기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
모델 병렬 처리 소개
모델 병렬화는 딥 러닝 모델을 여러 디바이스, 인스턴스 내 또는 인스턴스 간에 분할하는 분산 훈련 방법입니다. 이 소개 페이지에서는 모델 병렬 처리에 대한 높은 수준의 개요, 일반적으로 크기가 매우 큰 DL 모델을 훈련할 때 발생하는 문제를 해결하는 데 도움이 되는 방법에 대한 설명, SageMaker 모델 병렬 라이브러리가 제공하는 모델 병렬 전략과 메모리 소비를 관리하는 데 도움이 되는 기능의 예를 제공합니다.
모델 병렬성이란 무엇입니까?
딥러닝 모델(계층 및 파라미터)의 크기를 늘리면 컴퓨터 비전 및 자연어 처리와 같은 복잡한 작업의 정확도가 향상됩니다. 그러나 단일 GPU의 메모리에 담을 수 있는 최대 모델 크기에는 제한이 있습니다. DL 모델을 훈련할 때 GPU 메모리 제한으로 인해 다음과 같은 방식으로 병목 현상이 발생할 수 있습니다.
-
모델의 메모리 사용량은 파라미터 수에 비례하여 확장되므로 훈련할 수 있는 모델의 크기가 제한됩니다.
-
이는 훈련 중에 GPU당 배치 크기를 제한하여 GPU 사용률과 훈련 효율성을 낮춥니다.
단일 GPU에서 모델을 훈련하는 것과 관련된 한계를 극복하기 위해 SageMaker는 모델 병렬 라이브러리를 제공하여 여러 컴퓨팅 노드에서 DL 모델을 효율적으로 배포하고 훈련시키는 데 도움이 됩니다. 또한 라이브러리를 사용하면 EFA 지원 장치를 사용하여 가장 최적화된 분산 훈련을 수행할 수 있으며, 이를 통해 짧은 지연 시간, 높은 처리량 및 OS 바이패스로 노드 간 통신의 성능을 향상시킬 수 있습니다.
모델 병렬화를 사용하기 전에 메모리 요구 사항을 예측하세요.
SageMaker 모델 병렬 라이브러리를 사용하기 전에 다음을 고려하여 대규모 DL 모델을 훈련시키는 데 필요한 메모리 요구 사항을 파악하세요.
AMP(FP16) 및 Adam 옵티마이저를 사용하는 훈련 작업의 경우 파라미터당 필요한 GPU 메모리는 약 20바이트이며, 이를 다음과 같이 분류할 수 있습니다.
-
FP16 파라미터는 최대 2바이트입니다.
-
FP16 그래디언트는 최대 2바이트입니다.
-
Adam 옵티마이저를 기반으로 하는 FP32 옵티마이저 상태 ~ 8바이트
-
최대 4바이트의 파라미터 FP32 사본(
optimizer apply(OA) 작업에 필요) -
4바이트까지의 그래디언트의 FP32 복사본 (OA 작업에 필요)
100억 개의 파라미터가 있는 비교적 작은 DL 모델의 경우에도 최소 200GB의 메모리가 필요할 수 있는데, 이는 단일 GPU에서 사용할 수 있는 일반적인 GPU 메모리(예: 40GB/80GB 메모리가 탑재된 NVIDIA A100와 16/32GB의 V100)보다 훨씬 큰 용량입니다. 모델 및 옵티마이저 상태에 대한 메모리 요구 사항 외에도 포워드 패스에서 생성되는 활성화와 같은 다른 메모리 소비자도 있다는 점에 유의하세요. 필요한 메모리는 200GB를 훨씬 넘을 수 있습니다.
분산 훈련의 경우 각각 NVIDIA V100 및 A100 텐서 코어 GPU가 있는 Amazon EC2 P3 및 P4 인스턴스를 사용하는 것이 좋습니다. CPU 코어, RAM, 연결된 스토리지 볼륨, 네트워크 대역폭과 같은 사양에 대한 자세한 내용은 Amazon EC2 인스턴스
가속화된 컴퓨팅 인스턴스를 사용하더라도 MegaTron-LM 및 T5와 같이 약 100억 개의 파라미터가 있는 모델이나 GPT-3 같이 수천억 개의 파라미터를 사용하는 더 큰 모델조차도 각 GPU 디바이스의 모델 복제본에 맞지 않는다는 것은 명백합니다.
라이브러리가 모델 병렬화 및 메모리 절약 기법을 사용하는 방법
라이브러리는 다양한 유형의 모델 병렬 처리 기능과 옵티마이저 상태 샤딩, 활성화 체크포인트, 활성화 오프로드 등의 메모리 절약 기능으로 구성되어 있습니다. 이러한 모든 기술을 결합하여 수천억 개의 파라미터로 구성된 대형 모델을 효율적으로 훈련시킬 수 있습니다.
주제
샤딩된 데이터 병렬화(PyTorch에서 사용 가능)
샤드 있는 데이터 병렬화는 데이터 병렬 그룹 내의 GPU에서 모델 상태(모델 파라미터, 그래디언트, 옵티마이저 상태)를 분할하는 메모리 절약형 분산 훈련 기법입니다.
SageMaker AI는 통신 규모를 최소화하는 라이브러리인 MiCS를 구현하여 샤딩된 데이터 병렬화를 구현합니다. 이 라이브러리는 Near-linear scaling of gigantic-model training on AWS
샤딩된 데이터 병렬화를 독립형 전략으로 모델에 적용할 수 있습니다. 또한 NVIDIA A100 Tensor Core GPU(ml.p4d.24xlarge)가 장착된 가장 성능이 좋은 GPU 인스턴스를 사용하는 경우 SMDDP Collectives에서 제공하는 작업을 통해 AllGather에서 향상된 훈련 속도를 활용할 수 있습니다.
분할된 데이터 병렬화에 대해 자세히 알아보고 분할된 데이터 병렬화를 설정하거나 텐서 병렬화 및 FP16 트레이닝과 같은 다른 기술과 함께 사용하는 방법을 알아보려면 샤딩된 데이터 병렬 처리 섹션을 참조하세요.
파이프라인 병렬화(PyTorch 및 TensorFlow에서 사용 가능)
파이프라인 병렬화는 디바이스 세트 전체에 걸쳐 계층 또는 작업 세트를 분할하여 각 연산을 그대로 유지합니다. 모델 파티션 수(pipeline_parallel_degree) 값을 지정하는 경우 총 GPU 수(processes_per_host)를 모델 파티션 수로 나눌 수 있어야 합니다. 이 설정을 제대로 설정하려면 pipeline_parallel_degree 및 processes_per_host 파라미터에 대해 올바른 값을 지정해야 합니다. 간단한 수학은 다음과 같습니다.
(pipeline_parallel_degree) x (data_parallel_degree) = processes_per_host
라이브러리는 사용자가 제공한 두 개의 입력 파라미터가 주어지면 모델 복제본(일명 data_parallel_degree)의 수를 계산합니다.
예를 들어, ml.p3.16xlarge와 같이 8개의 GPU 워커가 있는 ML 인스턴스를 사용하여 "pipeline_parallel_degree": 2 및 "processes_per_host": 8를 설정하고 사용하는 경우 라이브러리는 GPU 전체에 분산 모델과 4방향 데이터 병렬화를 자동으로 설정합니다. 다음 이미지는 모델이 8개의 GPU에 분산되어 4방향 데이터 병렬성과 양방향 파이프라인 병렬성을 달성하는 방법을 보여줍니다. 파이프라인 병렬 그룹으로 정의하고 PP_GROUP로 레이블을 지정하는 각 모델 복제본은 두 개의 GPU로 분할됩니다. 모델의 각 파티션은 4개의 GPU에 할당되며, 여기서 4개의 파티션 복제본은 데이터 병렬 그룹에 속하며 DP_GROUP로 레이블이 지정됩니다. 텐서 병렬 처리가 없으면 파이프라인 병렬 그룹은 기본적으로 모델 병렬 그룹입니다.
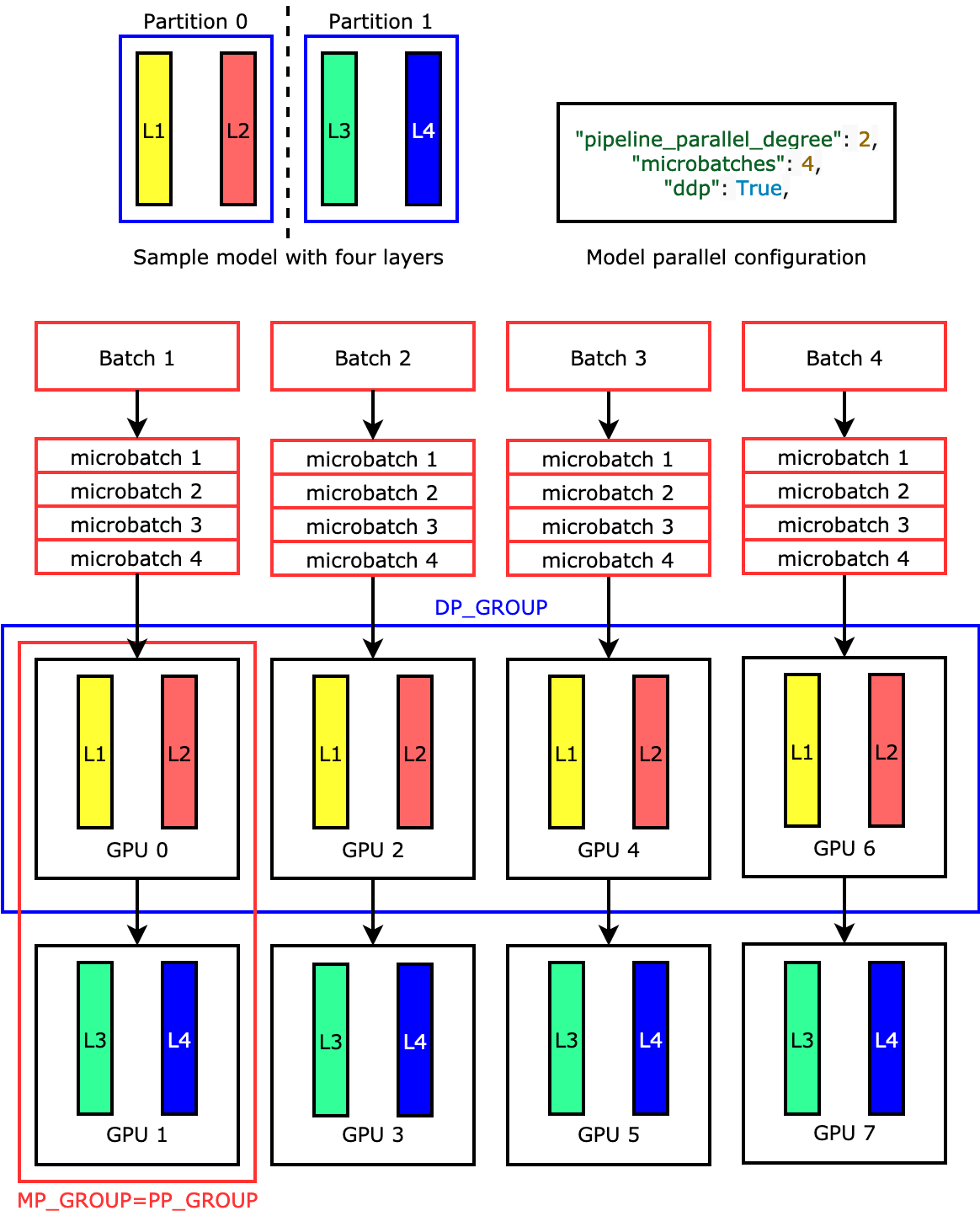
파이프라인 병렬성에 대해 자세히 알아보려면 SageMaker 모델 병렬화 라이브러리의 핵심 기능 섹션을 참조하세요.
파이프라인 병렬화를 사용하여 모델 실행을 시작하려면 SageMaker 모델 병렬 라이브러리를 사용하여 SageMaker 분산 훈련 작업 실행을 참조하세요.
텐서 병렬 처리(PyTorch에서 사용 가능)
텐서 병렬 처리는 개별 계층(nn.Modules)을 분할하거나 디바이스 간에 병렬로 실행되도록 합니다. 다음 그림은 라이브러리가 모델을 네 개의 계층으로 분할하여 양방향 텐서 병렬 처리("tensor_parallel_degree": 2)를 달성하는 방법의 가장 간단한 예를 보여줍니다. 각 모델 복제본의 계층은 이등분되어 두 개의 GPU로 분산됩니다. 이 예제에서 모델 병렬 구성에는 "pipeline_parallel_degree": 1 및 "ddp": True(백그라운드에서 PyTorch DistributedDataParallel 패키지 사용)도 포함되어 있으므로 데이터 병렬 처리 수준은 8이 됩니다. 라이브러리는 텐서 분산 모델 복제본 간의 통신을 관리합니다.
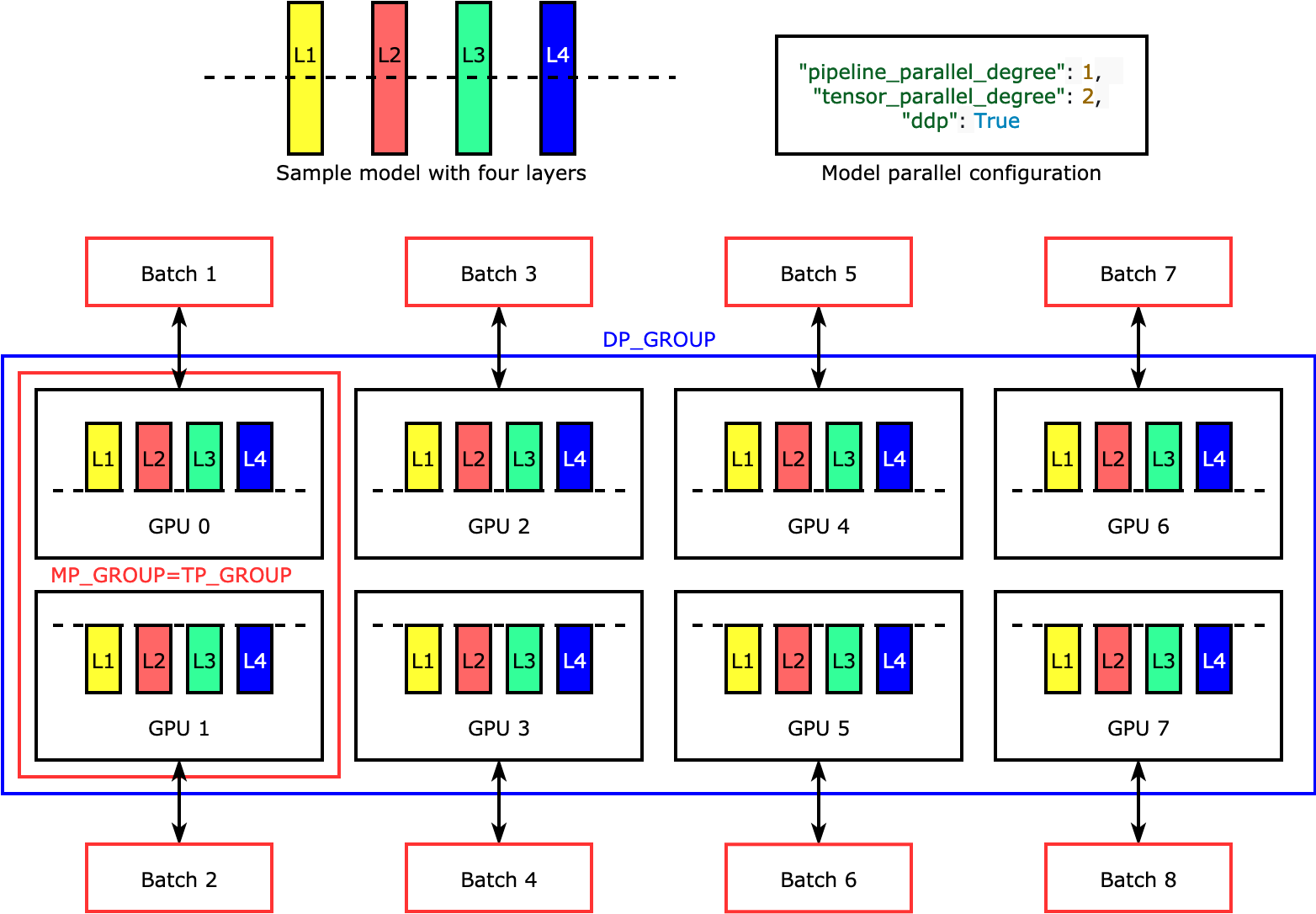
이 기능의 유용성은 특정 계층 또는 계층의 하위 집합을 선택하여 텐서 병렬성을 적용할 수 있다는 점입니다. PyTorch의 텐서 병렬 처리 및 기타 메모리 절약 기능에 대해 자세히 알아보고 파이프라인과 텐서 병렬 처리의 조합을 설정하는 방법을 알아보려면 텐서 병렬 처리 섹션을 참조하세요.
옵티마이저 상태 샤딩(PyTorch에서 사용 가능)
라이브러리가 옵티마이저 상태 샤딩을 수행하는 방식을 이해하려면 네 개의 계층으로 구성된 간단한 예제 모델을 고려해 보세요. 상태 샤딩을 최적화하는 핵심 아이디어는 모든 GPU에서 옵티마이저 상태를 복제할 필요가 없다는 것입니다. 대신 옵티마이저 상태의 단일 복제본이 여러 디바이스에 걸쳐 중복되지 않고 데이터 병렬 랭크에 걸쳐 분할됩니다. 예를 들어 GPU 0은 계층 1의 옵티마이저 상태를 유지하고 다음 GPU 1은 L2의 옵티마이저 상태를 유지하는 식입니다. 다음 애니메이션 그림은 옵티마이저 상태 샤딩 기법을 사용한 역방향 전파를 보여줍니다. 역방향 전파가 끝나면 옵티마이저 상태를 업데이트하는 optimizer apply(OA) 작업과 다음 반복을 위해 모델 파라미터를 업데이트하는 all-gather(AG) 작업에 필요한 컴퓨팅 및 네트워크 시간이 있습니다. 가장 중요한 것은 reduce 작업이 GPU 0의 컴퓨팅과 겹칠 수 있어 메모리 효율성이 향상되고 역방향 전파 속도가 빨라질 수 있다는 것입니다. 현재 구현에서는 AG 및 OA 연산이 compute와 겹치지 않습니다. 이로 인해 AG 작업 중에 계산이 확장될 수 있으므로 절충점이 있을 수 있습니다.
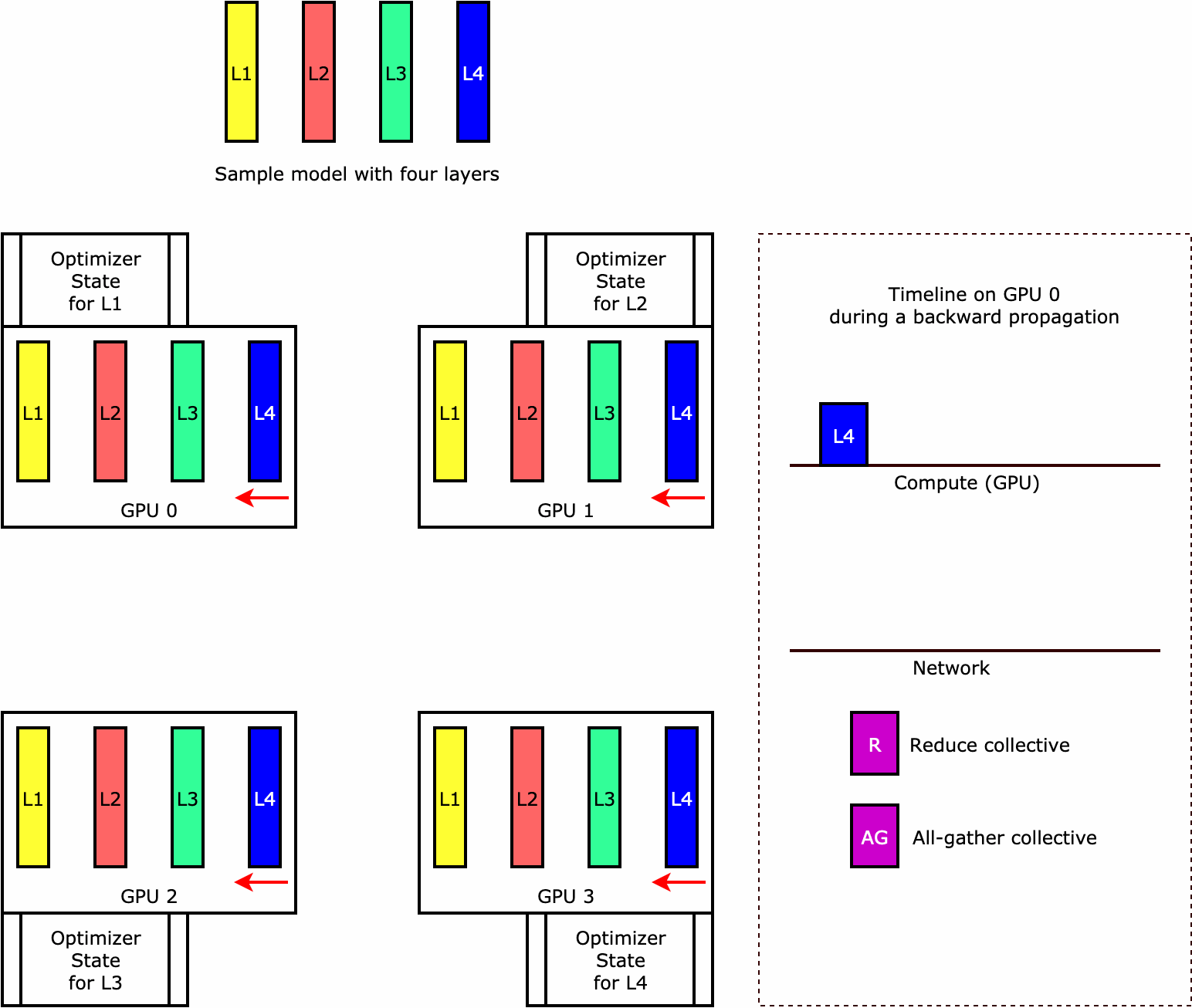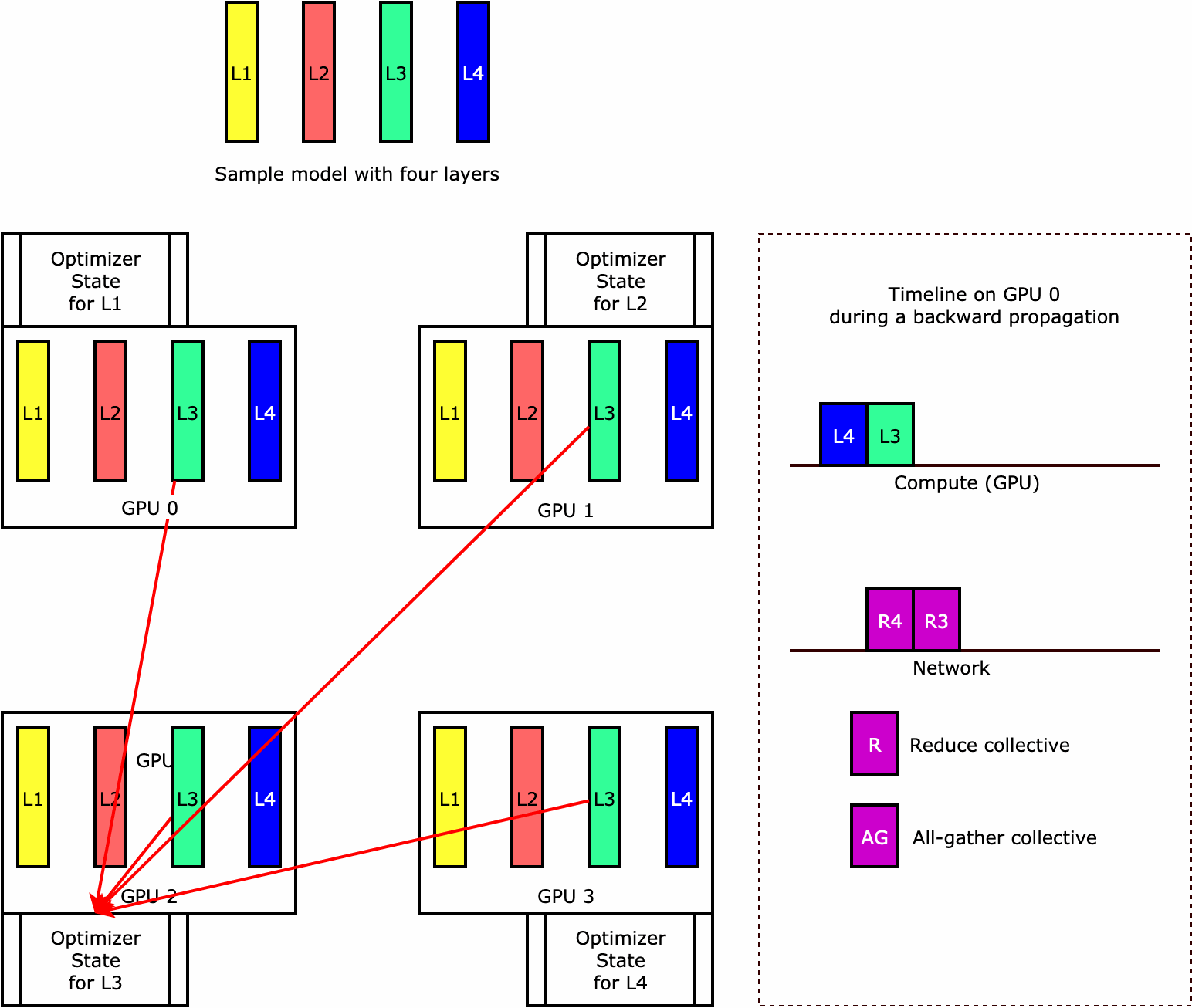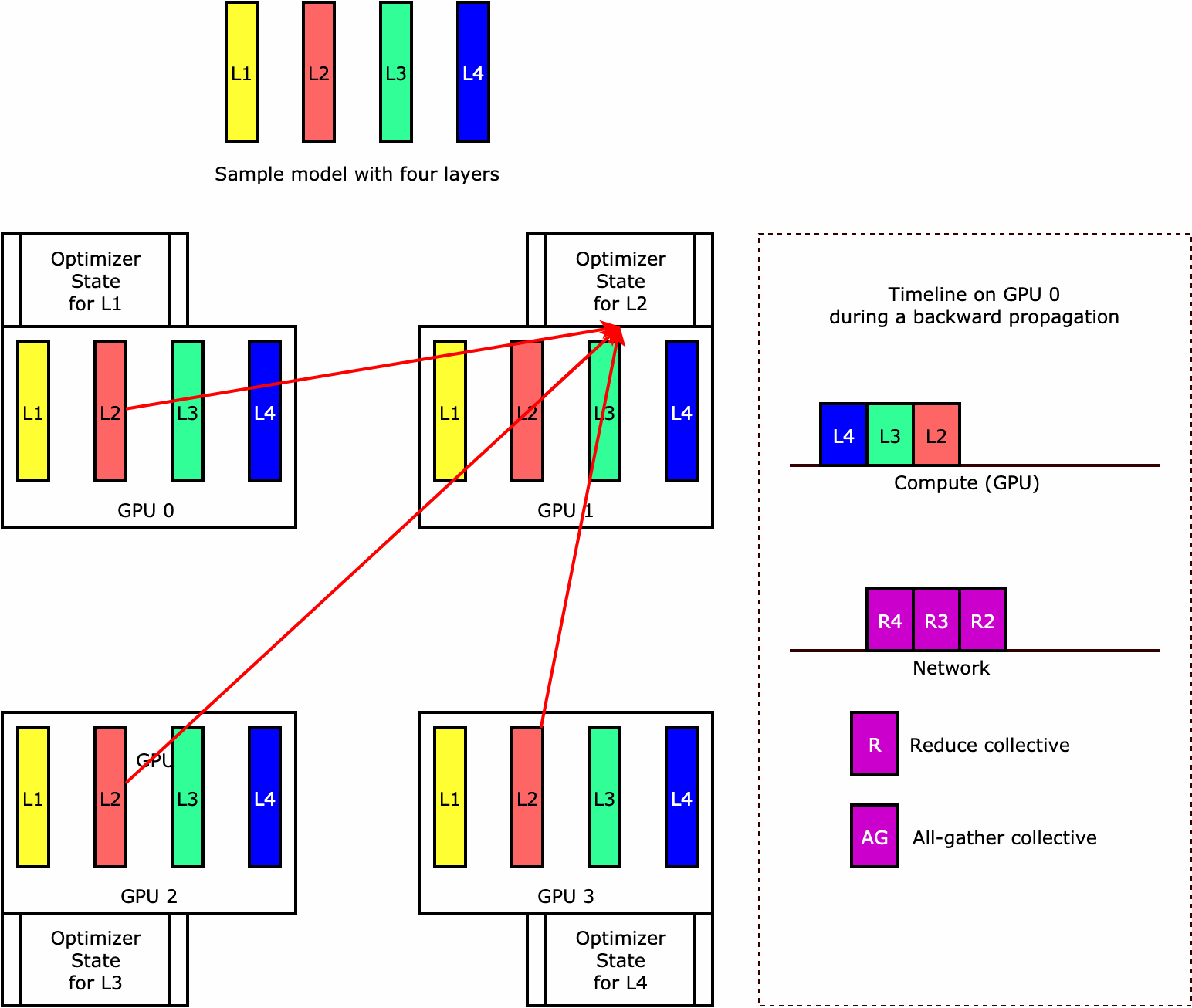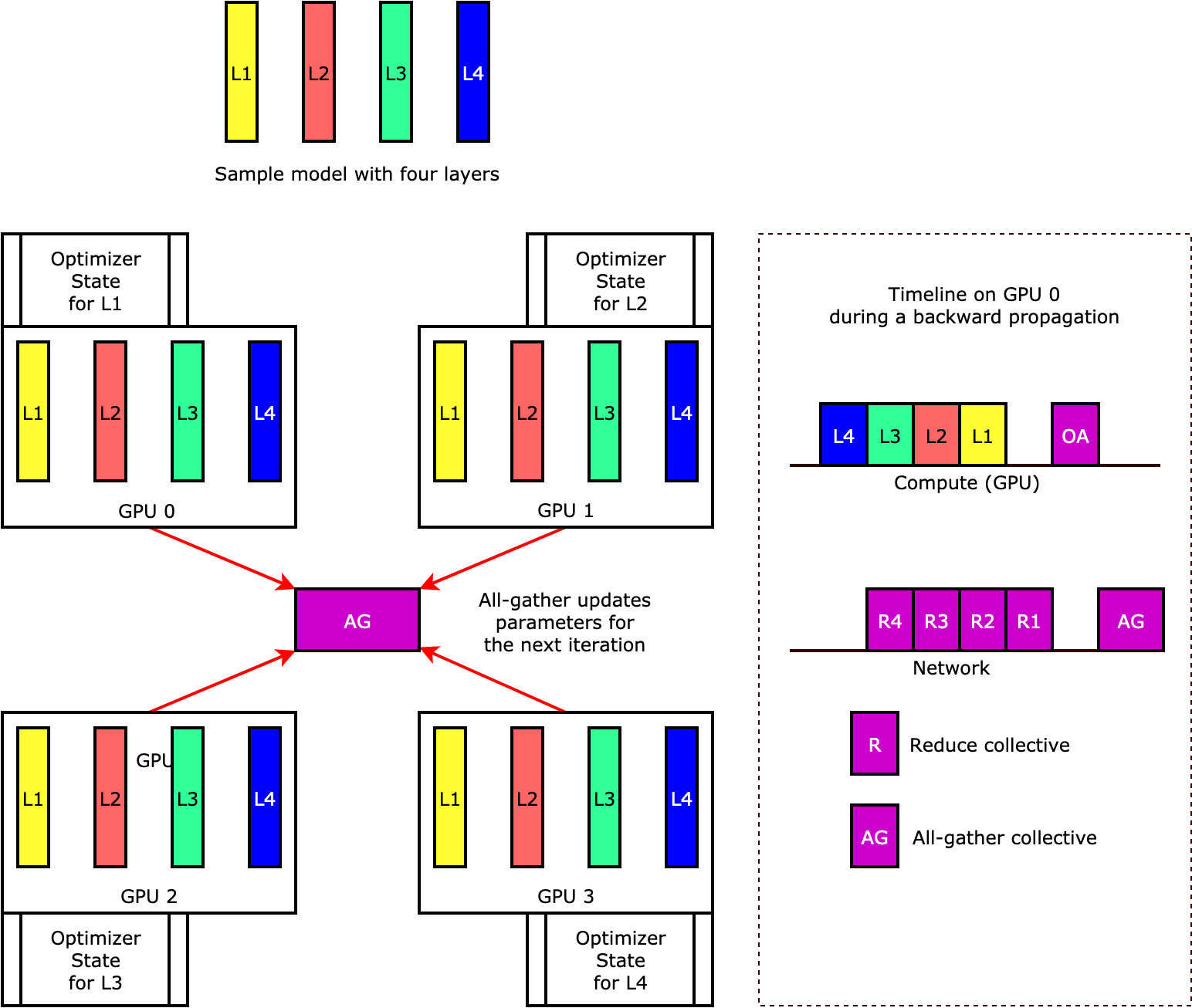
이 기능을 사용하는 방법에 대한 자세한 내용은 옵티마이저 상태 샤딩을 참조하세요.
오프로드 활성화 및 체크포인트(PyTorch에서 사용 가능)
GPU 메모리를 절약하기 위해 라이브러리는 정방향 전달 중에 사용자 지정 모듈의 내부 활성화를 GPU 메모리에 저장하지 않도록 활성화 체크포인트를 지원합니다. 라이브러리는 역방향 통과 중에 이러한 활성화를 다시 계산합니다. 또한 활성화 오프로드 기능은 저장된 액티베이션을 CPU 메모리로 오프로드하고 역방향 패스 중에 GPU로 다시 가져와서 활성화 메모리 사용량을 더욱 줄입니다. 이러한 기능을 사용하는 방법에 대한 자세한 내용은 활성화 체크포인트 및 활성화 오프로딩을 참조하세요.
모델에 적합한 기법 선택
올바른 기법 및 구성 선택에 대한 자세한 내용은 SageMaker 분산 모델 병렬 모범 사례 및 구성 팁 및 문제를 참조하세요.
