기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon SageMaker Data Wrangler로 데이터를 가져올 수 있는 데이터 소스는 Amazon Simple Storage Service(S3), Amazon Athena, Amazon Redshift, Snowflake입니다. 가져오는 데이터세트는 최대 1000개의 열을 포함할 수 있습니다.
주제
일부 데이터 소스에서는 여러 데이터 연결을 추가할 수 있습니다.
-
여러 Amazon Redshift 클러스터에 연결할 수 있습니다. 각 클러스터는 데이터 소스가 됩니다.
-
사용자 계정의 Athena 데이터베이스를 쿼리하여 해당 데이터베이스에서 데이터를 가져올 수 있습니다.
데이터 소스에서 가져온 데이터세트는 데이터 흐름에 나타납니다. Data Wrangler는 데이터세트에 있는 각 열의 데이터 유형을 자동으로 유추합니다. 데이터 유형을 수정하려면, 데이터 유형(Data types) 단계를 선택하고 데이터 유형 편집(Edit data types)을 선택합니다.
Athena 또는 Amazon Redshift에서 데이터를 가져오면 가져온 데이터가 Studio Classic을 사용하는 AWS 리전의 기본 SageMaker AI S3 버킷에 자동으로 저장됩니다. 또한 Athena는 Data Wrangler에서 미리 보는 데이터를 이 버킷에 저장합니다. 자세한 내용은 가져온 데이터 스토리지 단원을 참조하세요.
중요
기본 Amazon S3 버킷에는 버킷 정책, 서버측 암호화(SSE)와 같은 최소 허용 보안 설정이 없을 수 있습니다. Data Wrangler로 가져온 데이터세트에 대한 액세스를 제한하는 버킷 정책을 추가할 것을 적극 권장합니다.
중요
또한 SageMaker AI에 관리형 정책을 사용하는 경우 사용 사례를 수행할 수 있는 가장 제한적인 정책으로 범위를 줄이는 것이 좋습니다. 자세한 내용은 Data Wrangler를 사용할 수 있는 IAM 역할 권한 부여 단원을 참조하십시오.
Amazon Simple Storage Service(S3)를 제외한 모든 데이터 소스에서는 데이터를 가져오기 위해 SQL 쿼리를 지정해야 합니다. 개별 쿼리에 대해 다음을 지정해야 합니다.
-
데이터 카탈로그
-
데이터베이스
-
표
드롭다운 메뉴나 쿼리 내에서 데이터베이스 또는 데이터 카탈로그 이름을 지정할 수 있습니다. 다음은 쿼리 예제입니다.
-
select * from- 이 쿼리는 사용자 인터페이스(UI)의 드롭다운 메뉴에 지정된 항목을 사용하여 실행하지 않습니다.example-data-catalog-name.example-database-name.example-table-nameexample-table-name을(를)example-database-name내(example-data-catalog-name내)에서 쿼리합니다. -
select * from- 이 쿼리는 데이터 카탈로그 드롭다운 메뉴에서 실행하도록 지정한 데이터 카탈로그를 사용합니다. 지정한 데이터 카탈로그 내에서example-database-name.example-table-nameexample-table-name을(를)example-database-name내에서 쿼리합니다. -
select * from- 이 쿼리를 실행하려면 데이터 카탈로그와 데이터베이스 이름 드롭다운 메뉴 모두에 대한 필드를 선택해야 합니다.example-table-nameexample-table-name을 데이터베이스 내 데이터 카탈로그와 지정한 데이터 카탈로그 내에서 쿼리합니다.
Data Wrangler와 데이터 소스 간 링크는 연결입니다. 연결을 사용하여 데이터 소스에서 데이터를 가져올 수 있습니다.
연결 유형은 다음과 같습니다.
-
직접
-
카탈로그화
Data Wrangler는 항상 직접 연결을 통해 최신 데이터에 액세스할 수 있습니다. 데이터 소스의 데이터가 업데이트된 경우, 연결을 사용하여 데이터를 가져올 수 있습니다. 예를 들어, Amazon S3 버킷 중 하나에 파일을 추가한 경우 파일을 가져올 수 있습니다.
카탈로그화 연결은 데이터 전송의 결과입니다. 카탈로그화 연결의 데이터가 반드시 최신 데이터를 포함할 필요는 없습니다. 예를 들어, Salesforce와 Amazon S3 간에 데이터 전송을 설정할 수 있습니다. Salesforce 데이터가 업데이트된 경우 데이터를 다시 전송해야 합니다. 데이터 전송 프로세스를 자동화할 수 있습니다. 데이터 전송에 대한 자세한 내용은 서비스형 소프트웨어(SaaS) 플랫폼에서 데이터 가져오기 섹션을 참조하세요.
Amazon S3에서 데이터 가져오기
Amazon Simple Storage Service(S3)를 사용하면 인터넷을 통해 언제 어디서든 원하는 양의 데이터를 저장하고 검색할 수 있습니다. 간단하고 직관적인 웹 인터페이스 AWS Management Console인와 Amazon S3 API를 사용하여 이러한 작업을 수행할 수 있습니다. 데이터세트를 로컬에 저장한 경우, Data Wrangler로 가져오기 위해 S3 버킷에 추가할 것을 권장합니다. 추가 방법은 Amazon Simple Storage Service 사용 설명서에 있는 버킷에 객체 업로드하기에서 확인하세요.
Data Wrangler에서 S3 Select
중요
데이터 흐름을 내보내고 Data Wrangler 작업을 시작하거나, SageMaker AI 특성 저장소로 데이터를 수집하거나, SageMaker AI 파이프라인을 생성하려는 경우 이러한 통합을 위해서는 Amazon S3 입력 데이터가 동일한 AWS 리전에 있어야 합니다.
중요
CSV 파일을 가져오는 경우 다음 요구 사항을 충족하는지 확인하세요.
-
데이터세트에 있는 레코드는 한 줄을 초과할 수 없습니다.
-
백슬래시(
\)가 유일한 유효 이스케이프 문자입니다. -
데이터세트는 다음 구분자 중 하나를 사용해야 합니다.
-
쉼표 -
, -
콜론 -
: -
세미콜론 -
; -
파이프 -
| -
탭 -
[TAB]
-
공간을 절약하기 위해 압축된 CSV 파일을 가져올 수 있습니다.
Data Wrangler로 전체 데이터 세트를 가져오거나 일부만 샘플링할 수 있습니다. Amazon S3의 샘플링 옵션은 다음과 같습니다.
-
없음(None) - 전체 데이터 세트 가져오기.
-
첫 K(First K) - 데이터세트의 첫 K개 행 샘플링. K는 사용자가 지정한 정수.
-
무작위(Randomized) - 지정된 크기의 무작위 샘플 추출.
-
계층화(Stratified) - 계층화된 무작위 샘플 추출. 계층화된 샘플은 열의 값 비율을 유지합니다.
데이터를 가져온 후 샘플링 변환기로 전체 데이터세트에서 하나 이상의 데이터를 취할 수 있습니다. 샘플링 변환기에 대한 자세한 내용은 샘플링 섹션을 참조하세요.
다음 리소스 식별자 중 하나로 데이터를 가져올 수 있습니다.
-
Amazon S3 버킷이나 Amazon S3 액세스 포인트를 사용하는 Amazon S3 URI
-
Amazon S3 액세스 포인트 별칭
-
Amazon S3 액세스 포인트나 Amazon S3 버킷을 사용하는 Amazon 리소스 이름(ARN)
Amazon S3 액세스 포인트는 버킷에 연결된 명명된 네트워크 엔드포인트입니다. 각 액세스 포인트에는 사용자 구성 가능한 고유한 권한 및 네트워크 제어가 있습니다. 액세스 포인트에 대한 자세한 정보는 Amazon S3 액세스 포인트로 데이터 액세스 관리하기에서 확인하세요.
중요
Amazon 리소스 이름(ARN)을 사용하여 데이터를 가져오는 경우 Amazon SageMaker Studio Classic에 액세스하는 데 사용하는 AWS 리전 것과 동일한에 있는 리소스에 대한 이름이어야 합니다.
단일 파일 또는 다중 파일을 데이터세트로 가져올 수 있습니다. 데이터세트가 별도 파일로 파티셔닝된 경우 다중 파일 가져오기가 가능합니다. Amazon S3 디렉터리에 있는 모든 파일을 단일 데이터세트로 가져옵니다. 가져올 수 있는 파일 유형과 파일을 가져오는 방법에 대한 정보는 다음에서 확인하세요.
단일 파일은 다음 형식으로 가져올 수 있습니다.
-
쉼표로 구분된 값(CSV)
-
PARQUET
-
JavaScript Object Notation(JSON)
-
Optimized Row Columnar(ORC)
-
이미지 - Data Wrangler는 OpenCV를 사용하여 이미지를 가져옵니다. 지원되는 이미지 형식에 대한 자세한 정보는 이미지 파일 읽기 및 쓰기
에서 확인하세요.
JSON으로 포맷된 파일의 경우 Data Wrangler는 JSON 라인(.jsonl)과 JSON 문서(.json)를 모두 지원합니다. 데이터를 미리 보면 자동으로 JSON이 표 형식으로 표시됩니다. 5MB를 초과하는 중첩된 JSON 문서의 경우 Data Wrangler는 구조 스키마와 배열을 데이터세트 값으로 표시합니다. 구조화 평탄화(Flatten structured) 및 배열 분해(Explode array) 연산자로 중첩된 값을 표 형식으로 표시할 수 있습니다. 자세한 내용은 JSON 데이터 중첩 해제 및 배열 분해 단원을 참조하세요.
데이터세트를 선택하여 이름을 바꾸고, 파일 유형을 지정하고, 첫 번째 행을 헤더로 식별할 수 있습니다.
Amazon S3 버킷에서 여러 파일로 파티셔닝한 데이터세트를 한 번의 가져오기 단계로 가져올 수 있습니다.
Amazon S3에 저장한 단일 파일에서 데이터세트를 Data Wrangler로 가져오려면
-
현재 위치가 가져오기(Import) 탭이 아닌 경우, 가져오기를 선택합니다.
-
사용 가능(Available) 아래에서 Amazon S3를 선택합니다.
-
S3에서 표, 이미지, 시계열 데이터 가져오기(Import tabular, image, or time-series data from S3)에서 다음 중 한 가지를 실행합니다.
-
표 형식 보기에서 Amazon S3 버킷을 선택하고 가져오려는 파일로 이동합니다.
-
S3 원본(S3 source)에서 Amazon S3 버킷 또는 Amazon S3 URI를 지정하고 이동(Go)을 선택합니다. Amazon S3 URI의 형식은 다음 중 하나일 수 있습니다.
-
s3://amzn-s3-demo-bucket/example-prefix/example-file -
example-access-point-aqfqprnstn7aefdfbarligizwgyfouse1a-s3alias/datasets/example-file -
s3://arn:aws:s3:AWS-Region:111122223333:accesspoint/example-prefix/example-file
-
-
-
데이터세트를 선택하여 가져오기 설정(Import settings) 창을 엽니다.
-
CSV 파일에 헤더가 있는 경우, 표에 헤더 추가(Add header to table) 옆 확인란을 선택합니다.
-
미리보기(Preview) 표로 데이터세트를 미리 볼 수 있습니다. 이 테이블에는 최대 100개의 행이 표시됩니다.
-
세부정보(Details) 창에서 데이터 세트 이름(Name) 및 파일 유형(File Type)을 확인하거나 변경합니다. 공백이 포함된 이름 추가 시, 데이터세트를 가져올 때 공백이 밑줄로 바뀝니다.
-
사용하려는 샘플링 구성을 지정합니다.
-
가져오기를 선택합니다.
파라미터로 패턴과 일치하는 파일의 하위 집합을 가져올 수도 있습니다. 파라미터는 가져올 파일을 보다 선별적으로 고르는데 도움이 됩니다. 파라미터 적용을 시작하려면, 데이터 소스를 편집하고 데이터를 가져올 때 사용하는 경로에 파라미터를 적용합니다. 자세한 내용은 다양한 데이터세트에 데이터 흐름 재사용 단원을 참조하십시오.
Athena에서 데이터 가져오기
Amazon Athena로 Amazon Simple Storage Service(Amazon S3 에서 Data Wrangler로 데이터를 가져올 수 있습니다. Athena에서는 표준 SQL 쿼리를 작성하여 Amazon S3에서 가져오는 데이터를 선택합니다. 자세한 정보는 Amazon Athena란 무엇입니까?에서 확인하세요.
를 사용하여 Amazon Athena AWS Management Console 를 설정할 수 있습니다. 쿼리 실행을 시작하기 전에 Athena에 데이터베이스를 하나 이상 생성해야 합니다. Athena 시작 방법에 대한 자세한 정보는 시작하기에서 확인하세요.
Athena는 Data Wrangler와 직접 통합됩니다. Data Wrangler UI를 종료하지 않고도 Athena 쿼리를 작성할 수 있습니다.
Data Wrangler에서 간단한 Athena 쿼리를 작성하는 것 외에 다음을 사용할 수 있습니다.
-
쿼리 결과 관리용 Athena 작업 그룹 작업 그룹에 대한 자세한 내용은 쿼리 결과 관리 섹션을 참조하세요.
-
데이터 보존 기간 설정을 위한 수명 주기 구성. 보존 기간에 대한 자세한 내용은 데이터 보존 기간 설정 섹션을 참조하세요.
Data Wrangler에서 Athena 쿼리하기
참고
Data Wrangler는 연합 쿼리를 지원하지 않습니다.
Athena AWS Lake Formation 와 함께를 사용하는 경우 Lake Formation IAM 권한이 데이터베이스에 대한 IAM 권한을 재정의하지 않는지 확인합니다sagemaker_data_wrangler.
Data Wrangler로 전체 데이터세트를 가져오거나 일부만 샘플링할 수 있습니다. Athena의 샘플링 옵션은 다음과 같습니다.
-
없음(None) - 전체 데이터 세트 가져오기.
-
첫 K(First K) - 데이터세트의 첫 K개 행 샘플링. K는 사용자가 지정한 정수.
-
무작위(Randomized) - 지정된 크기의 무작위 샘플 추출.
-
계층화(Stratified) - 계층화된 무작위 샘플 추출. 계층화된 샘플은 열의 값 비율을 유지합니다.
다음 절차에서는 Athena에서 Data Wrangler로 데이터세트를 가져오는 방법을 볼 수 있습니다.
Athena에서 Data Wrangler로 데이터세트를 가져오려면
-
Amazon SageMaker AI 콘솔
에 로그인합니다. -
Studio를 선택합니다.
-
Launch app(앱 시작)을 선택합니다.
-
드롭다운 목록에서 Studio를 선택합니다.
-
홈 아이콘을 선택합니다.
-
Data(데이터)를 선택합니다.
-
Data Wrangler를 선택합니다.
-
데이터 가져오기(Import data)을 선택합니다.
-
사용 가능(Available) 아래에서 Amazon Athena를 선택합니다.
-
데이터 카탈로그(Data Catalog)에서 데이터 카탈로그를 선택합니다.
-
데이터베이스(Database) 드롭다운 목록에서 쿼리하려는 데이터베이스를 선택합니다. 데이터베이스를 선택하면 표(Tables)(세부정보(Details) 아래)에서 전체 표를 미리보기할 수 있습니다.
-
(선택 사항) 고급 구성(Advanced configuration)을 선택합니다.
-
작업 그룹(Workgroup)을 선택합니다.
-
작업 그룹이 Amazon S3 출력 위치를 적용하지 않았거나 작업 그룹을 사용하지 않는 경우, 쿼리 결과의 Amazon S3 위치(Amazon S3 location of query results) 값을 지정합니다.
-
(선택 사항) 데이터 보존 기간(Data retention period)에서 확인란을 선택하여 데이터 보존 기간을 설정하고 삭제 전까지 저장할 일수를 지정합니다.
-
(선택 사항) 기본적으로 Data Wrangler는 연결을 저장합니다. 확인란 선택을 해제하여 연결을 저장하지 않을 수 있습니다.
-
-
샘플링(Sampling)에서 샘플링 메서드를 선택합니다. 샘플링을 비활성화하려면 없음(None)을 선택합니다.
-
쿼리 편집기에 쿼리를 입력하고 실행(Run) 버튼을 사용하여 쿼리를 실행합니다. 쿼리가 성공하면 편집기에서 결과를 미리 볼 수 있습니다.
참고
Salesforce 데이터는
timestamptz유형을 사용합니다. Salesforce에서 Athena로 가져온 타임스탬프 열을 쿼리하는 경우 열의 데이터를timestamp유형으로 캐스팅합니다. 다음 쿼리는 타임스탬프 열을 올바른 유형으로 캐스팅합니다.# cast column timestamptz_col as timestamp type, and name it as timestamp_col select cast(timestamptz_col as timestamp) as timestamp_col from table -
쿼리 결과를 가져오려면 가져오기(Import)를 선택합니다.
위 절차를 완료하면 쿼리하여 가져온 데이터세트가 Data Wrangler 흐름에 나타납니다.
기본적으로 Data Wrangler는 연결 설정을 새 연결로 저장합니다. 데이터를 가져오면 이미 지정한 쿼리가 새 연결로 나타납니다. 저장된 연결에는 사용 중인 Athena 작업 그룹 및 Amazon S3 버킷에 대한 정보가 저장됩니다. 데이터 소스에 다시 연결할 때 저장된 연결을 선택할 수 있습니다.
쿼리 결과 관리
Data Wrangler는 Athena 작업 그룹으로 AWS 계정에서 쿼리 결과를 관리할 수 있도록 지원합니다. 개별 작업 그룹의 Amazon S3 출력 위치를 지정할 수 있습니다. 또한 쿼리 출력을 다른 Amazon S3 위치로 보낼 수 있는지 여부도 지정할 수 있습니다. 자세한 정보는 작업 그룹으로 쿼리 액세스 및 비용 제어하기에서 확인하세요.
Amazon S3 쿼리 출력 위치를 적용하도록 작업 그룹을 구성할 수 있습니다. 해당 작업 그룹에 대한 쿼리 결과의 출력 위치는 변경할 수 없습니다.
작업 그룹을 사용하지 않거나 쿼리에 대한 출력 위치를 지정하지 않으면 Data Wrangler는 Studio Classic 인스턴스가 위치한 동일한 AWS 리전에 있는 기본 Amazon S3 버킷을 사용하여 Athena 쿼리 결과를 저장합니다. 이 데이터베이스에 임시 테이블을 생성하여 쿼리 출력을 이 Amazon S3 버킷으로 이동합니다. 데이터를 가져온 후에는 테이블이 삭제되지만 sagemaker_data_wrangler 데이터베이스는 계속 유지됩니다. 자세한 내용은 가져온 데이터 스토리지 단원을 참조하세요.
Athena 작업 그룹을 사용하려면 작업 그룹 액세스 권한을 부여하는 IAM 정책을 설정합니다. SageMaker AI-Execution-Role 사용 시, 역할에 정책을 추가할 것을 권장합니다. 작업 그룹용 IAM 정책에 대한 자세한 정보는 작업 그룹 액세스용 IAM 정책에서 확인하세요. 작업 그룹 정책 예제는 작업 그룹 예제 정책에서 확인하세요.
데이터 보존 기간 설정
Data Wrangler는 쿼리 결과의 데이터 보존 기간을 자동으로 설정합니다. 보관 기간이 지나면 결과는 삭제됩니다. 예를 들어, 기본 보존 기간은 5일입니다. 쿼리 결과는 5일 후에 삭제됩니다. 이 구성은 더 이상 사용하지 않는 데이터를 정리하는 데 도움이 되도록 설계되었습니다. 데이터를 정리하면 권한이 없는 사용자의 액세스를 방지할 수 있습니다. 또한 Amazon S3에 데이터를 저장하는 데 드는 비용을 관리하는 데도 도움이 됩니다.
보존 기간을 설정하지 않으면 Amazon S3 수명 주기 구성에 따라 객체 저장 기간이 결정됩니다. 수명 주기 구성에 대해 지정한 데이터 보존 정책은 지정한 수명 주기 구성보다 오래된 쿼리 결과를 모두 제거합니다. 자세한 내용은 버킷에 대한 수명 주기 구성 설정을 참조하세요.
Data Wrangler는 Amazon S3 수명 주기 구성으로 데이터 보존 및 만료를 관리합니다. Amazon SageMaker Studio Classic IAM 실행 역할 권한을 부여하여 버킷 수명 주기 구성을 관리해야 합니다. 다음 절차에 따라 권한을 부여합니다.
수명 주기 구성 관리 권한을 부여하는 방법은 다음과 같습니다.
-
에 로그인 AWS Management Console 하고 https://console.aws.amazon.com/iam/
IAM 콘솔을 엽니다. -
역할을 선택합니다.
-
검색 창에서 Amazon SageMaker Studio Classic에서 사용 중인 Amazon SageMaker AI 실행 역할을 지정합니다.
-
역할을 선택합니다.
-
권한 추가를 선택합니다.
-
인라인 정책 생성(Create inline policy)을 선택합니다.
-
서비스(Service)에서 S3를 지정하고 선택합니다.
-
읽기(Read) 섹션 아래에서 GetLifecycleConfiguration을 선택합니다.
-
쓰기(Write) 섹션 아래에서 PutLifecycleConfiguration을 선택합니다.
-
리소스에서 특정 항목을 선택합니다.
-
작업(Actions)에서 권한 관리(Permissions management) 옆 화살표 아이콘을 선택합니다.
-
PutResourcePolicy를 선택합니다.
-
리소스에서 특정 항목을 선택합니다.
-
이 계정에서 모두(Any in this account) 옆 확인란을 선택합니다.
-
정책 검토를 선택합니다.
-
이름(Name)에서 이름을 지정합니다.
-
정책 생성(Create policy)을 선택합니다.
Amazon Redshift에서 데이터 가져오기
Amazon Redshift는 클라우드에서 완전히 관리되는 페타바이트급 데이터 웨어하우스 서비스입니다. 데이터 웨어하우스를 생성할 때는 먼저 Amazon Redshift 클러스터라는 노드 집합을 시작하는 것이 첫 번째 단계입니다. 클러스터 프로비저닝을 마치면 데이터세트를 업로드하여 데이터 분석 쿼리를 실행할 수 있습니다.
Data Wrangler에서 하나 이상의 Amazon Redshift 클러스터에 연결하여 쿼리할 수 있습니다. 이 가져오기 옵션을 사용하려면 Amazon Redshift에서 하나 이상의 클러스터를 생성해야 합니다. 생성 방법은 Amazon Redshift 시작하기에서 확인하세요.
다음 중 하나의 위치에서 Amazon Redshift 쿼리 결과를 출력할 수 있습니다.
-
기본 Amazon S3 버킷
-
사용자가 지정하는 Amazon S3 출력 위치
전체 데이터 세트를 가져오거나 데이터 세트의 일부를 샘플링할 수 있습니다. Amazon Redshift의 샘플링 옵션은 다음과 같습니다.
-
없음(None) - 전체 데이터 세트 가져오기.
-
첫 K(First K) - 데이터세트의 첫 K개 행 샘플링. K는 사용자가 지정한 정수.
-
무작위(Randomized) - 지정된 크기의 무작위 샘플 추출.
-
계층화(Stratified) - 계층화된 무작위 샘플 추출. 계층화된 샘플은 열의 값 비율을 유지합니다.
기본 Amazon S3 버킷은 Amazon Redshift 쿼리 결과를 저장하기 위해 Studio Classic 인스턴스가 위치한 리전과 동일한 AWS 리전에 있습니다. 자세한 내용은 가져온 데이터 스토리지 단원을 참조하십시오.
기본 Amazon S3 버킷 또는 지정한 버킷에 대해 다음과 같은 암호화 옵션을 사용할 수 있습니다.
-
Amazon S3 관리형 키를 사용한 기본 AWS 서비스 측 암호화(SSE-S3)
-
지정한 AWS Key Management Service (AWS KMS) 키
AWS KMS 키는 생성 및 관리하는 암호화 키입니다. KMS 키에 대한 자세한 정보는 AWS Key Management Service에서 확인하세요.
계정의 AWS KMS 키 ARN 또는 ARN을 사용하여 키를 지정할 수 있습니다 AWS .
IAM 관리형 정책 AmazonSageMakerFullAccess로 Studio Classic 내 역할에 Data Wrangler 사용 권한을 부여하려면 데이터베이스 사용자 이름에 접두사 sagemaker_access가 있어야 합니다.
다음 절차에 따라 새 클러스터를 추가하는 방법을 알아봅니다.
참고
Data Wrangler는 임시 자격 증명이 있는 Amazon Redshift Data API를 사용합니다. 이 API에 대한 자세한 내용은 Amazon Redshift 관리 안내서에 있는 Amazon Redshift 데이터 API 사용하기에서 확인하세요.
Amazon Redshift 클러스터에 연결하려면
-
Amazon SageMaker AI 콘솔
에 로그인합니다. -
Studio를 선택합니다.
-
Launch app(앱 시작)을 선택합니다.
-
드롭다운 목록에서 Studio를 선택합니다.
-
홈 아이콘을 선택합니다.
-
Data(데이터)를 선택합니다.
-
Data Wrangler를 선택합니다.
-
데이터 가져오기(Import data)을 선택합니다.
-
사용 가능(Available) 아래에서 Amazon Athena를 선택합니다.
-
Amazon Redshift를 선택합니다.
-
임시 자격 증명(IAM)(Temporary credentials (IAM))을 유형(Type)으로 선택합니다.
-
연결 이름(Connection Name)을 입력합니다. 이 이름은 Data Wrangler가 연결을 식별할 때 사용됩니다.
-
클러스터 식별자(Cluster Identifier)를 입력하여 연결하려는 클러스터를 지정합니다. 참고: Amazon Redshift 클러스터의 전체 엔드포인트는 제외하고 클러스터 식별자만 입력합니다.
-
연결할 데이터베이스의 데이터베이스 이름(Database Name)을 입력합니다.
-
데이터베이스 사용자(Database User)를 입력하여 데이터베이스 연결 시 사용할 사용자를 식별합니다.
-
UNLOAD IAM Role에 Amazon Redshift 클러스터가 Amazon S3로 데이터를 이동 및 쓰기 위해 맡아야 역할의 IAM 역할 ARN을 입력합니다. 이 역할에 대한 자세한 내용은 Amazon Redshift 관리 안내서의 Amazon Redshift가 사용자를 대신하여 다른 AWS 서비스에 액세스할 수 있도록 권한을 부여하기를 참조하세요.
-
연결을 선택합니다.
-
(선택 사항) Amazon S3 출력 위치(Amazon S3 output location)에서 쿼리 결과를 저장할 S3 URI를 지정합니다.
-
(선택 사항) KMS 키 ID(KMS key ID)에서 AWS KMS 키 또는 별칭의 ARN을 지정합니다. 다음 이미지에서 AWS Management Console에서 두 키 중 하나를 찾을 수 있는 위치를 볼 수 있습니다.
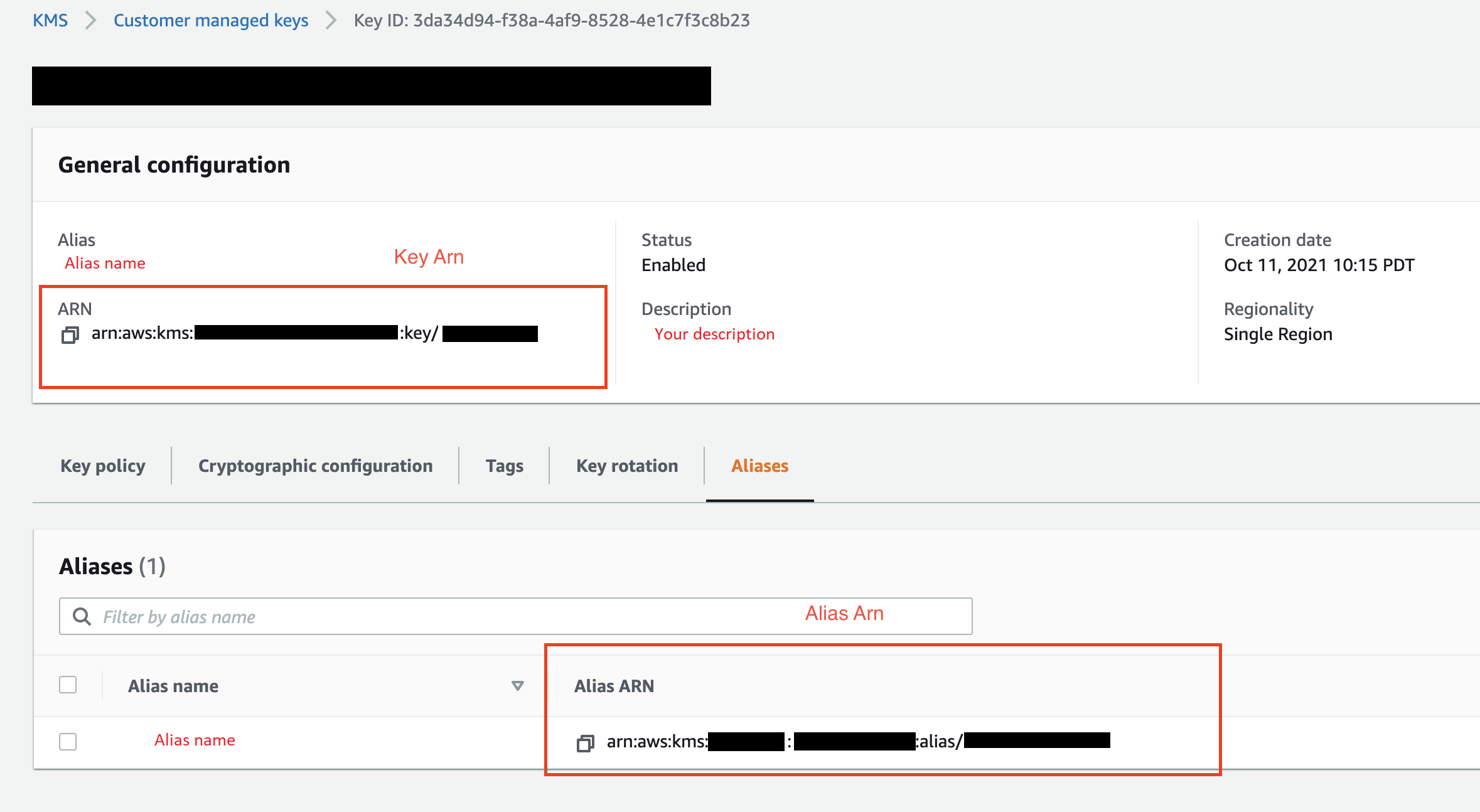
다음 이미지에서 이전 절차의 모든 필드를 볼 수 있습니다.

연결이 성공적으로 설정되면 데이터 가져오기(Data Import) 아래에 데이터 소스로 표시됩니다. 이 데이터 소스를 선택하여 데이터베이스를 쿼리하고 데이터를 가져옵니다.
Amazon Redshift에서 데이터 쿼리 및 가져오기
-
데이터 소스(Data Source)에서 쿼리할 연결을 선택합니다.
-
스키마(Schema)를 선택합니다. Amazon Redshift 스키마에 대한 자세한 내용은 Amazon Redshift 데이터베이스 개발 안내서에 있는 스키마에서 확인하세요.
-
(선택 사항) 고급 구성(Advanced configuration) 아래에서 사용하려는 샘플링(Sampling) 메서드를 지정합니다.
-
쿼리 편집기에서 쿼리를 입력한 다음 실행(Run)을 선택하여 쿼리를 실행합니다. 쿼리가 성공하면 편집기에서 결과를 미리 볼 수 있습니다.
-
데이터세트 가져오기(Import dataset)를 선택하여 쿼리된 데이터세트를 가져옵니다.
-
데이터세트 이름(Dataset name)을 입력합니다. 공백이 포함된 데이터세트 이름 추가 시, 데이터세트를 가져올 때 공백이 밑줄로 바뀝니다.
-
추가를 선택합니다.
데이터세트를 편집하는 방법은 다음과 같습니다.
-
Data Wrangler 흐름으로 이동합니다.
-
원본 - 샘플 추출(Source - Sampled) 옆 +를 선택합니다.
-
가져오려는 데이터를 변경합니다.
-
적용을 선택합니다
Amazon EMR에서 데이터 가져오기
Amazon EMR을 Amazon SageMaker Data Wrangler 흐름의 데이터 소스로 사용할 수 있습니다. Amazon EMR은 대량 데이터를 사용, 처리, 분석할 수 있는 관리형 클러스터 플랫폼입니다. Amazon EMR에 대한 자세한 정보는 Amazon EMR이란 무엇인가요?에서 확인하세요. EMR에서 데이터세트를 가져오려면 연결하고 쿼리해야 합니다.
중요
Amazon EMR 클러스터에 연결하려면 다음 필수 조건을 충족해야 합니다.
사전 조건
-
네트워크 구성
-
Amazon SageMaker Studio Classic 및 Amazon EMR 시작 시 사용하는 Amazon VPC가 리전에 있어야 합니다.
-
Amazon EMR과 Amazon SageMaker Studio Classic은 모두 프라이빗 서브넷에서 시작되어야 합니다. 둘 다 같은 서브넷에 있거나 다른 서브넷에 있을 수 있습니다.
-
Amazon SageMaker Studio Classic이 VPC 전용 모드여야 합니다.
VPC 생성에 대한 자세한 정보는 VPC 생성하기에서 확인하세요.
VPC 만들기에 대한 자세한 정보는 Connect SageMaker Studio Classic Notebooks in a VPC to External Resources에서 확인하세요.
-
실행 중인 Amazon EMR 클러스터는 동일한 Amazon VPC에 있어야 합니다.
-
Amazon EMR 클러스터와 Amazon VPC는 동일한 AWS 계정에 있어야 합니다.
-
Amazon EMR 클러스터는 Hive 또는 Presto를 실행합니다.
-
Hive 클러스터는 포트 10000을 통해 Studio Classic 보안 그룹의 인바운드 트래픽을 허용해야 합니다.
-
Presto 클러스터는 포트 8889을 통해 Studio Classic 보안 그룹의 인바운드 트래픽을 허용해야 합니다.
참고
IAM 역할을 사용하는 Amazon EMR 클러스터의 포트 번호는 다릅니다. 자세한 내용은 필수 조건 끝부분에서 확인하세요.
-
-
-
SageMaker Studio Classic
-
Amazon SageMaker Studio Classic은 Jupyter Lab 버전 3을 실행해야 합니다. Jupyter Lab 버전 업데이트에 대한 정보는 콘솔에서 JupyterLab 버전의 애플리케이션 보기 및 업데이트에서 확인하세요.
-
Amazon SageMaker Studio Classic에는 사용자 액세스를 제어하는 IAM 역할이 있습니다. Amazon SageMaker Studio Classic 실행 시 사용하는 기본 IAM 역할에는 Amazon EMR 클러스터 액세스를 허용하는 정책이 없습니다. IAM 역할에 권한을 부여하는 정책을 연결해야 합니다. 자세한 내용은 Amazon EMR 클러스터 나열 구성 단원을 참조하십시오.
-
또한 IAM 역할에는 다음과 같은
secretsmanager:PutResourcePolicy정책도 연결되어야 합니다. -
이미 만든 Studio Classic 도메인을 사용하는 경우,
AppNetworkAccessType이 VPC 전용 모드인지 확인하세요. VPC 전용 모드로 도메인을 업데이트하는 방법에 대한 정보는 SageMaker Studio Classic 종료 및 업데이트에서 확인하세요.
-
-
Amazon EMR 클러스터
-
클러스터에 Hive 또는 Presto가 설치되어 있어야 합니다.
-
Amazon EMR 릴리스가 버전 5.5.0 이상이어야 합니다.
참고
Amazon EMR은 자동 종료를 지원합니다. 자동 종료는 유휴 클러스터의 실행을 중지하고 비용 발생을 방지합니다. 자동 종료를 지원하는 릴리스는 다음과 같습니다.
-
6.x 릴리스 버전 6.1.0 이상.
-
5.x 릴리스 버전 5.30.0 이상.
-
-
-
IAM 런타임 역할을 사용하는 Amazon EMR 클러스터
-
다음 페이지에서 Amazon EMR 클러스터의 IAM 런타임 역할을 설정합니다. 런타임 역할을 사용하는 경우 전송 중 암호화를 활성화해야 합니다.
-
Lake Formation을 데이터베이스 내 데이터에 대한 거버넌스 도구로 사용해야 합니다. 또한 액세스 제어를 위해 외부 데이터 필터링을 적용해야 합니다.
-
Lake Formation에 대한 자세한 내용은 란 무엇입니까 AWS Lake Formation?를 참조하세요.
-
Lake Formation을 Amazon EMR에 통합하는 방법에 대한 자세한 정보는 타사 서비스와 Lake Formation 통합하기에서 확인하세요.
-
-
클러스터의 버전이 6.9.0 이상이어야 합니다.
-
에 대한 액세스 AWS Secrets Manager. Secrets Manager에 대한 자세한 정보는 AWS Secrets Manager(이)란 무엇입니까?에서 확인하세요.
-
Hive 클러스터는 포트 10000을 통해 Studio Classic 보안 그룹의 인바운드 트래픽을 허용해야 합니다.
-
Amazon VPC는 AWS 클라우드의 다른 네트워크와 논리적으로 격리된 가상 네트워크입니다. Amazon SageMaker Studio Classic과 Amazon EMRR 클러스터는 Amazon VPC 내에서만 존재합니다.
다음 절차에 따라 Amazon VPC에서 Amazon SageMaker Studio Classic을 실행합니다.
VPC에서 Studio Classic을 실행하는 방법은 다음과 같습니다.
-
https://console.aws.amazon.com/sagemaker/
SageMaker AI 콘솔로 이동합니다. -
SageMaker Studio Classic 시작을 선택합니다.
-
표준 설정을 선택합니다.
-
기본 실행 역할에서 Studio Classic 설정 시 필요한 IAM 역할을 선택합니다.
-
Amazon EMR 클러스터를 시작한 VPC를 선택합니다.
-
Subnet(서브넷)에서 프라이빗 서브넷을 선택합니다.
-
보안 그룹(Security group(s))에서 VPC 간 제어 시 사용하는 보안 그룹을 지정합니다.
-
VPC 전용(VPC Only)을 선택합니다.
-
(선택 사항)기본 암호화 키를 AWS 사용합니다. AWS Key Management Service 키를 지정하여 데이터를 암호화할 수도 있습니다.
-
Next(다음)를 선택합니다.
-
Studio 설정(Studio settings)에서 본인에게 가장 적합한 구성을 선택합니다.
-
다음을 선택하여 SageMaker Canvas 설정을 건너뜁니다.
-
다음을 선택하여 RStudio 설정을 건너뜁니다.
Amazon EMR 클러스터가 준비되지 않은 경우, 다음 절차에 따라 생성할 수 있습니다. Amazon EMR에 대한 자세한 정보는 Amazon EMR이란 무엇입니까?에서 확인하세요.
클러스터를 생성하는 방법은 다음과 같습니다.
-
AWS Management Console로 이동합니다.
-
검색창에서
Amazon EMR을 지정합니다. -
클러스터 생성을 선택합니다.
-
클러스터 이름(Cluster name)에 클러스터의 이름을 입력합니다.
-
릴리스(Release)에서 클러스터의 릴리스 버전을 선택합니다.
참고
Amazon EMR은 다음 릴리스에 대해 자동 종료를 지원합니다.
-
6.x 릴리스 버전 6.1.0 이상.
-
5.x 릴리스 버전 5.30.0 이상.
자동 종료는 유휴 클러스터의 실행을 중지하고 비용 발생을 방지합니다.
-
-
(선택 사항) 애플리케이션(Applications)에서 Presto를 선택합니다.
-
클러스터에서 실행 중인 애플리케이션을 선택합니다.
-
네트워킹(Networking) 아래 하드웨어 구성(Hardware configuration)에서 하드웨어 구성 설정을 지정합니다.
중요
네트워킹에서 Amazon SageMaker Studio Classic을 실행하는 VPC를 선택하고 프라이빗 서브넷을 선택합니다.
-
보안 및 액세스(Security and access)에서 보안 설정을 지정합니다.
-
생성(Create)을 선택합니다.
Amazon EMR 클러스터 생성 방법은 Amazon EMR 시작하기에서 확인하세요. 클러스터 구성 모범 사례에 대한 정보는 고려 사항 및 모범 사례에서 확인하세요.
참고
보안상 Data Wrangler는 프라이빗 서브넷에 있는 VPC에만 연결할 수 있습니다. Amazon EMR 인스턴스에를 사용하지 않으면 마스터 노드 AWS Systems Manager 에 연결할 수 없습니다. 자세한 정보는 AWS Systems Manager으(로) EMR 클러스터 액세스 보안 확립하기
현재 다음 방법을 사용하여 Amazon EMR 클러스터에 액세스할 수 있습니다.
-
미 인증
-
LDAP(Lightweight Directory Access Protocol)
-
IAM(런타임 역할)
인증을 사용하지 않거나 LDAP를 사용하려면 여러 클러스터와 Amazon EC2 인스턴스 프로필을 생성해야 할 수 있습니다. 관리자인 경우, 사용자 그룹에 데이터에 대한 다양한 수준의 액세스 권한을 제공해야 할 수 있습니다. 이러한 메서드를 사용하면 관리 오버헤드가 발생하여 사용자 관리가 더 어려워질 수 있습니다.
여러 사용자에게 동일한 Amazon EMR 클러스터 연결 권한을 제공하는 IAM 런타임 역할을 적용할 것을 권장합니다. 런타임 역할은 Amazon EMR 클러스터에 연결하는 사용자에게 할당할 수 있는 IAM 역할입니다. 각 사용자 그룹이 특정한 권한을 갖도록 런타임 IAM 역할을 구성할 수 있습니다.
다음 섹션에 따라 LDAP가 활성화된 Presto 또는 Hive 클러스터를 생성합니다.
중요
를 Presto 테이블의 메타스토어 AWS Glue 로 사용하려면 EMR 클러스터를 시작할 때 Presto 테이블 메타데이터에 사용을 선택하여 Amazon EMR 쿼리의 결과를 AWS Glue 데이터 카탈로그에 저장합니다. 쿼리 결과를 AWS Glue 데이터 카탈로그에 저장하면 요금이 부과되지 않을 수 있습니다.
Amazon EMR 클러스터에서 대규모 데이터세트를 쿼리하려면 Amazon EMR 클러스터의 Presto 구성 파일에 다음 속성을 추가해야 합니다.
[{"classification":"presto-config","properties":{ "http-server.max-request-header-size":"5MB", "http-server.max-response-header-size":"5MB"}}]
Amazon EMR 클러스터를 시작할 때 구성 설정을 수정할 수도 있습니다.
Amazon EMR 클러스터의 구성 파일은 /etc/presto/conf/config.properties 경로 아래에 있습니다.
다음 절차에 따라 LDAP가 활성화된 Presto 클러스터를 생성합니다.
클러스터를 생성하는 방법은 다음과 같습니다.
-
AWS Management Console로 이동합니다.
-
검색창에서
Amazon EMR을 지정합니다. -
클러스터 생성을 선택합니다.
-
클러스터 이름(Cluster name)에 클러스터의 이름을 입력합니다.
-
릴리스(Release)에서 클러스터의 릴리스 버전을 선택합니다.
참고
Amazon EMR은 다음 릴리스에 대해 자동 종료를 지원합니다.
-
6.x 릴리스 버전 6.1.0 이상.
-
5.x 릴리스 버전 5.30.0 이상.
자동 종료는 유휴 클러스터의 실행을 중지하고 비용 발생을 방지합니다.
-
-
클러스터에서 실행 중인 애플리케이션을 선택합니다.
-
네트워킹(Networking) 아래 하드웨어 구성(Hardware configuration)에서 하드웨어 구성 설정을 지정합니다.
중요
네트워킹에서 Amazon SageMaker Studio Classic을 실행하는 VPC를 선택하고 프라이빗 서브넷을 선택합니다.
-
보안 및 액세스(Security and access)에서 보안 설정을 지정합니다.
-
생성(Create)을 선택합니다.
다음 섹션에 따라 이미 생성한 Amazon EMR 클러스터에 LDAP 인증을 적용합니다.
Presto를 실행하는 클러스터에서 LDAP를 사용하려면 HTTPS를 통해 Presto 코디네이터에 액세스해야 합니다. 액세스 권한을 부여하는 방법은 다음과 같습니다.
-
포트 636에서 액세스를 활성화
-
Presto 코디네이터용 SSL 활성화
다음 템플릿에 따라 Presto를 구성합니다.
- Classification: presto-config ConfigurationProperties: http-server.authentication.type: 'PASSWORD' http-server.https.enabled: 'true' http-server.https.port: '8889' http-server.http.port: '8899' node-scheduler.include-coordinator: 'true' http-server.https.keystore.path: '/path/to/keystore/path/for/presto' http-server.https.keystore.key:'keystore-key-password'discovery.uri: 'http://master-node-dns-name:8899' - Classification: presto-password-authenticator ConfigurationProperties: password-authenticator.name: 'ldap' ldap.url: !Sub 'ldaps://ldap-server-dns-name:636' ldap.user-bind-pattern: "uid=${USER},dc=example,dc=org" internal-communication.authentication.ldap.user:"ldap-user-name"internal-communication.authentication.ldap.password:"ldap-password"
Presto에서 LDAP를 설정하는 방법은 다음 리소스에서 확인하세요.
참고
보안상 Presto용 SSL 활성화를 권장합니다. 자세한 정보는 보안 내부 통신
다음 절차에 따라 클러스터에서 데이터를 가져옵니다.
클러스터에서 데이터를 가져오는 방법은 다음과 같습니다.
-
Data Wrangler 흐름을 엽니다.
-
연결 생성을 선택합니다.
-
Amazon EMR을 선택합니다.
-
다음 중 하나를 수행하세요.
-
(선택 사항) 보안 암호 ARN(Secrets ARN)에서 클러스터 내 데이터베이스의 Amazon 리소스 번호(ARN)를 지정합니다. 보안 암호는 보안을 강화합니다. 보안 암호에 대한 자세한 내용은 이란 무엇입니까 AWS Secrets Manager?를 참조하세요. 클러스터용 보안 암호 생성에 대한 자세한 정보는 클러스터의 AWS Secrets Manager 보안 암호 생성에서 확인하세요.
중요
인증 시 IAM 런타임 역할을 사용하는 경우 보안 암호를 지정해야 합니다.
-
드롭다운 테이블에서 클러스터를 선택합니다.
-
-
Next(다음)를 선택합니다.
-
example-cluster-name클러스터 엔드포인트 선택에서 쿼리 엔진을 선택합니다. -
(선택 사항) 연결 저장(Save connection)을 선택합니다.
-
다음, 로그인 선택 후 다음 중 하나를 선택합니다.
-
미 인증
-
LDAP
-
IAM
-
-
example-cluster-name클러스터 로그인에서 클러스터 사용자명과 비밀번호를 지정합니다. -
연결을 선택합니다.
-
쿼리 편집기에서 SQL 쿼리를 지정합니다.
-
Run(실행)을 선택합니다.
-
가져오기를 선택합니다.
클러스터의 AWS Secrets Manager 보안 암호 생성
IAM 런타임 역할로 Amazon EMR 클러스터에 액세스하는 경우, Amazon EMR 액세스 시 사용하는 자격 증명을 Secrets Manager 보안 암호로 저장해야 합니다. 클러스터 액세스 시 사용하는 모든 자격 증명을 보안 암호에 저장합니다.
보안 암호에는 다음 정보를 저장해야 합니다.
-
JDBC 엔드포인트 -
jdbc:hive2:// -
DNS 이름 - Amazon EMR 클러스터의 DNS 이름. 기본 노드의 엔드포인트 또는 호스트 이름.
-
포트 -
8446
보안 암호에 다음과 같은 추가 정보를 저장할 수도 있습니다.
-
IAM 역할 - 클러스터 액세스 시 사용하는 IAM 역할. Data Wrangler는 기본적으로 SageMaker AI 실행 역할을 사용합니다.
-
신뢰 저장소 경로 - 기본적으로 Data Wrangler는 신뢰 저장소 경로를 생성합니다. 자체 신뢰 저장소 경로를 사용할 수도 있습니다. 신뢰 저장소 경로에 대한 자세한 정보는 HiveServer2 내 전송 중 암호화에서 확인하세요.
-
신뢰 저장소 비밀번호 - 기본적으로 Data Wrangler는 신뢰 저장소 비밀번호를 생성합니다. 자체 신뢰 저장소 경로를 사용할 수도 있습니다. 신뢰 저장소 경로에 대한 자세한 정보는 HiveServer2 내 전송 중 암호화에서 확인하세요.
다음 절차에 따라 Secrets Manager 보안 암호에 자격 증명을 저장합니다.
자격 증명을 보안 암호로 저장하는 방법은 다음과 같습니다.
-
AWS Management Console로 이동합니다.
-
검색 창에 Secrets Manager를 지정합니다.
-
AWS Secrets Manager를 선택합니다.
-
새 암호 저장을 선택합니다.
-
보안 암호 유형에서 다른 유형의 보안 암호를 선택합니다.
-
키/값(Key/value) 쌍 아래에서 일반 텍스트(Plaintext)를 선택합니다.
-
Hive 실행 클러스터의 경우, IAM 인증에 다음 템플릿을 사용할 수 있습니다.
{"jdbcURL": "" "iam_auth": {"endpoint": "jdbc:hive2://", #required "dns": "ip-xx-x-xxx-xxx.ec2.internal", #required "port": "10000", #required "cluster_id": "j-xxxxxxxxx", #required "iam_role": "arn:aws:iam::xxxxxxxx:role/xxxxxxxxxxxx", #optional "truststore_path": "/etc/alternatives/jre/lib/security/cacerts", #optional "truststore_password": "changeit" #optional }}참고
데이터를 가져온 후 해당 데이터에 변환을 적용합니다. 그런 다음 변환한 데이터를 특정 위치로 내보냅니다. Jupyter notebook으로 변환된 데이터를 Amazon S3로 내보내는 경우, 이전 예제에서 지정된 신뢰 저장소 경로를 사용해야 합니다.
Secrets Manager 보안 암호는 Amazon EMR 클러스터의 JDBC URL을 보안 암호로 저장합니다. 보안 암호를 사용하는 것이 자격 증명을 직접 입력하는 것보다 안전합니다.
다음 절차에 따라 JDBC URL을 보안 암호로 저장합니다.
JDBC URL을 보안 암호로 저장하는 방법은 다음과 같습니다.
-
AWS Management Console로 이동합니다.
-
검색 창에 Secrets Manager를 지정합니다.
-
AWS Secrets Manager를 선택합니다.
-
새 암호 저장을 선택합니다.
-
보안 암호 유형에서 다른 유형의 보안 암호를 선택합니다.
-
키/값 쌍(Key/value pairs)에서
jdbcURL을(를) 키로, 유효한 JDBC URL을 값으로 지정합니다.유효한 JDBC URL의 형식은 인증 사용 여부 및 쿼리 엔진으로 Hive 또는 Presto 사용 여부에 따라 달라집니다. 다음 목록에는 가능한 여러 구성에 사용할 수 있는 유효한 JBDC URL 형식이 있습니다.
-
Hive, 미 인증 –
jdbc:hive2://emr-cluster-master-public-dns:10000/; -
Hive, LDAP 인증 -
jdbc:hive2://emr-cluster-master-public-dns-name:10000/;AuthMech=3;UID=david;PWD=welcome123; -
SSL이 활성화된 Hive의 경우 JDBC URL 형식은 TLS 구성에 Java Keystore File 사용 여부에 따라 달라집니다. Java Keystore File은 Amazon EMR 클러스터의 마스터 노드 ID를 확인하는 데 도움이 됩니다. Java Keystore File을 사용하려면 EMR 클러스터에서 파일을 생성하고 Data Wrangler에 업로드합니다. 파일을 생성하려면 Amazon EMR 클러스터
keytool -genkey -alias hive -keyalg RSA -keysize 1024 -keystore hive.jks에서 다음 명령을 사용합니다. Amazon EMR 클러스터에서 명령을 실행하는 방법은 AWS Systems Manager(으)로 EMR 클러스터 액세스 보안 확립하기에서 확인하세요. 파일을 업로드하려면 Data Wrangler UI 왼쪽 탐색창에서 위쪽 화살표를 선택합니다. SSL이 활성화된 Hive에 사용할 수 있는 유효한 JDBC URL 형식은 다음과 같습니다.
-
Java Keystore File이 없는 경우 -
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;AllowSelfSignedCerts=1; -
Java Keystore File이 있는 경우 -
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;SSLKeyStore=/home/sagemaker-user/data/Java-keystore-file-name;SSLKeyStorePwd=Java-keystore-file-passsword;
-
-
Presto, 미 인증 – jdbc:presto://
emr-cluster-master-public-dns:8889/; -
LDAP 인증 및 SSL 활성화 Presto의 경우 JDBC URL 형식은 TLS 구성에 Java Keystore File 사용 여부에 따라 달라집니다. Java Keystore File은 Amazon EMR 클러스터의 마스터 노드 ID를 확인하는 데 도움이 됩니다. Java Keystore File을 사용하려면 EMR 클러스터에서 파일을 생성하고 Data Wrangler에 업로드합니다. 파일을 업로드하려면 Data Wrangler UI 왼쪽 탐색창에서 위쪽 화살표를 선택합니다. Presto용 Java Keystore File 생성 방법은 TLS용 Java Keystore File
에서 확인하세요. Amazon EMR 클러스터에서 명령을 실행하는 방법은 AWS Systems Manager(으)로 EMR 클러스터 액세스 보안 확립하기 에서 확인하세요. -
Java Keystore File이 없는 경우 -
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;UID=user-name;PWD=password;AllowSelfSignedServerCert=1;AllowHostNameCNMismatch=1; -
Java Keystore File이 있는 경우 -
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;SSLTrustStorePath=/home/sagemaker-user/data/Java-keystore-file-name;SSLTrustStorePwd=Java-keystore-file-passsword;UID=user-name;PWD=password;
-
-
Amazon EMR 클러스터에서 데이터를 가져오는 과정에서 문제가 발생할 수 있습니다. 문제 해결 방법은 Amazon EMR 관련 문제 해결에서 확인하세요.
Data Bricks에서 데이터 가져오기(JDBC)
Databricks를 Amazon SageMaker Data Wrangler 흐름의 데이터 소스로 사용할 수 있습니다. Databricks에서 데이터세트를 가져오려면 JDBC(Java Database Connectivity) 가져오기 기능으로 Databricks 데이터베이스에 액세스합니다. 데이터베이스에 액세스한 후 데이터를 확보하고 가져오기 위한 SQL 쿼리를 지정합니다.
Databricks 클러스터를 실행 중이고 해당 클러스터에 JDBC 드라이버를 구성했다고 가정합니다. 자세한 정보는 다음 Databricks 설명서에서 확인하세요.
Data Wrangler는 JDBC URL을에 저장합니다 AWS Secrets Manager. Amazon SageMaker Studio Classic IAM 실행 역할 권한을 부여해야 Secrets Manager를 사용할 수 있습니다. 다음 절차에 따라 권한을 부여합니다.
Secrets Manager에게 권한을 부여하는 방법은 다음과 같습니다.
-
에 로그인 AWS Management Console 하고 https://console.aws.amazon.com/iam/
IAM 콘솔을 엽니다. -
역할을 선택합니다.
-
검색 창에서 Amazon SageMaker Studio Classic에서 사용 중인 Amazon SageMaker AI 실행 역할을 지정합니다.
-
역할을 선택합니다.
-
권한 추가를 선택합니다.
-
인라인 정책 생성(Create inline policy)을 선택합니다.
-
서비스(Service)에서 Secrets Manager를 지정하고 선택합니다.
-
작업(Actions)에서 권한 관리(Permissions management) 옆 화살표 아이콘을 선택합니다.
-
PutResourcePolicy를 선택합니다.
-
리소스에서 특정 항목을 선택합니다.
-
이 계정에서 모두(Any in this account) 옆 확인란을 선택합니다.
-
정책 검토를 선택합니다.
-
이름(Name)에서 이름을 지정합니다.
-
정책 생성(Create policy)을 선택합니다.
파티션으로 데이터를 더 빠르게 가져올 수 있습니다. Data Wrangler는 파티션으로 데이터를 병렬 처리할 수 있습니다. 기본적으로 Data Wrangler는 2개의 파티션을 사용합니다. 대부분의 사용 사례에서 2개의 파티션은 거의 최적의 데이터 처리 속도를 제공합니다.
파티션을 2개 이상 지정하기로 선택한 경우 데이터를 파티셔닝할 열을 지정할 수도 있습니다. 열의 값 유형은 숫자 또는 날짜여야 합니다.
데이터 구조와 처리 방식을 이해하는 경우에만 파티션을 적용할 것을 권장합니다.
전체 데이터세트를 가져오거나 데이터세트의 일부를 샘플링할 수 있습니다. Databricks 데이터베이스의 샘플링 옵션은 다음과 같습니다.
-
없음(None) - 전체 데이터세트 가져오기.
-
첫 K(First K) - 데이터세트의 첫 K개 행 샘플링. K는 사용자가 지정한 정수.
-
무작위(Randomized) - 지정된 크기의 무작위 샘플 추출.
-
계층화(Stratified) - 계층화된 무작위 샘플 추출. 계층화된 샘플은 열의 값 비율을 유지합니다.
다음 절차에 따라 Databricks 데이터베이스에서 데이터를 가져옵니다.
Databricks에서 데이터를 가져오는 방법은 다음과 같습니다.
-
Amazon SageMaker AI 콘솔
에 로그인합니다. -
Studio를 선택합니다.
-
Launch app(앱 시작)을 선택합니다.
-
드롭다운 목록에서 Studio를 선택합니다.
-
Data Wrangler 흐름의 데이터 가져오기(Import data) 탭에서 Databricks를 선택합니다.
-
다음 필드를 지정합니다.
-
데이터세트 이름(Dataset name) - Data Wrangler 흐름에 있는 데이터세트에 사용할 이름.
-
드라이버(Driver) – com.simba.spark.jdbc.Driver.
-
JDBC URL – Databricks 데이터베이스의 URL. URL 형식은 Databricks 인스턴스마다 다를 수 있습니다. URL을 찾고 그 내부에서 파라미터를 지정하는 방법은 JDBC 구성 및 연결 파라미터
에서 확인하세요. 다음은 URL 형식을 지정하는 방법에 대한 예제입니다. jdbc:spark://aws-sagemaker-datawrangler.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/3122619508517275/0909-200301-cut318;AuthMech=3;UID= token;PWD=personal-access-token.참고
JDBC URL 자체를 지정하는 대신 JDBC URL이 포함된 보안 ARN을 지정할 수 있습니다. 보안 암호에는
jdbcURL:형식의 키-값 쌍이 포함되어야 합니다. 자세한 정보는 Secrets Manager란 무엇입니까?에서 확인하세요.JDBC-URL
-
-
SQL SELECT 문을 지정합니다.
참고
Data Wrangler는 쿼리 내의 공통 테이블 표현식(CTE) 또는 임시 테이블을 지원하지 않습니다.
-
샘플링(Sampling)에서 샘플링 메서드를 선택합니다.
-
Run(실행)을 선택합니다.
-
(선택 사항) 미리보기(PREVIEW)에서 기어 모양 아이콘을 선택하여 파티션 설정(Partition settings)을 엽니다.
-
파티션 수를 지정합니다. 파티션 수를 지정하면 열별로 파티션을 나눌 수 있습니다.
-
파티션 수 입력(Enter number of partitions) - 2보다 큰 값을 지정합니다.
-
(선택 사항) 열별 파티셔닝(Partition by column) - 다음 필드를 지정합니다. 파티션 수 입력 값을 지정한 경우에만 열별 파티셔닝이 가능합니다.
-
열 선택(Select column) - 데이터 파티션에 사용할 열을 선택합니다. 열의 데이터 유형은 숫자 또는 날짜여야 합니다.
-
상한(Upper bound) - 지정한 열 값 중에서 상한은 파티션에서 사용하는 값입니다. 지정하는 값은 가져오는 데이터를 변경하지 않습니다. 가져오기 속도에만 영향을 줍니다. 최상의 성능을 위해 열의 최대값에 가깝게 상한을 지정합니다.
-
하한(Lower bound) - 지정한 열 값 중에서 하한은 파티션에서 사용하는 값입니다. 지정하는 값은 가져오는 데이터를 변경하지 않습니다. 가져오기 속도에만 영향을 줍니다. 최상의 성능을 위해 열의 최소값에 가깝게 하한을 지정합니다.
-
-
-
-
가져오기를 선택합니다.
Salesforce 데이터 클라우드에서 데이터를 가져옵니다.
Salesforce 데이터 클라우드를 Amazon SageMaker Data Wrangler의 데이터 소스로 사용하여 기계 학습용 Salesforce 데이터 클라우드 데이터를 준비할 수 있습니다.
Salesforce 데이터 클라우드를 Data Wrangler 데이터 소스로 사용하면 코드를 한 줄도 작성하지 않고도 Salesforce 데이터에 빠르게 연결할 수 있습니다. Salesforce 데이터를 Data Wrangler에 있는 다른 데이터 소스 데이터와 조인할 수 있습니다.
데이터 클라우드 연결 후 다음을 수행할 수 있습니다.
-
내장된 시각화로 데이터 시각화
-
데이터 파악 및 잠재적 오류와 극값 식별
-
300개 이상의 내장 변환으로 데이터 변환
-
변환한 데이터 내보내기
관리자 설정
중요
시작하기 전에 사용자가 Amazon SageMaker Studio Classic 버전 1.3.0 이상을 사용하고 있는지 확인하세요. Studio Classic 버전을 확인하고 업데이트하는 방법은 Amazon SageMaker Data Wrangler로 ML 데이터 준비하기에서 확인하세요.
Salesforce Data Cloud 액세스 설정 시 다음 작업을 완료해야 합니다.
-
Salesforce 도메인 URL 가져오기. Salesforce는 도메인 URL을 조직 URL로 참조.
-
Salesforce에서 OAuth 자격 증명 가져오기.
-
Salesforce 도메인의 인증 URL 및 토큰 URL 가져오기.
-
OAuth 구성을 사용하여 AWS Secrets Manager 보안 암호 생성.
-
Data Wrangler가 보안 암호에서 자격 증명을 읽을 때 사용하는 수명 주기 구성 생성.
-
Data Wrangler에 보안 암호 읽기 권한 부여.
이전 작업 수행 후 사용자는 OAuth를 사용하여 Salesforce 데이터 클라우드에 로그인할 수 있습니다.
참고
전체 설정이 완료된 후에도 사용자에게 문제가 발생할 수 있습니다. 문제 해결 방법은 Salesforce 관련 문제 해결에서 확인하세요.
다음 절차에 따라 도메인 URL을 가져옵니다.
-
Salesforce 로그인 페이지로 이동합니다.
-
빠른 찾기(Quick find)에서 내 도메인(My Domain)을 지정합니다.
-
현재 내 도메인 URL(Current My Domain URL) 값을 텍스트 파일에 복사합니다.
-
https://를 URL 시작 부분에 추가합니다.
Salesforce 도메인 URL을 가져온 후 다음 절차에 따라 Salesforce 로그인 자격 증명을 가져와서 Data Wrangler의 Salesforce 데이터 액세스를 허용할 수 있습니다.
Salesforce에서 로그인 자격 증명을 가져와 Data Wrangler에 액세스 권한을 부여하는 방법은 다음과 같습니다.
-
Salesforce 도메인 URL로 이동하여 사용자 계정에 로그인합니다.
-
기어 모양 아이콘을 선택합니다.
-
표시되는 검색 창에서 앱 관리자(App Manager)를 지정합니다.
-
새로 연결된 앱(New Connected App)을 선택합니다.
-
다음 필드를 지정합니다.
-
연결된 앱 이름(Connected App Name) - 이름은 마음대로 지정할 수 있으나, Data Wrangler가 포함된 이름을 선택할 것을 권장합니다. 예를 들어, Salesforce 데이터 클라우드 Data Wrangler 통합으로 지정할 수 있습니다.
-
API 이름(API name) - 기본값을 사용합니다.
-
연락 이메일 주소(Contact Email) - 이메일 주소를 지정합니다.
-
API 헤딩(OAuth 설정 활성화)(API heading(Enable OAuth Settings)) 아래 확인란을 선택하여 OAuth 설정을 활성화합니다.
-
콜백 URL에서 Amazon SageMaker Studio Classic URL을 지정합니다. Studio Classic의 URL을 가져오려면에서 URL에 액세스 AWS Management Console 하고 URL을 복사합니다.
-
-
선택한 OAuth 범위(Selected OAuth Scopes) 아래에서 다음을 사용 가능한 OAuth 범위(Available OAuth Scopes)에서 선택한 OAuth 범위로 옮깁니다.
-
API로 사용자 데이터 관리(
api) -
언제든지 요청 수행(
refresh_token,offline_access) -
Salesforce 데이터 클라우드 데이터에 대해 ANSI SQL 쿼리 수행(
cdp_query_api) -
Salesforce 고객 데이터 플랫폼 프로필 데이터 관리(
cdp_profile_api)
-
-
저장(Save)을 선택합니다. 변경 내용을 저장하면 Salesforce에서 새 페이지가 열립니다.
-
Continue를 선택합니다
-
소비자 키 및 보안 암호(Consumer Key and Secret)로 이동합니다.
-
소비자 세부 정보 관리(Manage Consumer Details)를 선택합니다. Salesforce에서 2단계 인증을 통과해야 할 수도 있는 새 페이지로 리디렉션합니다.
-
중요
소비자 키와 고객 보안키를 텍스트 편집기에 복사합니다. 데이터 클라우드를 Data Wrangler에 연결하려면 이 정보가 필요합니다.
-
연결된 앱 관리(Manage Connected Apps)로 돌아옵니다.
-
연결된 앱 이름과 애플리케이션 이름으로 이동합니다.
-
관리를 선택합니다.
-
정책 편집(Edit Policies)을 선택합니다.
-
IP 완화(IP Relaxation)를 IP 제한 완화(Relax IP restrictions)로 변경합니다.
-
저장(Save)을 선택합니다.
-
Salesforce 데이터 클라우드에 액세스 권한을 부여한 후에는 사용자에게 권한을 부여해야 합니다. 다음 절차에 따라 권한을 부여합니다.
사용자에게 권한을 부여하는 방법은 다음과 같습니다.
-
설정 홈페이지로 이동합니다.
-
왼쪽 탐색창에서 사용자(Users)로 검색하고 사용자 메뉴 항목을 선택합니다.
-
사용자 이름이 포함된 하이퍼링크를 선택합니다.
-
권한 세트 할당(Permission Set Assignments)으로 이동합니다.
-
할당 편집(Edit Assignments)을 선택합니다.
-
다음 권한을 추가합니다.
-
고객 데이터 플랫폼 관리자(Customer Data Platform Admin)
-
고객 데이터 플랫폼 데이터 인지 전문가(Customer Data Platform Data Aware Specialist)
-
-
저장(Save)을 선택합니다.
Salesforce 도메인에 대한 정보를 가져온 후에는 생성 중인 AWS Secrets Manager 보안 암호의 권한 부여 URL과 토큰 URL을 가져와야 합니다.
다음 절차에 따라 권한 부여 URL과 토큰 URL을 가져옵니다.
인증 URL 및 토큰 URL을 가져오려면
-
Salesforce 도메인 URL로 이동합니다.
-
다음 중 한 가지 방법으로 URL을 가져옵니다.
curl과jq이(가) 설치된 Linux 배포판에 있는 경우, Linux에서만 작동하는 메서드를 사용할 것을 권장합니다.-
(Linux 전용) 터미널에서 다음 명령을 지정합니다.
curlsalesforce-domain-URL/.well-known/openid-configuration | \ jq '. | { authorization_url: .authorization_endpoint, token_url: .token_endpoint }' | \ jq '. += { identity_provider: "SALESFORCE", client_id: "example-client-id", client_secret: "example-client-secret" }' -
-
브라우저에서
example-org-URL/.well-known/openid-configuration -
authorization_endpoint과token_endpoint을(를) 텍스트 편집기에 복사합니다. -
다음 JSON 객체를 생성합니다.
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" }
-
-
OAuth 구성 객체를 생성한 후 이를 저장하는 AWS Secrets Manager 보안 암호를 생성할 수 있습니다. 다음 절차에 따라 보안 암호를 생성합니다.
보안 암호를 생성하는 방법은 다음과 같습니다.
-
AWS Secrets Manager 콘솔
로 이동합니다. -
새 보안 암호 저장(Store a new secret)을 선택합니다.
-
다른 유형의 보안 암호(Other type of secrets)를 선택합니다.
-
키/값(Key/value) 쌍 아래에서 일반 텍스트(Plaintext)를 선택합니다.
-
빈 JSON을 다음 구성 설정으로 바꿉니다.
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" } -
Next(다음)를 선택합니다.
-
보안 암호 이름(Secret Name)에서 보안 암호 이름을 지정합니다.
-
태그(Tags) 아래에서 추가(Add)를 선택합니다.
-
키(Key)에서 sagemaker:partner를 지정합니다. 값(Value)은 사용 사례에서 유용할 수 있는 값을 지정할 것을 권장합니다. 어떤 값이든 지정 가능합니다.
중요
키를 생성해야 합니다. 키를 생성하지 않으면 Salesforce에서 데이터를 가져올 수 없습니다.
-
-
Next(다음)를 선택합니다.
-
저장(Store)을 선택합니다.
-
생성한 보안 암호를 선택합니다.
-
다음 필드를 기록해 둡니다.
-
보안 암호의 Amazon 리소스 이름(ARN)
-
보안 암호 이름
-
보안 암호 생성 후, Data Wrangler가 보안 암호를 읽을 수 있는 권한을 추가해야 합니다. 다음 절차에 따라 권한을 추가합니다.
Data Wrangler에 읽기 권한을 추가하는 방법은 다음과 같습니다.
-
Amazon SageMaker AI 콘솔
로 이동합니다. -
도메인을 선택합니다.
-
Data Wrangler 액세스 시 사용하는 도메인을 선택합니다.
-
본인의 사용자 프로필(User Profile)을 선택합니다.
-
세부 정보(Details) 아래에서 실행 역할(Execution role)을 찾습니다. ARN 형식은
arn:aws:iam::111122223333:role/입니다. SageMaker AI 실행 역할을 기록해 둡니다. ARN 내에서는 모든 것이example-rolerole/뒤에 옵니다. -
IAM 콘솔
로 이동합니다. -
IAM 검색 창에서 SageMaker AI 실행 역할의 이름을 지정합니다.
-
역할을 선택합니다.
-
권한 추가를 선택합니다.
-
인라인 정책 생성(Create inline policy)을 선택합니다.
-
JSON 탭을 선택합니다.
-
편집기에서 다음 정책을 지정합니다.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "secretsmanager:GetSecretValue", "secretsmanager:PutSecretValue" ], "Resource": "arn:aws:secretsmanager:*:*:secret:*", "Condition": { "ForAnyValue:StringLike": { "aws:ResourceTag/sagemaker:partner": "*" } } }, { "Effect": "Allow", "Action": [ "secretsmanager:UpdateSecret" ], "Resource": "arn:aws:secretsmanager:*:*:secret:AmazonSageMaker-*" } ] } -
정책 검토를 선택합니다.
-
이름(Name)에서 이름을 지정합니다.
-
정책 생성을 선택합니다.
Data Wrangler에 보안 암호 읽기 권한을 부여한 후에는 Amazon SageMaker Studio Classic 사용자 프로필에 Secrets Manager 보안 암호를 사용하는 수명 주기 구성을 추가해야 합니다.
다음 절차에 따라 수명 주기 구성을 만들고 Studio Classic 프로필에 추가합니다.
수명 주기 구성을 만들고 Studio Classic 프로필에 추가하는 방법은 다음과 같습니다.
-
Amazon SageMaker AI 콘솔로 이동합니다.
-
도메인을 선택합니다.
-
Data Wrangler 액세스 시 사용하는 도메인을 선택합니다.
-
본인의 사용자 프로필(User Profile)을 선택합니다.
-
다음과 같은 애플리케이션이 보이면 삭제합니다.
-
KernelGateway
-
JupyterKernel
참고
애플리케이션을 삭제하면 Studio Classic이 업데이트됩니다. 업데이트 완료 시까지 시간이 걸릴 수 있습니다.
-
-
업데이트 대기중에 수명 주기 구성(Lifecycle configurations)을 선택합니다.
-
현재 페이지에 Studio Classic 수명 주기 구성이 명시되어 있는지 확인합니다.
-
구성 생성을 선택합니다.
-
Jupyter 서버 앱(Jupyter server app) 선택 여부를 확인합니다.
-
Next(다음)를 선택합니다.
-
이름(Name)에서 구성 이름을 지정합니다.
-
스크립트(Scripts)에서 다음 스크립트를 지정합니다.
#!/bin/bash set -eux cat > ~/.sfgenie_identity_provider_oauth_config <<EOL { "secret_arn": "secrets-arn-containing-salesforce-credentials" } EOL -
제출을 선택합니다.
-
왼쪽 탐색창에서 도메인을 선택합니다.
-
도메인을 선택합니다.
-
환경을 선택합니다.
-
개인용 Studio Classic 앱의 수명 주기 구성에서 연결을 선택합니다.
-
기존 구성(Existing configuration)을 선택합니다.
-
Studio Classic 수명 주기 구성 아래에서 만든 수명 주기 구성을 선택합니다.
-
도메인에 연결(Attach to domain)을 선택합니다.
-
연결한 수명 주기 구성 옆 확인란을 선택합니다.
-
기본값으로 설정(Set as default)을 선택합니다.
수명 주기 구성 설정 시 문제가 발생할 수 있습니다. 디버깅 방법은 수명 주기 구성 디버깅에서 확인하세요.
데이터 사이언티스트 안내서
Salesforce 데이터 클라우드를 연결하고 Data Wrangler에 있는 데이터에 액세스하는 방법은 다음과 같습니다.
중요
관리자는 이전 섹션의 정보를 사용하여 Salesforce 데이터 클라우드를 설정해야 합니다. 문제 발생 시 관리자에게 문의하여 문제 해결 지원을 받으세요.
Studio Classic을 열고 버전을 확인하려면 다음 절차를 참조하세요.
-
사전 조건의 단계를 사용하여 Amazon SageMaker Studio Classic을 통해 Data Wrangler에 액세스할 수 있습니다.
-
Studio Classic 시작 시 사용하고자 하는 사용자 옆에서 앱 시작을 선택합니다.
-
Studio를 선택합니다.
Salesforce 데이터 클라우드의 데이터로 Data Wrangler에서 데이터세트를 생성하려면
-
Amazon SageMaker AI 콘솔
에 로그인합니다. -
Studio를 선택합니다.
-
Launch app(앱 시작)을 선택합니다.
-
드롭다운 목록에서 Studio를 선택합니다.
-
홈 아이콘을 선택합니다.
-
Data(데이터)를 선택합니다.
-
Data Wrangler를 선택합니다.
-
데이터 가져오기(Import data)을 선택합니다.
-
사용 가능(Available) 아래에서 Salesforce 데이터 클라우드(Salesforce Data Cloud)를 선택합니다.
-
연결 이름(Connection name)에서 Salesforce 데이터 클라우드 연결 이름을 지정합니다.
-
조직 URL(Org URL)에서 Salesforce 계정의 조직 URL을 지정합니다. URL은 관리자로부터 받을 수 있습니다.
-
연결을 선택합니다.
-
Salesforce 로그인 자격 증명을 지정합니다.
연결 후 Salesforce 데이터 클라우드의 데이터로 데이터세트를 생성할 수 있습니다.
테이블을 선택한 후 쿼리를 작성하고 실행할 수 있습니다. 쿼리 출력은 쿼리 결과(Query results) 아래에 표시됩니다.
쿼리 출력 결정 후 쿼리 결과를 Data Wrangler 흐름으로 가져와 데이터 변환을 수행할 수 있습니다.
데이터세트 생성 후 데이터 흐름(Data flow) 화면으로 이동하여 데이터 변환을 시작합니다.
Snowflake에서 데이터 가져오기
SageMaker Data Wrangler에서 Snowflake를 데이터 소스로 사용하여 Snowflake에서 기계 학습용 데이터를 준비할 수 있습니다.
Data Wrangler에서 Snowflake를 데이터 소스로 사용하면 단 한 줄의 코드도 작성하지 않고도 Snowflake에 빠르게 연결할 수 있습니다. Snowflake 데이터를 Data Wrangler에 있는 다른 데이터 소스 데이터와 조인할 수 있습니다.
연결 후, Snowflake에 저장된 데이터를 대화식으로 쿼리하고, 300개 이상의 미리 구성된 데이터 변환으로 데이터를 변환하고, 미리 구성된 강력한 시각화 템플릿 세트로 데이터를 파악하고 잠재적 오류와 극값을 식별하고, 데이터 준비 워크플로의 불일치를 신속하게 식별하고, 모델을 프로덕션에 배포하기 전에 문제를 진단할 수 있습니다. 마지막으로 Amazon SageMaker Autopilot, Amazon SageMaker 특성 저장소 및 Amazon SageMaker 파이프라인과 같은 다른 SageMaker AI 기능과 함께 사용할 수 있도록 데이터 준비 워크플로를 Amazon S3로 내보낼 수 있습니다. SageMaker Amazon SageMaker Amazon SageMaker Amazon SageMaker
생성한 AWS Key Management Service 키를 사용하여 쿼리의 출력을 암호화할 수 있습니다. 에 대한 자세한 내용은 섹션을 AWS KMS참조하세요AWS Key Management Service.
관리자 안내서
중요
세분화된 액세스 제어 및 모범 사례에 대한 자세한 내용은 보안 액세스 제어
이 섹션은 SageMaker Data Wrangler에서 Snowflake 액세스 설정을 담당하는 Snowflake 관리자를 대상으로 합니다.
중요
관리자는 Snowflake 내 액세스 제어의 관리 및 모니터링을 담당합니다. Data Wrangler는 Snowflake와 관련된 액세스 제어 계층을 추가하지 않습니다.
액세스 제어에는 다음이 포함됩니다.
-
사용자 액세스 데이터
-
(선택 사항) Snowflake에 Amazon S3 버킷에 쿼리 결과를 쓸 수 있는 기능을 제공하는 스토리지 통합
-
사용자가 실행할 수 있는 쿼리
(선택 사항) Snowflake 데이터 가져오기 권한 구성
기본적으로 Data Wrangler는 Amazon S3 위치에 데이터 사본을 생성하지 않고 Snowflake 데이터를 쿼리합니다. Snowflake와 스토리지 통합을 구성하는 경우 다음 정보를 사용합니다. 사용자는 스토리지 통합을 통해 쿼리 결과를 Amazon S3 위치에 저장할 수 있습니다.
사용자마다 민감한 데이터 액세스 수준이 다를 수 있습니다. 데이터 보안 최적화를 위해 개별 사용자에게 자체 스토리지 통합을 제공합니다. 개별 스토리지 통합에는 자체 데이터 거버넌스 정책이 있어야 합니다.
현재 이 기능은 옵트인 리전에서는 사용할 수 없습니다.
Snowflake는 S3 버킷 및 디렉터리에 대해 다음과 같은 권한이 있어야 디렉터리 내 파일에 액세스할 수 있습니다.
-
s3:GetObject -
s3:GetObjectVersion -
s3:ListBucket -
s3:ListObjects -
s3:GetBucketLocation
IAM 정책 생성
Snowflake가 Amazon S3 버킷에서 데이터를 로드 및 언로드하는 액세스 권한을 구성하려면 IAM 정책을 생성해야 합니다.
다음은 정책 생성 시 사용하는 JSON 정책 문서입니다.
# Example policy for S3 write access
# This needs to be updated
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject",
"s3:DeleteObjectVersion"
],
"Resource": "arn:aws:s3:::bucket/prefix/*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::bucket/",
"Condition": {
"StringLike": {
"s3:prefix": ["prefix/*"]
}
}
}
]
}정책 문서로 정책을 생성하는 방법과 절차는 IAM 정책 생성하기에서 확인하세요.
Snowflake에서 IAM 권한을 사용하는 방법에 대한 개요가 있는 설명서는 다음 리소스에서 확인하세요.
데이터 사이언티스트의 Snowflake 역할 사용 권한을 스토리지 통합에 부여하려면 GRANT USAGE ON INTEGRATION
integration_name TO snowflake_role;을 실행해야 합니다.
-
integration_name은 스토리지 통합의 이름입니다. -
snowflake_role은 데이터 사이언티스트 사용자에게 부여되는 기본 Snowflake 역할의 이름입니다.
Snowflake OAuth 액세스 설정하기
사용자가 Data Wrangler에 자격 증명을 직접 입력하도록 하는 대신, ID 제공업체를 통해 Snowflake에 액세스하도록 할 수 있습니다. 다음은 Data Wrangler가 지원하는 ID 제공업체에 대한 Snowflake 설명서로 연결되는 링크입니다.
이전 링크의 설명서를 사용하여ID 제공업체 액세스를 설정합니다. 이 섹션의 정보와 절차는 설명서를 사용하여 Data Wrangler에서 Snowflake에 액세스하는 방법을 이해하는 데 도움이 됩니다.
ID 제공업체는 Data Wrangler를 애플리케이션으로 인식해야 합니다. 다음 절차에 따라 Data Wrangler를 ID 제공업체 내 애플리케이션으로 등록합니다.
-
Data Wrangler를 애플리케이션으로 등록하는 프로세스를 시작하는 구성을 선택합니다.
-
ID 제공업체 사용자에게 Data Wrangler 액세스 권한을 부여합니다.
-
클라이언트 자격 증명을 AWS Secrets Manager 보안 암호로 저장하여 OAuth 클라이언트 인증을 켭니다.
-
https://
domain-ID.studio.AWS 리전.sagemaker.aws/jupyter/default/lab 형식으로 리디렉션 URL을 지정합니다.중요
Amazon SageMaker AI 도메인 ID를 지정하고 Data Wrangler를 실행하는 데를 AWS 리전 사용합니다.
중요
각 Amazon SageMaker AI 도메인과 Data Wrangler를 실행하는 AWS 리전 위치에 대한 URL을 등록해야 합니다. 도메인에서 리디렉션 URLs이 설정되어 있지 AWS 리전 않은 사용자는 자격 증명 공급자를 통해 인증하여 Snowflake 연결에 액세스할 수 없습니다.
-
권한 부여 코드 및 토큰 권한 새로 고침 유형이 Data Wrangler 애플리케이션에서 허용되는지 확인하세요.
ID 제공업체 내에서 사용자 수준에서 OAuth 토큰을 Data Wrangler에 전송하는 서버를 설정해야 합니다. 서버는 Snowflake를 대상으로 토큰을 전송합니다.
Snowflake는 IAM 역할이 사용하는 고유한 역할의 개념을 사용합니다 AWS. Snowflake 계정과 연결된 기본 역할을 사용하려면 어떤 역할이든 사용할 수 있도록 ID 제공업체를 구성해야 합니다. 예를 들어, 사용자의 Snowflake 프로필 내 기본 역할이 systems administrator인 경우, Data Wrangler에서 Snowflake로의 연결 역할은 systems administrator이(가) 됩니다.
다음 절차에 따라 서버를 설정합니다.
서버 설정 방법은 다음과 같습니다. 마지막 단계를 제외한 모든 단계는 Snowflake 내에서 실행됩니다.
-
서버 또는 API 설정을 시작합니다.
-
권한 부여 코드 및 토큰 권한 새로 고침 유형을 사용하도록 권한 부여 서버를 구성합니다.
-
액세스 토큰 전체 기간을 지정합니다.
-
새로 고침 토큰 유휴 제한 시간을 설정합니다. 유휴 제한 시간은 새로 고침 토큰을 사용하지 않을 경우 만료되는 시간입니다.
참고
Data Wrangler에서 작업을 예약하는 경우, 유휴 제한 시간을 처리 작업 빈도보다 길게 설정할 것을 권장합니다. 그렇지 않으면 새로 고침 토큰이 실행되기 전에 만료되어 일부 처리 작업이 실패할 수 있습니다. 새로 고침 토큰이 만료되면 사용자는 Data Wrangler를 통해 Snowflake 연결에 액세스하여 다시 인증해야 합니다.
-
session:role-any을(를) 새 범위로 지정합니다.참고
Azure AD에서 범위의 고유 식별자를 복사합니다. Data Wrangler에 해당 식별자를 입력해야 합니다.
-
중요
Snowflake용 외부 OAuth 보안 통합에서
external_oauth_any_role_mode을(를) 활성화합니다.
중요
Data Wrangler는 교대식 새로 고침 토큰을 지원하지 않습니다. 교대식 새로 고침 토큰을 사용하면 액세스가 실패하거나 사용자가 자주 로그인해야 할 수 있습니다.
중요
새로 고침 토큰이 만료되면 사용자는 Data Wrangler를 통해 Snowflake 연결에 액세스하여 다시 인증해야 합니다.
OAuth 공급자 설정 후, 공급자 연결 시 필요한 정보를 Data Wrangler에 입력합니다. ID 제공업체의 설명서를 사용하여 다음 필드의 값을 가져올 수 있습니다.
-
토큰 URL(Token URL) - ID 제공업체가 Data Wrangler에 보내는 토큰의 URL.
-
권한 부여 URL(Authorization URL) - ID 제공업체의 권한 부여 서버 URL.
-
클라이언트 ID(Client ID) - ID 제공업체의 ID.
-
클라이언트 보안 암호(Client secret) - 권한 부여 서버 또는 API만 인식하는 보안 암호.
-
(Azure AD 전용) 복사한 OAuth 범위 자격 증명다.
필드와 값을 AWS Secrets Manager 보안 암호에 저장하고 Data Wrangler에 사용 중인 Amazon SageMaker Studio Classic 수명 주기 구성에 추가합니다. 수명 주기 구성은 쉘 스크립트입니다. 이것으로 Data Wrangler가 보안 암호의 Amazon 리소스 이름(ARN)에 액세스할 수 있게 합니다. 보안 암호 생성에 대한 자세한 내용은 하드코딩된 보안 암호 이동을 참조하세요 AWS Secrets Manager. Studio Classic에서 수명 주기 구성을 적용하는 방법은 수명 주기 구성을 사용하여 Studio Classic 사용자 지정에서 확인하세요.
중요
Secrets Manager 보안 암호를 생성하기 전에 Amazon SageMaker Studio Classic에 Amazon SageMaker AI 실행 역할에 Secrets Manager에서 보안 암호를 생성하고 업데이트할 수 있는 권한이 있는지 확인합니다. 권한 추가에 대한 자세한 정보는 예: 보안 암호 생성 권한에서 확인하세요.
Okta 및 Ping Federate의 보안 암호 형식은 다음과 같습니다.
{
"token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token",
"client_id":"example-client-id",
"client_secret":"example-client-secret",
"identity_provider":"OKTA"|"PING_FEDERATE",
"authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize"
}
Azure AD의 보안 암호 형식은 다음과 같습니다.
{
"token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token",
"client_id":"example-client-id",
"client_secret":"example-client-secret",
"identity_provider":"AZURE_AD",
"authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize",
"datasource_oauth_scope":"api://appuri/session:role-any)"
}
생성한 Secrets Manager 보안 암호를 사용하는 수명 주기 구성이 있어야 합니다. 수명 주기 구성을 생성하거나 이미 생성된 구성을 수정할 수 있습니다. 구성에는 다음 스크립트를 사용해야 합니다.
#!/bin/bash set -eux ## Script Body cat > ~/.snowflake_identity_provider_oauth_config <<EOL { "secret_arn": "example-secret-arn" } EOL
수명 주기 구성 설정 방법은 수명 주기 구성 생성 및 연결에서 확인하세요. 설정 프로세스를 진행하는 방법은 다음과 같습니다.
-
구성의 애플리케이션 유형을
Jupyter Server(으)로 설정합니다. -
사용자가 있는 Amazon SageMaker AI 도메인에 구성을 연결합니다.
-
구성이 기본적으로 실행하도록 합니다. 사용자가 Studio Classic에 로그인할 때마다 실행되어야 합니다. 그렇지 않으면 사용자가 Data Wrangler를 사용할 때 구성에 저장된 자격 증명을 사용할 수 없습니다.
-
수명 주기 구성은 사용자의 홈 폴더에서
snowflake_identity_provider_oauth_config(이)라는 이름의 파일을 생성합니다. 이 파일에는 Secrets Manager 보안 암호가 있습니다. Jupyter 서버 인스턴스가 초기화될 때마다 해당 파일이 사용자의 홈 폴더에 있는지 확인하세요.
를 통한 Data Wrangler와 Snowflake 간의 프라이빗 연결 AWS PrivateLink
이 섹션에서는 AWS PrivateLink 를 사용하여 Data Wrangler와 Snowflake 간에 프라이빗 연결을 설정하는 방법을 설명합니다. 다음 섹션에 단계별 설명이 있습니다.
VPC 생성
VPC를 설정하지 않은 경우, 새 VPC 생성 지침에 따라 생성합니다.
프라이빗 연결 설정 시 사용할 VPC를 선택한 후, Snowflake 관리자에게 다음 자격 증명을 제공하여 AWS PrivateLink을(를) 활성화합니다.
-
VPC ID
-
AWS 계정 ID
-
Snowflake 액세스 시 사용하는 관련 계정 URL
중요
Snowflake 설명서의 설명대로 Snowflake 계정 활성화는 최대 2영업일이 소요될 수 있습니다.
Snowflake AWS PrivateLink 통합 설정
AWS PrivateLink 가 활성화되면 Snowflake 워크시트에서 다음 명령을 실행하여 리전의 AWS PrivateLink 구성을 검색합니다. Snowflake 콘솔에 로그인하고 워크시트(Worksheets) 아래에 select
SYSTEM$GET_PRIVATELINK_CONFIG();을(를) 입력합니다.
-
결과 JSON 객체에서
privatelink-account-name,privatelink_ocsp-url,privatelink-account-url,privatelink_ocsp-url값을 검색합니다. 개별 값의 예는 다음 코드 조각에 있습니다. 이 값을 저장했다가 나중에 사용합니다.privatelink-account-name: xxxxxxxx.region.privatelink privatelink-vpce-id: com.amazonaws.vpce.region.vpce-svc-xxxxxxxxxxxxxxxxx privatelink-account-url: xxxxxxxx.region.privatelink.snowflakecomputing.com privatelink_ocsp-url: ocsp.xxxxxxxx.region.privatelink.snowflakecomputing.com -
AWS 콘솔로 전환하고 VPC 메뉴로 이동합니다.
-
왼쪽 창에서 엔드포인트(Endpoints) 링크를 선택하여 VPC 엔드포인트(VPC Endpoints) 설정으로 이동합니다.
그 곳에서 엔드포인트 생성(Create Endpoint)을 선택합니다.
-
다음 스크린샷과 같이 이름별 서비스 찾기(Find service by name) 라디오 버튼을 선택합니다.

-
서비스 이름(Service Name) 필드에 이전 단계에서 검색한
privatelink-vpce-id값을 붙여넣고 검증(Verify)을 선택합니다.정상적으로 연결되면 다음 스크린샷과 같이 서비스 이름 찾음(Service name found)이라는 녹색 알림 메시지가 화면에 나타나고 VPC 및 서브넷(Subnet) 옵션이 자동으로 확장됩니다. 대상 리전에 따라 결과 화면에 다른 AWS 리전 이름이 표시될 수 있습니다.

-
VPC 드롭다운 목록에서 Snowflake로 전송한 것과 동일한 VPC ID를 선택합니다.
-
서브넷을 아직 생성하지 않은 경우, 다음 지침에 따라 서브넷을 생성합니다.
-
서브넷을 VPC 드롭다운 목록에서 선택합니다. 그 다음에 서브넷 생성(Create subnet)을 선택하고 프롬프트에 따라 VPC에 서브셋을 생성합니다. Snowflake를 전송한 VPC ID를 선택해야 합니다.
-
보안 그룹 구성(Security Group Configuration) 아래에서 새 보안 그룹 생성(Create New Security Group)을 선택하여 새 탭에서 기본 보안 그룹(Security Group) 화면을 엽니다. 이 새 탭에서 보안 그룹 생성(Create Security Group)을 선택합니다.
-
보안 그룹 이름(예:
datawrangler-doc-snowflake-privatelink-connection)과 설명을 입력합니다. 이전 단계에서 사용한 VPC ID를 선택해야 합니다. -
VPC 내에서 이 VPC 엔드포인트로 들어오는 트래픽을 허용하는 두 가지 규칙을 추가합니다.
별도 탭에서 VPC(Your VPCs) 아래에 있는 VPC로 이동하여 VPC의 CIDR 블록을 검색합니다. 그 다음에 규칙 추가(Add Rule)를 인바운드 규칙(Inbound Rules) 섹션에서 선택합니다.
HTTPS유형을 선택하고, 양식에서 소스를 사용자 지정으로 둔 다음, 이전describe-vpcs호출에서 검색된 값(예:10.0.0.0/16)을 붙여넣습니다. -
보안 그룹 생성을 선택합니다. 보안 그룹 ID(Security Group ID)를 새로 생성된 보안 그룹(예:
sg-xxxxxxxxxxxxxxxxx)에서 검색합니다. -
VPC 엔드포인트 구성 화면에서 기본 보안 그룹을 제거합니다. 검색 필드에 보안 그룹 ID를 붙여넣고 확인란을 선택합니다.

-
엔드포인트 생성을 선택합니다.
-
엔드포인트가 정상적으로 생성되면 VPC ID로 지정된 VPC 엔드포인트 구성으로 연결되는 링크가 있는 페이지가 표시됩니다. 링크를 선택하여 전체 구성을 봅니다.
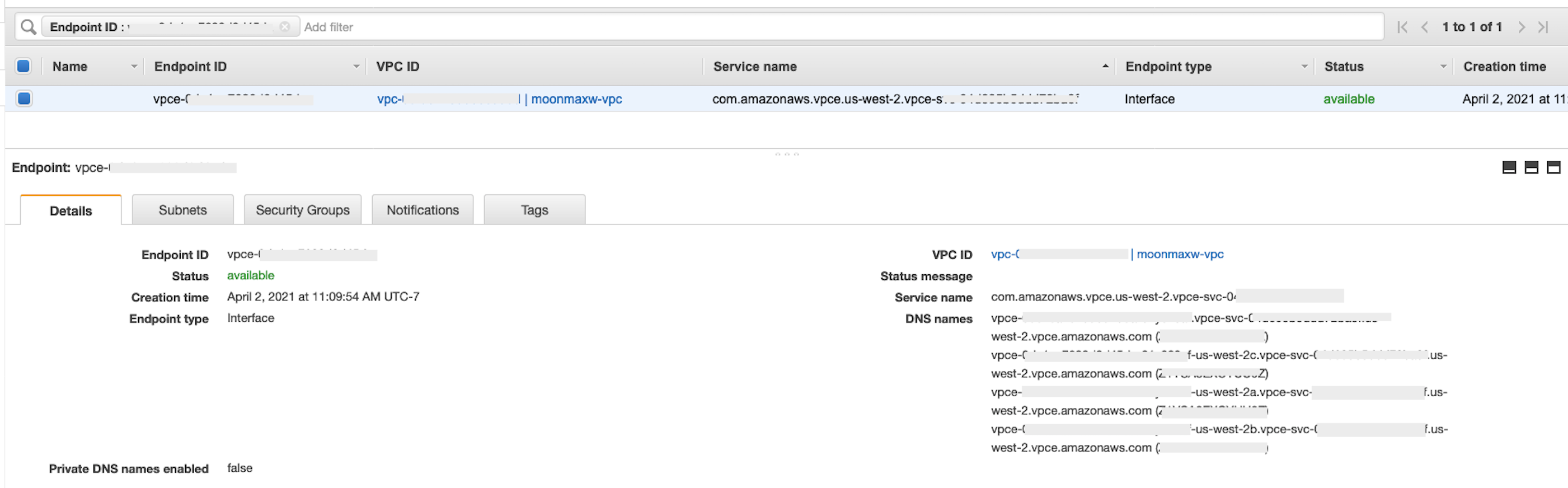
DNS 이름 목록에서 맨 위에 있는 레코드를 검색합니다. 지역 이름(예:
us-west-2)만 포함하고 가용 영역 문자 표기(예:us-west-2a)가 없기 때문에 기타 DNS 이름과 구별할 수 있습니다. 이 정보를 저장했다가 나중에 사용합니다.
VPC에서 Snowflake 엔드포인트 DNS 구성하기
이 섹션에는 VPC에서 Snowflake 엔드포인트 DNS를 구성하는 방법에 대한 설명이 있습니다. 이를 통해 VPC가 Snowflake AWS PrivateLink 엔드포인트에 대한 요청을 해결할 수 있습니다.
-
AWS 콘솔에서 Route 53 메뉴
로 이동합니다. -
호스팅 영역(Hosted Zones) 옵션을 선택합니다(필요 시, 왼쪽 메뉴를 확장하면 이 옵션을 찾을 수 있음).
-
Create Hosted Zone(호스팅 영역 생성)을 선택합니다.
-
도메인 이름(Domain name) 필드에서 이전 단계에서 저장한
privatelink-account-url값을 참조합니다. 이 필드에서는 Snowflake 계정 ID가 DNS 이름에서 제거되고 리전 식별자로 시작하는 값만 사용합니다. 리소스 레코드 세트(Resource Record Set)도region.privatelink.snowflakecomputing.com같은 하위 도메인용으로 나중에 생성됩니다. -
프라이빗 호스팅 영역(Private Hosted Zone) 라디오 버튼을 유형(Type) 섹션에서 선택합니다. 리전 코드는
us-west-2이(가) 아닐 수 있습니다. Snowflake가 반환한 DNS 이름을 참조합니다.
-
호스팅 영역과 연결할 VPC(VPCs to associate with the hosted zone) 섹션에서 VPC가 위치한 리전과 이전 단계에서 사용한 VPC ID를 선택합니다.

-
호스팅 영역 생성(Create hosted zone)을 선택합니다.
-
-
다음으로,
privatelink-account-url과privatelink_ocsp-url에 대한 레코드를 각각 하나씩 생성합니다.-
호스팅 영역 메뉴에서 레코드 세트 생성(Create Record Set)을 선택합니다.
-
레코드 이름(Record name) 아래에 Snowflake 계정 ID만 입력합니다(
privatelink-account-url의 첫 8자). -
레코드 유형(Record type)에서 CNAME을 선택합니다.
-
값(Value) 아래에 Snowflake AWS PrivateLink 통합 설정 섹션의 마지막 단계에서 검색한 리전 VPC 엔드포인트의 DNS 이름을 입력합니다.

-
레코드 생성을 선택합니다.
-
privatelink-ocsp-url(으)로 표시한 OCSP 레코드에 대해ocsp부터 레코드 이름의 8자 Snowflake ID(예:ocsp.xxxxxxxx)까지 이전 단계를 반복합니다.
-
-
VPC에 Route 53 해석기 인바운드 엔드포인트 구성하기
이 섹션에는 VPC에서 Route 53 해석기 인바운드 엔드포인트를 구성하는 방법에 대한 설명이 있습니다.
-
AWS 콘솔 내의 Route 53 메뉴
로 이동합니다. -
왼쪽 창에 있는 보안(Security) 섹션에서 보안 그룹(Security Groups) 옵션을 선택합니다.
-
-
보안 그룹 생성을 선택합니다.
-
보안 그룹 이름(예:
datawranger-doc-route53-resolver-sg)과 설명을 입력합니다. -
이전 단계에서 사용한 VPC ID를 선택합니다.
-
VPC CIDR 블록 내에서 UDP 및 TCP를 통한 DNS를 허용하는 규칙을 생성합니다.

-
보안 그룹 생성을 선택합니다. 보안 그룹 ID(Security Group ID)에 유의하여 VPC 엔드포인트 보안 그룹에 트래픽을 허용하는 규칙을 추가합니다.
-
-
AWS 콘솔에서 Route 53 메뉴
로 이동합니다. -
해석기(Resolver) 섹션에서 인바운드 엔드포인트(Inbound Endpoint) 옵션을 선택합니다.
-
-
인바운드 엔드포인트 생성(Create Inbound Endpoint)을 선택합니다.
-
엔드포인트 이름을 입력합니다.
-
리전의 VPC(VPC in the Region) 드롭다운 목록에서 이전 단계에서 사용한 VPC ID를 선택합니다.
-
이 엔드포인트의 보안 그룹(Security group for this endpoint) 드롭다운 목록에서 이 섹션의 2단계에 있는 보안 그룹 ID를 선택합니다.
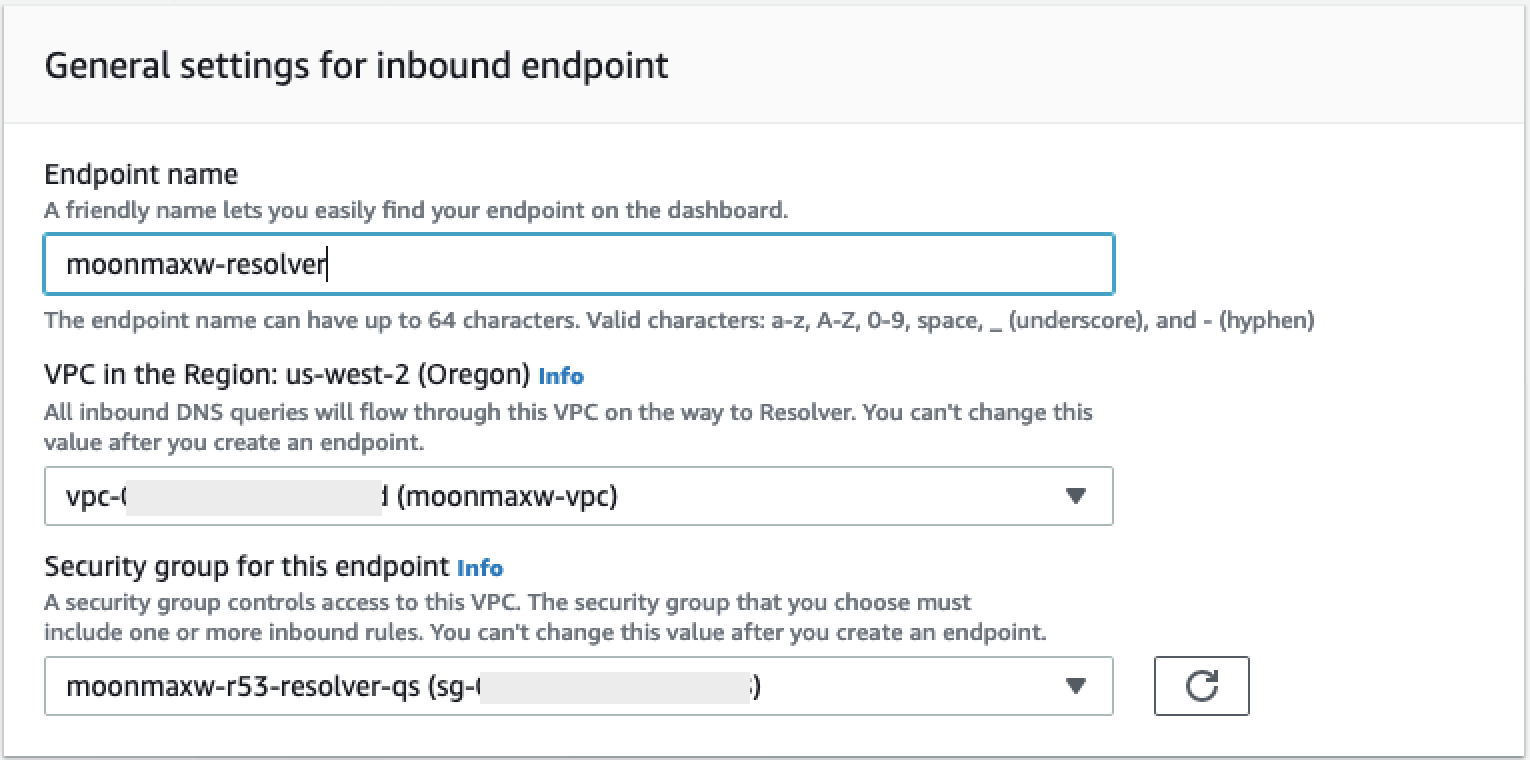
-
IP 주소(IP Address) 섹션에서 가용 영역을 선택하고 서브넷을 선택한 다음 각 IP 주소마다 자동으로 선택된 IP 주소 사용(Use an IP address that is selected automatically) 라디오 선택기를 선택된 상태로 둡니다.

-
제출을 선택합니다.
-
-
인바운드 엔드포인트 생성 후 선택합니다.
-
인바운드 엔드포인트 생성 후 해석기의 두 IP 주소를 기록해 둡니다.

SageMaker AI VPC 엔드포인트
이 섹션에는 Amazon SageMaker Studio Classic, SageMaker 노트북, SageMaker API, SageMaker 런타임, Amazon SageMaker Feature Store 런타임의 VPC 엔드포인트를 만드는 방법에 대한 설명이 있습니다.
모든 엔드포인트에 적용되는 보안 그룹을 생성합니다.
-
AWS 콘솔에서 EC2 메뉴
로 이동합니다. -
네트워킹 및 보안(Network & Security) 섹션에서 보안 그룹 옵션을 선택합니다.
-
보안 그룹 생성을 선택합니다.
-
보안 그룹 이름 및 설명(예:
datawrangler-doc-sagemaker-vpce-sg)을 입력합니다. 나중에 규칙이 추가되어 SageMaker AI에서이 그룹으로의 HTTPS를 통한 트래픽을 허용합니다.
엔드포인트 생성
-
AWS 콘솔에서 VPC 메뉴
로 이동합니다. -
엔드포인트 옵션을 선택합니다.
-
엔드포인트 생성을 선택합니다.
-
검색(Search) 필드에서 이름으로 서비스를 검색합니다.
-
VPC 드롭다운 목록에서 Snowflake AWS PrivateLink 연결이 있는 VPC를 선택합니다.
-
서브넷(Subnets) 섹션에서 Snowflake PrivateLink 연결에 액세스할 수 있는 서브넷을 선택합니다.
-
DNS 이름 활성화(Enable DNS Name) 확인란을 선택 상태로 둡니다.
-
보안 그룹 섹션에서 이전 섹션에서 생성한 보안 그룹을 선택합니다.
-
엔드포인트 생성을 선택합니다.
Studio Classic 및 Data Wrangler 구성
이 섹션에는 Studio Classic과 Data Wrangler를 구성하는 방법에 대한 설명이 있습니다.
-
보안 그룹을 구성합니다.
-
AWS 콘솔에서 Amazon EC2 메뉴로 이동합니다.
-
보안 그룹 옵션을 네트워크 및 보안 섹션에서 선택합니다.
-
보안 그룹 생성을 선택합니다.
-
보안 그룹의 이름 및 설명(예:
datawrangler-doc-sagemaker-studio)을 입력합니다. -
다음 인바운드 규칙을 생성합니다.
-
Snowflake PrivateLink 통합 설정 단계에서 생성한 Snowflake PrivateLink 연결을 위해 프로비저닝한 보안 그룹에 대한 HTTPS 연결.
-
Snowflake PrivateLink 통합 단계에서 생성한 Snowflake PrivateLink 연결을 위해 프로비저닝한 보안 그룹에 대한 HTTP 연결.
-
VPC에 Route 53 해석기 인바운드 엔드포인트 구성하기 2단계에서 생성한 Route 53 인바운드 엔드포인트 보안 그룹에 대한 DNS용 UDP 및 TCP(포트 53).
-
-
오른쪽 하단에서 보안 그룹 생성 버튼을 선택합니다.
-
-
Studio Classic을 구성합니다.
-
AWS 콘솔에서 SageMaker AI 메뉴로 이동합니다.
-
왼쪽 콘솔에서 SageMaker AI Studio Classic 옵션을 선택합니다.
-
도메인을 구성하지 않은 경우, 시작하기(Get Started) 메뉴가 나타납니다.
-
표준 설정(Standard Setup) 옵션을 시작하기 메뉴에서 선택합니다.
-
인증 방법에서 AWS 자격 증명 및 액세스 관리(IAM)를 선택합니다.
-
사용 사례에 따라 권한(Permissions) 메뉴에서 새 역할을 생성하거나 기존 역할을 사용할 수 있습니다.
-
새 역할 생성(Create a new role)을 선택하면 S3 버킷 이름과 정책을 입력하는 옵션이 자동으로 생성됩니다.
-
액세스가 필요한 S3 버킷에 대한 권한이 있는 역할을 이미 생성한 경우, 드롭다운 목록에서 역할을 선택합니다. 이 역할에는
AmazonSageMakerFullAccess정책이 연결되어야 합니다.
-
-
네트워크 및 스토리지 드롭다운 목록을 선택하여 SageMaker AI가 사용하는 VPC, 보안 및 서브넷을 구성합니다.
-
VPC 아래에서 Snowflake PrivateLink 연결이 있는 VPC를 선택합니다.
-
서브넷(Subnets) 아래에서 Snowflake PrivateLink 연결에 액세스할 수 있는 서브넷을 선택합니다.
-
Studio Classic용 네트워크 액세스 아래에서 VPC 전용을 선택합니다.
-
보안 그룹 아래에서 1단계에서 생성한 보안 그룹을 선택합니다.
-
-
제출을 선택합니다.
-
-
SageMaker AI 보안 그룹을 편집합니다.
-
다음 인바운드 규칙을 생성합니다.
-
2단계에서 SageMaker AI가 자동으로 생성한 인바운드 및 아웃바운드 NFS 보안 그룹으로 2049를 포팅합니다(보안 그룹 이름에는 Studio Classic 도메인 ID가 포함됨).
-
모든 TCP 포트 자체에 대한 액세스(VPC 전용 SageMaker AI에 필요).
-
-
-
VPC 엔드포인트 및 보안 그룹을 편집합니다.
-
AWS 콘솔에서 Amazon EC2 메뉴로 이동합니다.
-
이전 단계에서 생성한 보안 그룹을 찾습니다.
-
1단계에서 생성한 보안 그룹으로부터의 HTTPS 트래픽을 허용하는 인바운드 규칙을 추가합니다.
-
-
사용자 프로필을 생성합니다.
-
SageMaker Studio Classic 컨트롤 패널에서 사용자 추가를 선택합니다.
-
사용자 이름을 제공합니다.
-
실행 역할을 생성하거나 기존 역할을 사용합니다.
-
새 역할 생성(Create a new role)을 선택하면 Amazon S3 버킷 이름과 정책을 입력하는 옵션이 자동으로 생성됩니다.
-
액세스가 필요한 Amazon S3 버킷에 대한 권한이 있는 역할을 이미 생성한 경우, 드롭다운 목록에서 역할을 선택합니다. 이 역할에는
AmazonSageMakerFullAccess정책이 연결되어야 합니다.
-
-
제출을 선택합니다.
-
-
데이터 흐름을 생성합니다(이전 섹션에 있는 데이터 사이언티스트 안내서 참조).
-
Snowflake 연결 추가 시, 일반 Snowflake 계정 이름 대신
privatelink-account-name값(Snowflake PrivateLink 통합 설정 단계)을 Snowflake account name (alphanumeric)(Snowflake 계정 이름(영숫자)) 필드에 입력합니다. 그 밖의 모든 항목은 변경되지 않습니다.
-
데이터 사이언티스트에게 정보 제공하기
데이터 과학자에게 Amazon SageMaker AI Data Wrangler에서 Snowflake에 액세스하는 데 필요한 정보를 제공합니다.
중요
사용자는 Amazon SageMaker Studio Classic 버전 1.3.0 이상을 실행해야 합니다. Studio Classic 버전을 확인하고 업데이트하는 방법은 Amazon SageMaker Data Wrangler로 ML 데이터 준비하기에서 확인하세요.
-
데이터 사이언티스트가 SageMaker Data Wrangler에서 Snowflake에 액세스하려면 다음 중 하나를 입력해야 합니다.
-
기본 인증 시 Snowflake 계정 이름, 사용자 이름 및 암호.
-
OAuth 시 ID 제공업체의 사용자 이름 및 암호.
-
ARN 시 Secrets Manager 보안 암호 Amazon 리소스 이름(ARN)
-
AWS Secrets Manager와 보안 암호 ARN으로 생성한 보안 암호. 다음 절차에 따라 옵션 선택 시 Snowflake용 보안 암호를 생성합니다.
중요
데이터 사이언티스트가 Snowflake 자격 증명(사용자 이름 및 암호) 옵션으로 Snowflake에 연결하는 경우 Secrets Manager로 자격 증명을 보안 암호에 저장할 수 있습니다. Secrets Manager는 모범 사례 보안 계획의 일부로 보안 암호를 교체합니다. Secrets Manager에서 만든 보안 암호는 Studio Classic 사용자 프로필 설정 시 구성한 Studio Classic 역할이 있어야 액세스할 수 있습니다. 그러려면 Studio Classic 역할에 연결된 정책에
secretsmanager:PutResourcePolicy권한을 추가해야 합니다.Studio Classic 사용자 그룹별로 다른 역할을 적용하도록 역할 정책 범위를 지정할 것을 적극 권장합니다. Secrets Manager 보안 암호에 대한 추가 리소스 기반 권한을 추가할 수 있습니다. 사용할 수 있는 조건 키는 암호 관리 정책에서 확인하세요.
암호 생성 방법은 보안 암호 생성에서 확인하세요. 보안 암호 생성 시 요금이 부과됩니다.
-
-
(선택 사항) Snowflake에서 클라우드 스토리지 통합 생성하기
절차에 따라 생성한 스토리지 통합 이름을 데이터 사이언티스트에게 제공합니다. 이는 새 통합의 이름으로서 integration_name(으)로 명명되며, 다음 코드 조각에 표시된 실행한CREATE INTEGRATIONSQL 명령에 있습니다.CREATE STORAGE INTEGRATION integration_name TYPE = EXTERNAL_STAGE STORAGE_PROVIDER = S3 ENABLED = TRUE STORAGE_AWS_ROLE_ARN = 'iam_role' [ STORAGE_AWS_OBJECT_ACL = 'bucket-owner-full-control' ] STORAGE_ALLOWED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') [ STORAGE_BLOCKED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') ]
데이터 사이언티스트 안내서
Snowflake를 연결하고 Data Wrangler에 있는 데이터에 액세스하는 방법은 다음과 같습니다.
중요
관리자는 이전 섹션의 정보를 사용하여 Snowflake를 설정해야 합니다. 문제 발생 시 관리자에게 문의하여 문제 해결 지원을 받으세요.
다음 중 한 가지 방법으로 Snowflake에 연결할 수 있습니다.
-
Data Wrangler에서 Snowflake 자격 증명(계정 이름, 사용자 이름 및 암호) 지정.
-
자격 증명이 포함된 보안 암호의 Amazon 리소스 이름(ARN) 입력.
-
Snowflake에 연결하는 액세스 위임 개방형 표준(OAuth) 제공업체 이용. 관리자는 다음 OAuth 제공업체 중 하나에 대한 액세스 권한을 부여할 수 있습니다.
Snowflake 연결 시 사용해야 하는 메서드는 관리자에게 문의하세요.
다음 섹션에는 이전 메서드로 Snowflake에 연결하는 방법에 대한 정보가 있습니다.
자격 증명으로 Snowflake에서 Data Wrangler로 데이터세트를 가져오려면
-
Amazon SageMaker AI 콘솔
에 로그인합니다. -
Studio를 선택합니다.
-
Launch app(앱 시작)을 선택합니다.
-
드롭다운 목록에서 Studio를 선택합니다.
-
홈 아이콘을 선택합니다.
-
Data(데이터)를 선택합니다.
-
Data Wrangler를 선택합니다.
-
데이터 가져오기(Import data)을 선택합니다.
-
사용 가능(Available) 아래에서 Snowflake를 선택합니다.
-
연결 이름(Connection name)에서 연결 고유 식별자를 지정합니다.
-
인증 방법(Authentication method)에서 기본 사용자 이름-암호(Basic Username-Password)를 선택합니다.
-
Snowflake 계정 이름(영숫자)(Snowflake account name (alphanumeric))에서 Snowflake 계정의 전체 이름을 지정합니다.
-
사용자 이름(Username)에서 Snowflake 계정 액세스 시 사용하는 사용자 이름을 지정합니다.
-
암호(Password)에서 사용자 이름과 연결된 암호를 지정합니다.
-
(선택 사항) 고급 설정(Advanced settings)에서 다음을 지정합니다.
-
역할(Role) - Snowflake 내 역할. 일부 역할은 여러 데이터세트에 액세스할 수 있습니다. 역할을 지정하지 않으면 Data Wrangler는 Snowflake 계정에서 기본 역할을 사용합니다.
-
스토리지 통합(Storage integration) - 쿼리를 지정하고 실행하면 Data Wrangler는 쿼리 결과의 임시 사본을 메모리에 생성합니다. 쿼리 결과의 영구 사본을 저장하려면, 스토리지 통합용 Amazon S3 위치를 지정합니다. S3 URI은 관리자가 제공합니다.
-
KMS 키 ID(KMS key ID) - 사용자가 생성한 KMS 키. ARN을 지정하여 Snowflake 쿼리의 출력을 암호화할 수 있습니다. 그렇지 않으면 Data Wrangler는 기본 암호화를 사용합니다.
-
-
연결을 선택합니다.
Snowflake에서 데이터를 가져오는 프로세스는 연결 후 시작할 수 있습니다.
Data Wrangler에서는 테이블을 미리 볼 수 있는 눈 아이콘과 함께 데이터 웨어하우스, 데이터베이스, 스키마를 볼 수 있습니다. 테이블 미리 보기(Preview Table) 아이콘 선택 후, 테이블의 스키마 미리보기가 생성됩니다. 테이블을 미리 보려면 먼저 웨어하우스를 선택해야 합니다.
중요
TIMESTAMP_TZ 또는 TIMESTAMP_LTZ 유형의 열이 있는 데이터세트를 가져오는 경우, 쿼리 열 이름에 ::string을(를) 추가합니다. 자세한 정보는 TIMESTAMP_TZ 및 TIMESTAMP_LTZ 데이터를 Parquet 파일로 언로드하는 방법
데이터 웨어하우스, 데이터베이스, 스키마를 선택해야 쿼리를 작성하고 실행할 수 있습니다. 쿼리 출력은 쿼리 결과(Query results) 아래에 표시됩니다.
쿼리 출력 결정 후 쿼리 결과를 Data Wrangler 흐름으로 가져와 데이터 변환을 수행할 수 있습니다.
데이터를 가져온 후에는 Data Wrangler 흐름으로 이동하여 변환 추가를 시작합니다. 사용 가능한 변환 목록은 데이터 변환하기에서 확인하세요.
서비스형 소프트웨어(SaaS) 플랫폼에서 데이터 가져오기
Data Wrangler로 40가지 이상의 서비스형 소프트웨어(SaaS) 플랫폼에서 데이터를 가져올 수 있습니다. SaaS 플랫폼에서 데이터를 가져오려면 사용자 또는 관리자가 Amazon AppFlow로 플랫폼에서 Amazon S3 또는 Amazon Redshift로 데이터를 전송해야 합니다. Amazon AppFlow에 대한 자세한 정보는 Amazon AppFlow란 무엇입니까?에서 확인하세요. Amazon Redshift를 사용할 필요가 없는 경우, 데이터를 Amazon S3로 전송하여 더 간단한 프로세스를 사용할 것을 권장합니다.
Data Wrangler는 다음 SaaS 플랫폼에서의 데이터 전송을 지원합니다.
이전 목록에는 데이터 소스 설정에 대한 추가 정보를 볼 수 있는 링크가 있습니다. 사용자 또는 관리자는 다음 정보를 읽은 후 이전 링크를 참조할 수 있습니다.
Data Wrangler 흐름의 가져오기(Import) 탭으로 이동하면 다음 섹션 아래에 데이터 소스가 표시됩니다.
-
사용 가능
-
데이터 소스 설정
사용 가능 아래에서 추가 구성 없이 데이터 소스에 연결할 수 있습니다. 데이터 소스를 선택하고 데이터를 가져올 수 있습니다.
데이터 소스 설정 아래 데이터 소스를 사용하려면 사용자 또는 관리자가 Amazon AppFlow를 사용하여 SaaS 플랫폼에서 Amazon S3 또는 Amazon Redshift로 데이터를 전송해야 합니다. 전송 방법은 Amazon AppFlow로 데이터 전송하기에서 확인하세요.
데이터 전송 수행 후, 사용 가능 아래에 SaaS 플랫폼이 데이터 소스로 표시됩니다. 이 플랫폼을 선택하면 Data Wrangler로 전송한 데이터를 가져올 수 있습니다. 전송한 데이터는 쿼리할 수 있는 테이블로 표시됩니다.
Amazon AppFlow로 데이터 전송하기
Amazon AppFlow는 코드 작성 없이 SaaS 플랫폼에서 Amazon S3 또는 Amazon Redshift로 데이터를 전송할 수 있는 플랫폼입니다. 데이터 전송을 수행하려면 AWS Management Console을(를) 사용합니다.
중요
데이터 전송 권한 설정 여부를 확인해야 합니다. 자세한 내용은 Amazon AppFlow 권한 단원을 참조하십시오.
권한 추가 후 데이터를 전송할 수 있습니다. Amazon AppFlow에서 데이터 전송 흐름을 생성합니다. 흐름은 일련의 구성입니다. 흐름을 통해 일정에 따라 데이터 전송을 실행할지 아니면 데이터를 별도의 파일로 분할할지 지정할 수 있습니다. 흐름을 구성한 후 실행하여 데이터를 전송합니다.
흐름 생성 방법은 Amazon AppFlow로 흐름 생성하기에서 확인하세요. 흐름 실행 방법은 Amazon AppFlow 흐름 활성화하기에서 확인하세요.
데이터 전송 후 다음 절차에 따라 Data Wrangler 데이터에 액세스합니다.
중요
데이터 액세스 전 IAM 역할에 다음 정책이 적용되었는지 확인하세요.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "glue:SearchTables",
"Resource": [
"arn:aws:glue:*:*:table/*/*",
"arn:aws:glue:*:*:database/*",
"arn:aws:glue:*:*:catalog"
]
}
]
}
기본적으로, Data Wrangler에 액세스하는 데 사용하는 IAM 역할은 SageMakerExecutionRole입니다. 정책 추가 방법에 대한 자세한 내용은 IAM 자격 증명 권한 추가하기(콘솔)에서 확인하세요.
데이터 소스 연결 방법은 다음과 같습니다.
-
Amazon SageMaker AI 콘솔
에 로그인합니다. -
Studio를 선택합니다.
-
Launch app(앱 시작)을 선택합니다.
-
드롭다운 목록에서 Studio를 선택합니다.
-
홈 아이콘을 선택합니다.
-
Data(데이터)를 선택합니다.
-
Data Wrangler를 선택합니다.
-
데이터 가져오기(Import data)을 선택합니다.
-
사용 가능(Available) 아래에서 데이터 소스를 선택합니다.
-
이름(Name) 필드에서 연결 이름을 지정합니다.
-
(선택 사항) 고급 구성(Advanced configuration)을 선택합니다.
-
작업 그룹(Workgroup)을 선택합니다.
-
작업 그룹이 Amazon S3 출력 위치를 적용하지 않았거나 작업 그룹을 사용하지 않는 경우, 쿼리 결과의 Amazon S3 위치(Amazon S3 location of query results) 값을 지정합니다.
-
(선택 사항) 데이터 보존 기간(Data retention period)에서 확인란을 선택하여 데이터 보존 기간을 설정하고 삭제 전까지 저장할 일수를 지정합니다.
-
(선택 사항) 기본적으로 Data Wrangler는 연결을 저장합니다. 확인란 선택을 해제하여 연결을 저장하지 않을 수 있습니다.
-
-
연결을 선택합니다.
-
쿼리를 지정합니다.
참고
쿼리 지정을 위해 왼쪽 탐색창에서 테이블을 선택할 수 있습니다. Data Wrangler에는 테이블 이름과 테이블 미리보기가 표시됩니다. 테이블 이름 옆 아이콘을 선택하여 이름을 복사합니다. 쿼리에 테이블 이름을 사용할 수 있습니다.
-
Run(실행)을 선택합니다.
-
쿼리 가져오기(Import query)를 선택합니다.
-
데이터세트 이름(Dataset name)에서 데이터세트 이름을 지정합니다.
-
추가를 선택합니다.
데이터 가져오기(Import data) 화면으로 이동하면 생성한 연결을 볼 수 있습니다. 연결을 사용하여 더 많은 데이터를 가져올 수 있습니다.
가져온 데이터 스토리지
중요
보안 모범 사례에 따라 Amazon S3 버킷을 보호하는 모범 사례를 따를 것을 적극 권장합니다.
Amazon Athena 또는 Amazon Redshift에서 데이터를 쿼리하면 쿼리된 데이터세트가 Amazon S3에 자동으로 저장됩니다. 데이터는 Studio Classic을 사용하는 AWS 리전의 기본 SageMaker AI S3 버킷에 저장됩니다.
기본 S3 버킷의 명명 규칙은 sagemaker-입니다. 예를 들어, 계정 번호가 111122223333이고 region-account
numberus-east-1에서 Studio Classic을 사용하는 경우, 가져온 데이터세트는 sagemaker-us-east-1-111122223333에 저장됩니다.
Data Wrangler 흐름은 이 Amazon S3 데이터세트 위치에 따라 달라지므로, 종속 흐름을 사용하는 동안에는 Amazon S3에서 이 데이터세트를 수정해서는 안 됩니다. 이 S3 위치를 수정하고 데이터 흐름을 계속 사용하려면 .flow 파일에 있는 trained_parameters에서 모든 객체를 제거해야 합니다. 그러려면 Studio Classic에서 .flow 파일을 다운로드하고 각 trained_parameters 인스턴스의 모든 항목을 삭제해야 합니다. 작업 후 trained_parameters은(는) 빈 JSON 객체가 되어야 합니다.
"trained_parameters": {}데이터를 내보내고 데이터 흐름으로 데이터를 처리하는 경우, 내보내는 .flow 파일은 Amazon S3의 이 데이터세트를 참조합니다. 다음 섹션에서 자세히 알아보세요.
Amazon Redshift 가져오기 스토리지
Data Wrangler는 쿼리로 인한 데이터 세트를 기본 SageMaker AI S3 버킷의 Parquet 파일에 저장합니다.
이 파일은 redshift/uuid/data/ 접두사(디렉터리) 아래 저장되는데, 여기서 uuid는 쿼리별로 생성되는 고유 식별자입니다.
예를 들어, 기본 버킷이 sagemaker-us-east-1-111122223333인 경우, Amazon Redshift에서 쿼리된 단일 데이터세트의 위치는 s3://sagemaker-us-east-1-111122223333/redshift/uuid/data/입니다.
Amazon Athena 가져오기 스토리지
Athena 데이터베이스를 쿼리하고 데이터세트를 가져오면 Data Wrangler는 데이터세트와 해당 데이터세트의 서브셋 또는 미리 보기 파일을 Amazon S3에 저장합니다.
데이터세트 가져오기를 선택하여 가져온 데이터세트는 Amazon S3에 Parquet 형식으로 저장됩니다.
Athena 가져오기 화면에서 실행을 선택하면 미리 보기 파일이 CSV 형식으로 작성되며, 쿼리된 데이터세트의 최대 100개 행을 포함합니다.
쿼리하는 데이터세트는 athena/uuid/data/ 접두사(디렉터리) 아래에 있는데, 여기서 uuid는 쿼리별로 생성되는 고유 식별자입니다.
예를 들어, 기본 버킷이 sagemaker-us-east-1-111122223333인 경우, Athena에서 쿼리된 단일 데이터세트의 위치는 s3://sagemaker-us-east-1-111122223333/athena/uuid/data/example_dataset.parquet입니다.
Data Wrangler에서 데이터프레임을 미리 보기 위해 저장되는 데이터세트의 서브셋은 접두사 athena/ 아래에 저장됩니다.
