 파일이 너무 많으면 모든 S3 객체를 나열하고 많은 수의 작업을 관리하면 리소스 사용률이 높아질 수 있습니다.
-
Spark 실행기에서 처리가 시작되기 전에 간격이 깁니다. 다음 예제 스크린샷에서는 AWS Glue 작업이 10:00에 시작되었지만 Spark 실행기의 CPU Load가 10:57까지 너무 낮습니다. 이는 Spark 드라이버가 실행 계획을 생성하는 데 오랜 시간이 걸릴 수 있음을 나타냅니다. 이 예제에서는 데이터 카탈로그에서 많은 수의 파티션을 검색하고 Spark 드라이버에서 많은 수의 작은 파일을 나열하는 데 시간이 오래 걸립니다.
Spark UI
Spark UI의 작업 탭에서 제출 시간을 볼 수 있습니다. 다음 예제에서는 Spark 드라이버가 10:00:00에 작업을 시작했지만 10:56:46에 AWS Glue 작업을 시작했습니다.

작업 탭에서 작업(모든 단계): 성공/총 시간을 볼 수도 있습니다. 이 경우 작업 수는 로 기록됩니다58100. 병렬화 작업 페이지의 Amazon S3 섹션에 설명된 대로 작업 수는 대략 S3 객체 수에 해당합니다. 즉, Amazon S3에는 약 58,100개의 객체가 있습니다.
이 작업 및 타임라인에 대한 자세한 내용은 스테이지 탭을 참조하세요. Spark 드라이버에서 병목 현상이 관찰되면 다음 솔루션을 고려하세요.
-
Amazon S3에 파일이 너무 많은 경우 병렬 작업 페이지의 파티션이 너무 많음 섹션에서 과도한 병렬 처리에 대한 지침을 고려하세요.
-
Amazon S3에 파티션이 너무 많으면 데이터 스캔 양 줄이기 페이지의 너무 많은 Amazon S3 파티션 섹션에서 과도한 파티셔닝에 대한 지침을 고려하세요. 데이터 카탈로그에서 파티션 메타데이터를 검색하는 데 걸리는 지연 시간을 줄이기 위해 파티션이 많은 경우 파티션 AWS Glue 인덱스를 활성화합니다. 자세한 내용은 AWS Glue 파티션 인덱스를 사용하여 쿼리 성능 개선을 참조하세요
. -
JDBC에 파티션이 너무 많으면
hashpartition값을 낮춥니다. -
DynamoDB에 파티션이 너무 많으면
dynamodb.splits값을 낮춥니다. -
스트리밍 작업에 파티션이 너무 많으면 샤드 수를 줄입니다.
