기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Data Wrangler 시작하기
Amazon SageMaker Data Wrangler는 Amazon SageMaker Studio Classic의 기능입니다. 이 섹션을 통해 Data Wrangler에 액세스하고 Data Wrangler를 시작하는 방법을 알아보세요. 해결 방법:
-
사전 조건의 각 단계를 완료합니다.
-
Data Wrangler 액세스에 있는 절차에 따라 Data Wrangler 사용을 시작하세요.
사전 조건
Data Wrangler를 사용하기 전에 다음과 같은 사전 조건을 완료해야 합니다.
-
Data Wrangler를 사용하기 위해서는 Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스에 액세스할 수 있어야 합니다. 사용할 수 있는 Amazon EC2 인스턴스에 대한 자세한 내용은 인스턴스 섹션을 참조하세요. 할당량을 확인하고, 필요한 경우, 할당량 증가를 요청하는 방법을 알아보려면 AWS 서비스 할당량을 참조하세요.
-
보안 및 권한에 설명된 필요한 권한을 구성합니다.
-
조직에서 인터넷 트래픽을 차단하는 방화벽을 사용하는 경우 다음 URL에 액세스할 수 있어야 합니다.
-
https://ui.prod-1.data-wrangler.sagemaker.aws/ -
https://ui.prod-2.data-wrangler.sagemaker.aws/ -
https://ui.prod-3.data-wrangler.sagemaker.aws/ -
https://ui.prod-4.data-wrangler.sagemaker.aws/
-
Data Wrangler를 사용하려면 활성 Studio Classic 인스턴스가 필요합니다. 새 인스턴스를 시작하는 방법을 알아보려면 Amazon SageMaker AI 도메인 개요을 참조하세요. Studio Classic 인스턴스가 준비 완료 상태이면 Data Wrangler 액세스의 지침을 사용하세요.
Data Wrangler 액세스
다음 절차는 이미 사전 조건을 완료한 것으로 가정합니다.
Studio Classic에서 Data Wrangler에 액세스하려면 다음을 수행하세요.
-
Studio Classic에 로그인합니다. 자세한 내용은 Amazon SageMaker AI 도메인 개요 단원을 참조하십시오.
-
Studio를 선택합니다.
-
Launch app(앱 시작)을 선택합니다.
-
드롭다운 목록에서 Studio를 선택합니다.
-
홈 아이콘을 선택합니다.
-
Data(데이터)를 선택합니다.
-
Data Wrangler를 선택합니다.
-
또한 다음을 수행하여 Data Wrangler 흐름을 만들 수도 있습니다.
-
상단의 탐색 모음에서 File(파일)을 선택합니다.
-
New(새 파일)를 선택합니다.
-
Data Wrangler Flow를 선택합니다.
-
-
(선택 사항) 새 디렉터리와 .flow 파일의 이름을 변경합니다.
-
Studio Classic에서 새 .flow 파일을 만들면 Data Wrangler를 소개하는 캐러셀이 표시될 수 있습니다.
몇 분 정도 소요될 수 있습니다.
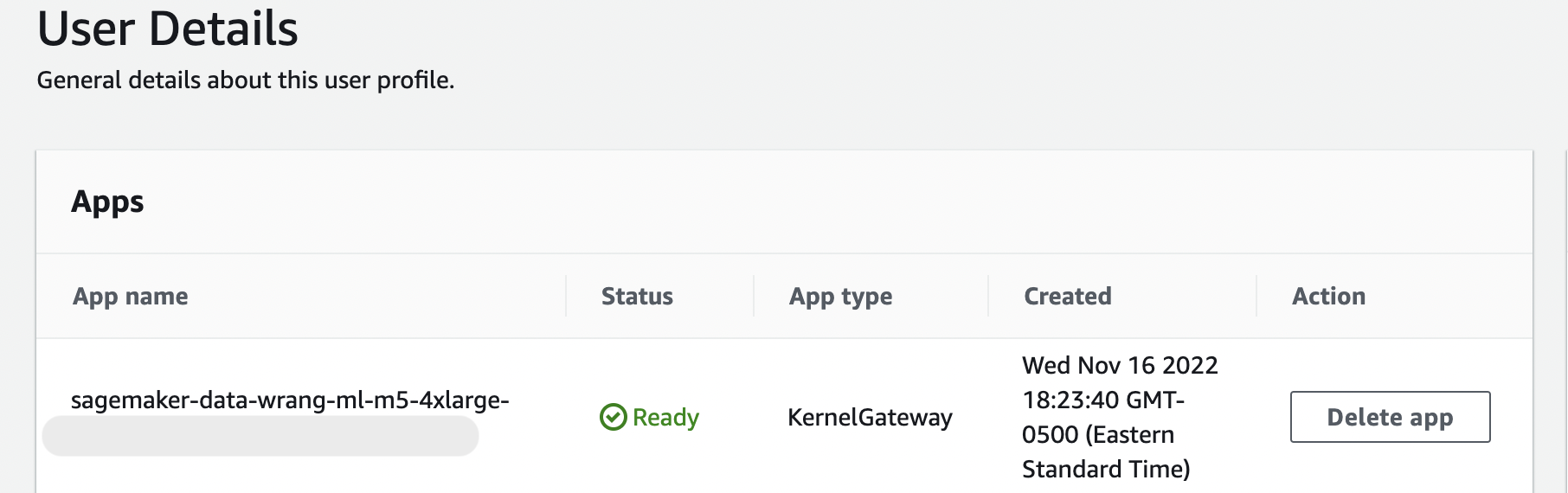
이 메시지는 User Details(사용자 세부 정보) 페이지의 KernelGateway 앱이 보류 중인 한 지속됩니다. 이 앱의 상태를 확인하려면 Amazon SageMaker Studio Classic 페이지의 SageMaker AI 콘솔에서 Studio Classic에 액세스하는 데 사용하는 사용자 이름을 선택합니다. User Details(사용자 세부 정보) 페이지에서 Apps(앱) 아래에 KernelGateway 앱이 있습니다. 이 앱 상태가 Data Wrangler 사용을 시작할 Ready(준비) 될 때까지 기다리세요. Data Wrangler를 처음 시작할 때는 5분 정도 걸릴 수 있습니다.
-
시작하려면 데이터 소스를 선택하고 이를 사용하여 데이터세트를 가져오세요. 자세한 내용은 가져오기 섹션을 참조하세요.
데이터세트를 가져오면 데이터 흐름에 나타납니다. 자세한 내용은 Data Wrangler 흐름을 생성합니다. 섹션을 참조하세요.
-
데이터세트를 가져오면 Data Wrangler는 각 열의 데이터 유형을 자동으로 유추합니다. Data types(데이터 유형) 단계 옆의 +를 선택하고 Edit data types(데이터 유형 편집)을 선택합니다.
중요
Data types(데이터 유형) 단계에 변환을 추가한 후에는 Update types(유형 업데이트)을 사용하여 열 유형을 일괄 업데이트할 수 없습니다.
-
데이터 흐름을 사용하여 변환과 분석을 추가할 수 있습니다. 자세한 내용은 데이터 변환하기 및 분석 및 시각화 섹션을 참조하세요.
-
전체 데이터 흐름을 내보내려면 Export(내보내기)를 선택하고 내보내기 옵션을 선택합니다. 자세한 내용은 내보내기 섹션을 참조하세요.
-
마지막으로 Components and registries(구성 요소 및 레지스트리) 아이콘을 선택하고 드롭다운 목록에서 Data Wrangler를 선택하여 생성한 모든 .flow 파일을 확인합니다. 이 메뉴를 사용하여 데이터 흐름을 찾고 데이터 흐름 간에 이동할 수 있습니다.
Data Wrangler를 시작한 후에는 다음 섹션을 사용하여 Data Wrangler를 사용하여 ML 데이터 준비 흐름을 만드는 방법을 살펴볼 수 있습니다.
Data Wrangler 업데이트
Data Wrangler Studio Classic 앱을 정기적으로 업데이트하여 최신 기능 및 업데이트에 액세스하는 것이 좋습니다. Data Wrangler 앱 이름은 sagemaker-data-wrang으로 시작합니다. Studio Classic 앱을 업데이트하는 방법을 알아보려면 Amazon SageMaker Studio Classic 앱 종료 및 업데이트 섹션을 참조하세요.
데모: Data Wrangler 타이타닉 데이터세트 둘러보기
다음 섹션에서는 Data Wrangler 사용을 시작하는 데 도움이 되는 설명을 제공합니다. 이 연습에서는 사용자가 이미 Data Wrangler 액세스에 있는 단계를 수행했고 데모에 사용할 새 데이터 흐름 파일이 열려 있다고 가정합니다. 이 .flow 파일의 이름을 titanic-demo.flow와 비슷한 이름으로 바꿀 수도 있습니다.
이 안내에서는 Titanic 데이터세트
이 자습서에서는 다음 단계를 수행합니다.
-
다음 중 하나를 수행하세요.
-
Data Wrangler 플로우를 열고 Use Sample Dataset(샘플 데이터세트 사용)을 선택합니다.
-
Titanic Dataset
(타이타닉 데이터세트)를 Amazon Simple S3(Amazon S3)에 업로드한 이 데이터세트를 Data Wrangler로 가져옵니다.
-
-
Data Wrangler analyses(분석)을 사용하여 이 데이터세트를 분석하세요.
-
Data Wrangler data transforms(데이터 변환)을 사용하여 데이터 흐름을 정의합니다.
-
흐름을 Jupyter Notebook으로 내보내 Data Wrangler 작업을 생성하는 데 사용할 수 있습니다.
-
데이터를 처리하고 SageMaker 훈련 작업을 시작하여 XGBoost Binary Classifier(바이너리 분류기)를 훈련시키세요.
데이터세트를 S3에 업로드하고 가져오기
시작하려면 다음 방법 중 하나를 사용하여 타이타닉 데이터세트를 Data Wrangler로 가져올 수 있습니다.
-
Data Wrangler 플로우에서 직접 데이터세트 가져오기
-
Amazon S3에 데이터세트를 업로드한 다음 Data Wrangler로 가져오기
데이터세트를 Data Wrangler로 직접 가져오려면 흐름을 열고 Use Sample Dataset(샘플 데이터세트 사용)을 선택합니다.
Amazon S3에 데이터세트를 업로드하고 Data Wrangler로 가져오는 것은 자체 데이터를 가져오는 것과 비슷합니다. 다음 정보는 데이터세트를 업로드하고 가져오는 방법을 알려줍니다.
Data Wrangler로 데이터를 가져오기 전에 타이타닉 데이터세트
Amazon S3를 처음 사용하는 경우 Amazon S3 콘솔에서 드래그 앤 드롭을 사용하여 이 작업을 수행할 수 있습니다. 방법을 알아보려면 Simple Storage Service User Guide 사용 설명서의 Uploading Files and Folders by Using Drag and Drop(드래그 앤 드롭을 사용한 파일 및 폴더 업로드)를 참조하세요.
중요
이 데모를 완료하는 데 사용할 동일한 AWS 리전의 S3 버킷에 데이터 세트를 업로드합니다.
데이터세트가 Amazon S3에 성공적으로 업로드되면 Data Wrangler로 가져올 수 있습니다.
타이타닉 데이터세트를 Data Wrangler로 가져오기
-
Data flow(데이터 흐름) 탭에서 Import data(데이터 가져오기) 버튼을 선택하거나 Import(가져오기) 탭을 선택합니다.
-
Amazon S3를 선택합니다.
-
Import a dataset from S3(S3에서 데이터세트 가져오기) 테이블을 사용하여 타이타닉 데이터세트를 추가한 버킷을 찾을 수 있습니다. 타이타닉 데이터세트 CSV 파일을 선택하여 Details(세부 정보) 창을 엽니다.
-
Derails(세부 정보)에서 File type(파일 유형)은 CSV여야 합니다. First row is header(첫 번째 행 헤더)를 지정하여 데이터세트의 첫 번째 행이 헤더인지 확인합니다.
Titanic-train와 같이 데이터세트에 좀 더 친숙한 이름을 지정할 수도 있습니다. -
Import(가져오기) 버튼을 선택합니다.
데이터세트를 Data Wrangler로 가져오면 Data Flow(데이터 흐름) 탭에 나타납니다. 노드를 두 번 클릭하여 변환 또는 분석을 추가할 수 있는 노드 세부 정보 보기로 들어갈 수 있습니다. 더하기 아이콘을 사용하여 탐색에 빠르게 액세스할 수 있습니다. 다음 섹션에서는 이 데이터 흐름을 사용하여 분석 및 변환 단계를 추가합니다.
데이터 흐름
데이터 흐름 섹션에서 데이터 흐름의 유일한 단계는 최근에 가져온 데이터세트와 Data type(데이터 유형) 단계입니다. 변환을 적용한 후 이 탭으로 돌아와서 데이터 흐름이 어떻게 되는지 확인할 수 있습니다. 이제 Prepare(준비) 및 Analyze(분석) 탭 아래에서 몇 가지 기본 변환을 추가합니다.
준비 및 시각화
Data Wrangler에는 데이터를 분석, 정리 및 변환하는 데 사용할 수 있는 변환 및 시각화 기능이 내장되어 있습니다.
노드 세부 정보 보기의 Data(데이터) 탭에는 오른쪽 패널에 모든 내장 변환이 나열되며, 이 패널에는 사용자 지정 변환을 추가할 수 있는 영역도 포함되어 있습니다. 다음 사용 사례는 이러한 변환을 사용하는 방법을 보여줍니다.
데이터 탐색과 기능 엔지니어링에 도움이 될 만한 정보를 얻으려면 데이터 품질 및 인사이트 보고서를 만드세요. 보고서의 정보는 데이터를 정리하고 처리하는 데 도움이 될 수 있습니다. 이는 누락된 값의 갯수, 이상치 수 등의 정보를 제공합니다. 대상 누출 또는 불균형과 같은 데이터 관련 문제가 있는 경우 인사이트 보고서를 통해 이러한 문제를 파악할 수 있습니다. 보고서 생성에 대한 자세한 내용은 데이터 및 데이터 품질에 대한 인사이트 확보 섹션을 참조하세요.
데이터 탐색
먼저 분석을 사용하여 데이터 요약 표를 생성합니다. 해결 방법:
-
데이터 흐름의 Data types(데이터 유형) 옆에 있는 +를 선택하고 Add analysis(분석 추가)를 선택합니다.
-
Analysis(분석) 영역의 드롭다운 목록에서 Table summary(표 요약)을 선택합니다.
-
표 요약에 Naame(이름)을 지정합니다.
-
생성될 테이블을 미리 보려면 Preview(미리보기)를 선택합니다.
-
Save(저장)을 선택하여 데이터 흐름에 저장합니다. 표 요약이 All Analyses(모든 분석)에 표시됩니다.
표시되는 통계를 사용하여 이 데이터세트에 대해 다음과 유사한 관찰을 할 수 있습니다.
-
평균 운임(평균)은 약 33달러이고, 최고 요금은 500달러를 넘습니다. 이 열에는 특이치가 있을 수 있습니다.
-
이 데이터세트는 ?를 사용하여 누락된 값을 표시합니다. cabin(객실), embarked(승선 여부), home.dest(집.목적지) 등 여러 열에 누락된 값이 있습니다
-
age(연령) 카테고리에 250개 이상의 값이 누락되었습니다.
다음으로, 이러한 통계에서 얻은 인사이트를 사용하여 데이터를 정리합니다.
미사용 열 삭제
이전 섹션의 분석을 바탕으로 데이터세트를 정리하여 훈련에 사용할 준비를 합니다. 데이터 흐름에 새 변환을 추가하려면 데이터 흐름에서 Data type(데이터 유형) 단계 옆에 있는 +를 선택하고 Add transform(변환 추가)를 선택합니다.
먼저 훈련에 사용하지 않을 열을 삭제합니다. pandas
다음 절차에 따라 미사용 열을 삭제합니다.
사용하지 않는 열을 삭제하려면.
-
Data Wrangler 흐름을 엽니다.
-
Data Wrangler 흐름에는 두 개의 노드가 있습니다. Data types(데이터 유형) 노드 오른쪽에 있는 +를 선택합니다.
-
변환 추가(Add transform)를 선택합니다.
-
All steps(모든 단계) 열에서 Add step(단계 추가)를 선택합니다.
-
Stanard(표준) 변환 목록에서 Manage Columns(열 관리)를 선택합니다. 표준 변환은 미리 만들어진 기본 제공 변환입니다. Drop column(열 삭제)가 선택되어 있는지 확인하세요.
-
Columns to drop(삭제할 열)에서 다음 열 이름을 확인합니다.
-
cabin(객실)
-
ticket(티켓)
-
name(이름)
-
sibsp
-
parch(파치)
-
home.dest(집.목적지)
-
boat(보트)
-
body(시신)
-
-
Preview(미리 보기)를 선택합니다.
-
열이 삭제되었는지 확인한 다음 Add(추가)를 선택합니다.
pandas를 이용하여 이를 실행하려면 다음 단계를 따릅니다.
-
All steps(모든 단계) 열에서 Add step(단계 추가)를 선택합니다.
-
Custom transform(사용자 지정) 변환 목록에서 Custom transform(사용자 지정 변환)을 선택합니다.
-
변환의 이름을 입력하고 드롭다운 목록에서 Python (Pandas)을 선택합니다.
-
코드 상자에 다음 Python 스크립트를 입력합니다.
cols = ['name', 'ticket', 'cabin', 'sibsp', 'parch', 'home.dest','boat', 'body'] df = df.drop(cols, axis=1) -
Preview(미리 보기)를 선택하여 변경 내용을 미리 본 다음 Add(추가)를 선택하여 변환을 추가합니다.
누락된 값 정리
이제 누락된 값을 정리합니다. Handling missing values(누락된 값 처리) 변환 그룹을 사용하여 이 작업을 수행할 수 있습니다.
여러 열에 누락된 값이 있습니다. 나머지 열 중 age(연령) 및 fare(운임)에 누락된 값이 있습니다. Custom Transform(사용자 지정 변환)을 사용하여 이를 검사합니다.
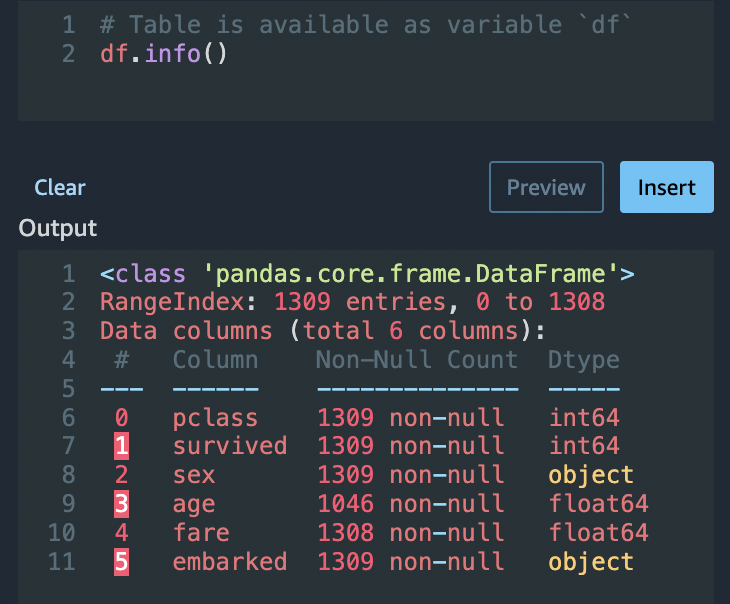
Python(Pandas) 옵션을 사용 시 다음을 사용하여 각 열의 항목 수를 빠르게 검토할 수 있습니다.
df.info()
age(연령) 카테고리에서 누락된 값이 있는 행을 삭제하려면 다음과 같이 하세요.
-
누락 처리(Handle missing)를 선택합니다.
-
트랜스포머에서 누락 시 삭제를 선택합니다.
-
age(연령)을 input column(입력 열)로 선택합니다.
-
Preview(미리 보기)를 선택하여 새 데이터 프레임을 확인한 다음 Add(추가)를 선택하여 흐름에 변환을 추가합니다.
-
fare(운임)에 동일한 프로세스를 반복합니다.
Custom transform(사용자 지정 변환) 섹션의 df.info()을/를 사용하여 행에 모두 1,045개의 값이 있는지 확인할 수 있습니다.
사용자 지정 Pandas: 인코딩
Pandas를 사용하여 플랫 인코딩을 시도해 보세요. 카테고리 데이터 인코딩은 범주를 수치로 표현하는 과정입니다. 예를 들어, 범주가 Dog과 Cat인 경우, 이 정보를 Dog를 대표하는 [1,0]으로 그리고 Cat을 대표하는 [0,1]의 두 벡터로 인코딩할 수 있습니다.
-
Custom Transform(사용자 지정 변환) 섹션의 드롭다운 목록에서 Python (Pandas)를 선택합니다.
-
코드 상자에 다음을 입력합니다.
import pandas as pd dummies = [] cols = ['pclass','sex','embarked'] for col in cols: dummies.append(pd.get_dummies(df[col])) encoded = pd.concat(dummies, axis=1) df = pd.concat((df, encoded),axis=1) -
변경 내용을 미리 보려면 Preview(미리 보기)를 선택합니다. 각 열의 인코딩된 버전이 데이터세트에 추가됩니다.
-
Add(추가)를 선택하여 변환을 추가합니다.
사용자 지정 SQL: 열 선택
이제 SQL을 계속 사용하려는 열을 선택합니다. 이 데모에서는 다음의 SELECT 설명문에 나열된 열을 선택하세요. survived(생존)은 훈련 대상 열이므로 이 열을 먼저 넣으세요.
-
Custom Transform(사용자 지정 변환) 섹션의 드롭다운 목록에서 SQL (PySpark SQL)을 선택합니다.
-
코드 상자에 다음을 입력합니다.
SELECT survived, age, fare, 1, 2, 3, female, male, C, Q, S FROM df; -
변경 내용을 미리 보려면 Preview(미리 보기)를 선택합니다.
SELECT설명문에 나열된 열만 남아 있습니다. -
Add(추가)를 선택하여 변환을 추가합니다.
Data Wrangler 노트북으로 내보내기
데이터 흐름 생성을 완료하면 다양한 내보내기 옵션을 사용할 수 있습니다. 다음 섹션에서는 Data Wrangler 작업 노트북으로 내보내는 방법을 설명합니다. Data Wrangler 작업은 데이터 흐름에 정의된 단계를 사용하여 데이터를 처리하는 데 사용됩니다. 모든 내보내기 옵션에 대한 자세한 내용은 내보내기 섹션을 참조하세요.
Data Wrangler 작업 노트북으로 내보내기
Data Wrangler job(Data Wrangler 작업)을 사용하여 데이터 흐름을 내보내면 프로세스에서 자동으로 Jupyter notebook을 만듭니다. 이 노트북은 Studio Classic 인스턴스에서 자동으로 열리고 SageMaker Processing 작업을 실행하여 Data Wrangler 데이터 흐름을 실행하도록 구성되어 있으며, 이를 Data Wrangler 작업이라고 합니다.
-
데이터 흐름을 저장합니다. File(파일)을 선택한 다음 Save Data Wrangler Flow(Data Wrangler 플로우 저장)을 선택합니다.
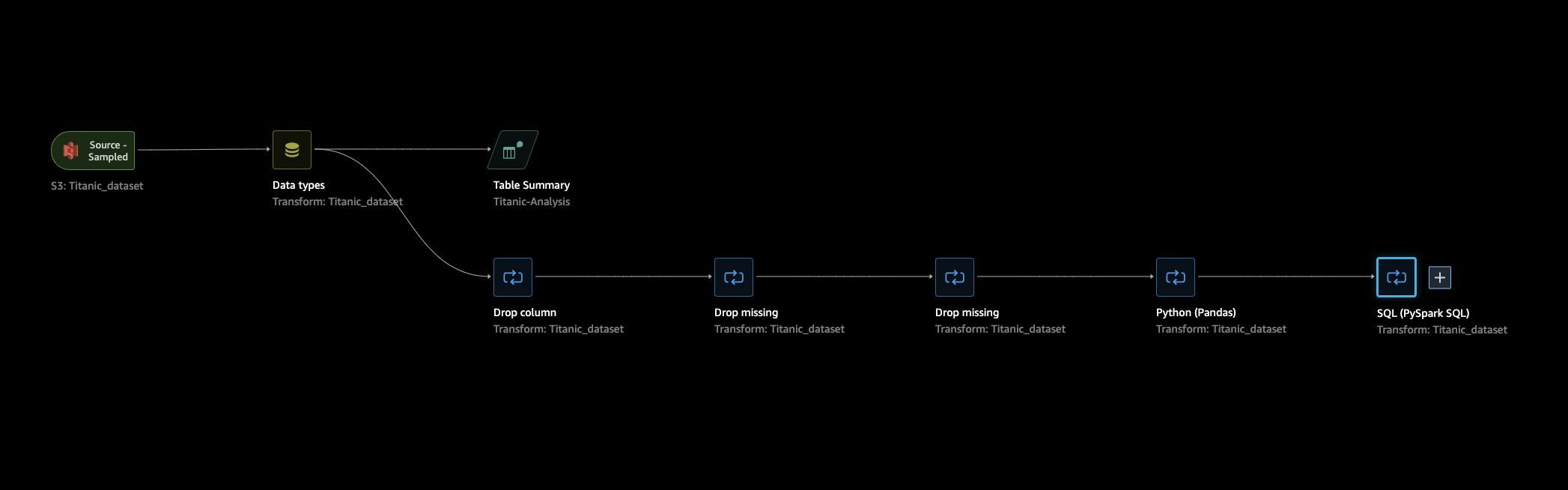
-
Data Flow(데이터 흐름) 탭으로 돌아가서 데이터 흐름(SQL)의 마지막 단계를 선택한 다음 +를 선택하여 탐색을 엽니다.
-
Export(내보내기)를 선택하고 Amazon S3 (via Jupyter Notebook)(Jupyter notebook 사용)을 선택합니다. Jupyter notebook이 열립니다.
-
Kernel(커널)에 사용할 Python 3 (Data Science)(데이터 과학) 커널을 선택합니다.
-
커널이 시작되면 Kick off SageMaker Training Job(SageMaker 훈련 작업 시작)(선택 사항)까지 노트북 북의 셀을 실행합니다.
-
선택적으로, XGBoost 분류자를 훈련하기 위한 SageMaker AI 훈련 작업을 생성하려는 경우 SageMaker 훈련 작업 시작(선택 사항)의 셀을 실행할 수 있습니다. Amazon SageMaker Pricing
(요금)에서 SageMaker 훈련 작업을 실행하는 데 드는 비용을 확인할 수 있습니다. 또는 노트북에 있는 XGBoost 분류자 훈련시키기의 코드 블록을 추가하고 이를 실행하여 XGBoost
오픈 소스 라이브러리를 사용하여 XGBoost 분류자를 훈련할 수 있습니다. -
Cleanup(클린업) 셀의 주석 처리를 제거하고 실행합니다. 이를 실행하여 SageMaker Python SDK를 원래 버전으로 되돌립니다.
SageMaker 콘솔의 처리 중 탭에서 Data Wrangler 작업 상태를 모니터링할 수 있습니다. 또한 Amazon CloudWatch를 사용하여 Data Wrangler 작업을 모니터링할 수 있습니다. 자세한 내용은 CloudWatch 로그 및 지표를 사용하여 Amazon SageMaker 처리 중 작업 모니터링을 참조하세요.
훈련 작업을 시작한 경우 SageMaker 콘솔에서 훈련 섹션의 훈련 작업 아래에서 작업 상태를 모니터링할 수 있습니다.
XGBoost 분류자 훈련시키기
Jupyter notebook 또는 Amazon SageMaker Autopilot을 사용하여 XGBoost 바이너리 분류자를 훈련시킬 수 있습니다. Autopilot을 사용하면 Data Wrangler 흐름에서 직접 변환한 데이터를 기반으로 모델을 자동으로 훈련시키고 조정할 수 있습니다. Autopilot에 대한 자세한 내용은 데이터 플로우에서 모델 자동 훈련하기 섹션을 참조하세요.
Data Wrangler 작업을 시작한 동일한 노트북에서 최소한의 데이터 준비로 준비된 데이터를 이용해 XGBoost 바이너리 분류자를 훈련시킬 수 있습니다.
-
먼저 필요한 모듈을
pip를 이용해 업그레이드하고 _SUCCESS 파일을 제거합니다 (이 마지막 파일은awswrangler의 사용 시 문제가 됩니다).! pip install --upgrade awscli awswrangler boto sklearn ! aws s3 rm {output_path} --recursive --exclude "*" --include "*_SUCCESS*" -
Amazon S3에서 데이터 읽기.
awswrangler를 사용하여 S3 접두사를 가진 모든 CSV 파일을 반복적으로 읽을 수 있습니다. 그런 다음 데이터가 기능과 레이블로 분할됩니다. 레이블은 데이터프레임의 첫 번째 열입니다.import awswrangler as wr df = wr.s3.read_csv(path=output_path, dataset=True) X, y = df.iloc[:,:-1],df.iloc[:,-1]-
마지막으로 DMatrices(데이터에 대한 XGBoost 기본 구조)를 만들고 XGBoost 바이너리 분류자를 사용하여 교차 검증을 수행합니다.
import xgboost as xgb dmatrix = xgb.DMatrix(data=X, label=y) params = {"objective":"binary:logistic",'learning_rate': 0.1, 'max_depth': 5, 'alpha': 10} xgb.cv( dtrain=dmatrix, params=params, nfold=3, num_boost_round=50, early_stopping_rounds=10, metrics="rmse", as_pandas=True, seed=123)
-
Data Wrangler 종료
Data Wrangler 사용을 마치면 추가 요금이 발생하지 않도록 Data Wrangler가 실행되는 인스턴스를 종료하는 것이 좋습니다. Data Wrangler 앱 및 관련 인스턴스를 종료하는 방법을 알아보려면 Data Wrangler 종료 섹션을 참조하세요.
