기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
이 Python 기반 자습서는 Python용 SDK(Boto3)와 Amazon SageMaker Studio Classic 노트북을 사용합니다. 이 데모를 성공적으로 완료하려면 SageMaker 지리 공간 및 Studio Classic을 사용하는 데 필요한 AWS Identity and Access Management (IAM) 권한이 있어야 합니다. SageMaker 지리 공간을 사용하려면 Studio Classic에 액세스 할 수 있는 사용자, 그룹 또는 역할이 있어야 합니다. 또한 신뢰 정책에 SageMaker 지리 공간 서비스 보안 주체를 지정하는 SageMaker AI 실행 역할sagemaker-geospatial.amazonaws.com이 있어야 합니다.
이러한 요구 사항에 대해 자세히 알아보려면 SageMaker 지리 공간 IAM 역할을 참조하세요.
이 자습서에서는 SageMaker 지리 공간 API를 사용하여 다음 작업을 완료하는 방법을 보여줍니다.
-
list_raster_data_collections에서 사용 가능한 래스터 데이터 컬렉션을 찾습니다. -
search_raster_data_collection를 사용하여 지정된 래스터 데이터 컬렉션을 검색합니다. -
start_earth_observation_job를 사용하여 지구 관측 작업(EOJ)을 생성합니다.
list_raster_data_collections를 사용하여 사용 가능한 데이터 컬렉션 찾기
SageMaker 지리 공간은 다중 래스터 데이터 컬렉션을 지원합니다. 사용 가능한 데이터 컬렉션에 대한 자세한 내용은 데이터 컬렉션을 참조하세요.
이 데모에서는 Sentinel-2구름 최적화 GeoTIFF
관심 영역(AOI)을 검색하려면 Sentinel-2 위성 데이터와 연결된 ARN이 필요합니다. 에서 사용 가능한 데이터 컬렉션 및 관련 ARNs 찾으려면 list_raster_data_collections API 작업을 AWS 리전사용합니다.
응답에 페이지를 매길 수 있으므로 관련 데이터를 모두 반환하려면 get_paginator작업을 사용해야 합니다.
import boto3
import sagemaker
import sagemaker_geospatial_map
import json
## SageMaker Geospatial is currently only avaialable in US-WEST-2
session = boto3.Session(region_name='us-west-2')
execution_role = sagemaker.get_execution_role()
## Creates a SageMaker Geospatial client instance
geospatial_client = session.client(service_name="sagemaker-geospatial")
# Creates a resusable Paginator for the list_raster_data_collections API operation
paginator = geospatial_client.get_paginator("list_raster_data_collections")
# Create a PageIterator from the paginator class
page_iterator = paginator.paginate()
# Use the iterator to iterate throught the results of list_raster_data_collections
results = []
for page in page_iterator:
results.append(page['RasterDataCollectionSummaries'])
print(results)다음은 list_raster_data_collectionsAPI 작업의 샘플 JSON 응답입니다. 이 코드 예제에 사용된 데이터 컬렉션(Sentinel-2)만 포함하도록 잘렸습니다. 특정 래스터 데이터 컬렉션에 대한 자세한 내용은 get_raster_data_collection을 사용하세요.
{
"Arn": "arn:aws:sagemaker-geospatial:us-west-2:378778860802:raster-data-collection/public/nmqj48dcu3g7ayw8",
"Description": "Sentinel-2a and Sentinel-2b imagery, processed to Level 2A (Surface Reflectance) and converted to Cloud-Optimized GeoTIFFs",
"DescriptionPageUrl": "https://registry.opendata.aws/sentinel-2-l2a-cogs",
"Name": "Sentinel 2 L2A COGs",
"SupportedFilters": [
{
"Maximum": 100,
"Minimum": 0,
"Name": "EoCloudCover",
"Type": "number"
},
{
"Maximum": 90,
"Minimum": 0,
"Name": "ViewOffNadir",
"Type": "number"
},
{
"Name": "Platform",
"Type": "string"
}
],
"Tags": {},
"Type": "PUBLIC"
}이전 코드 샘플을 실행한 후 Sentinel-2 래스터 데이터 컬렉션의 ARN인 arn:aws:sagemaker-geospatial:us-west-2:378778860802:raster-data-collection/public/nmqj48dcu3g7ayw8을 얻습니다. 다음 섹션에서는 search_raster_data_collectionAPI를 사용하여 Sentinel-2 데이터 컬렉션을 쿼리할 수 있습니다.
search_raster_data_collection를 사용하여 Sentinel-2래스터 데이터 컬렉션 검색
이전 섹션에서는 list_raster_data_collections을 사용하여 Sentinel-2데이터 컬렉션을 위한 ARN을 가져왔습니다. 이제 해당 ARN을 사용하여 지정된 관심 영역(AOI), 시간 범위, 속성 및 사용 가능한 UV 대역에 대한 데이터 컬렉션을 검색할 수 있습니다.
search_raster_data_collection API를 호출하려면 Python 사전을 RasterDataCollectionQuery파라미터에 전달해야 합니다. 이 예제에서는 AreaOfInterest, TimeRangeFilter, PropertyFilters, BandFilter를 사용합니다. 쉽게 하기 위해, 변수 search_rdc_query를 사용하여 Python 사전을 지정하여 검색 쿼리 파라미터를 유지할 수 있습니다:
search_rdc_query = {
"AreaOfInterest": {
"AreaOfInterestGeometry": {
"PolygonGeometry": {
"Coordinates": [
[
# coordinates are input as longitute followed by latitude
[-114.529, 36.142],
[-114.373, 36.142],
[-114.373, 36.411],
[-114.529, 36.411],
[-114.529, 36.142],
]
]
}
}
},
"TimeRangeFilter": {
"StartTime": "2022-01-01T00:00:00Z",
"EndTime": "2022-07-10T23:59:59Z"
},
"PropertyFilters": {
"Properties": [
{
"Property": {
"EoCloudCover": {
"LowerBound": 0,
"UpperBound": 1
}
}
}
],
"LogicalOperator": "AND"
},
"BandFilter": [
"visual"
]
}이 예시에서는 유타 주의 미드 호수AreaOfInterest에 대해 쿼리합니다. 또한 Sentinel-2는 여러 유형의 이미지 밴드를 지원합니다. 물 표면의 변화를 측정하려면 visual밴드만 있으면 됩니다.
쿼리 파라미터를 생성한 후 search_raster_data_collectionAPI를 사용하여 요청할 수 있습니다.
다음 코드 샘플은 search_raster_data_collectionAPI 요청을 구현합니다. 이 API는 get_paginatorAPI를 사용한 페이지 매김을 지원하지 않습니다. 전체 API 응답이 수집되었는지 확인하기 위해 코드 샘플에서는 while루프를 사용하여 NextToken이 존재하는지 확인합니다. 그런 다음 코드 샘플은 .extend()를 사용하여 위성 이미지 URL 및 기타 응답 메타데이터를 items_list에 추가합니다.
에 대한 자세한 search_raster_data_collection내용은 Amazon SageMaker AI API 참조의 SearchRasterDataCollection을 참조하세요.
search_rdc_response = sm_geo_client.search_raster_data_collection(
Arn='arn:aws:sagemaker-geospatial:us-west-2:378778860802:raster-data-collection/public/nmqj48dcu3g7ayw8',
RasterDataCollectionQuery=search_rdc_query
)
## items_list is the response from the API request.
items_list = []
## Use the python .get() method to check that the 'NextToken' exists, if null returns None breaking the while loop
while search_rdc_response.get('NextToken'):
items_list.extend(search_rdc_response['Items'])
search_rdc_response = sm_geo_client.search_raster_data_collection(
Arn='arn:aws:sagemaker-geospatial:us-west-2:378778860802:raster-data-collection/public/nmqj48dcu3g7ayw8',
RasterDataCollectionQuery=search_rdc_query, NextToken=search_rdc_response['NextToken']
)
## Print the number of observation return based on the query
print (len(items_list))다음은 쿼리에 대한 JSON 답변입니다. 명확성을 위해 잘렸습니다. 요청에 지정된 "BandFilter": ["visual"]만 Assets키-값 쌍으로 반환됩니다.
{
'Assets': {
'visual': {
'Href': 'https://sentinel-cogs.s3.us-west-2.amazonaws.com/sentinel-s2-l2a-cogs/15/T/UH/2022/6/S2A_15TUH_20220623_0_L2A/TCI.tif'
}
},
'DateTime': datetime.datetime(2022, 6, 23, 17, 22, 5, 926000, tzinfo = tzlocal()),
'Geometry': {
'Coordinates': [
[
[-114.529, 36.142],
[-114.373, 36.142],
[-114.373, 36.411],
[-114.529, 36.411],
[-114.529, 36.142],
]
],
'Type': 'Polygon'
},
'Id': 'S2A_15TUH_20220623_0_L2A',
'Properties': {
'EoCloudCover': 0.046519,
'Platform': 'sentinel-2a'
}
}이제 쿼리 결과를 얻었으므로 다음 섹션에서 matplotlib를 사용하여 결과를 시각화할 수 있습니다. 이는 결과가 정확한 지리적 리전에서 나온 것인지 확인하기 위한 것입니다.
matplotlib를 사용한 search_raster_data_collection시각화
지구 관측 작업(EOJ)을 시작하기 전에 matplotlib를 사용하여 쿼리 결과를 시각화할 수 있습니다. 다음 코드 샘플은 이전 코드 샘플에서 생성한 items_list변수에서 첫 번째 항목 items_list[0]["Assets"]["visual"]["Href"]을 가져와 matplotlib를 사용하여 이미지를 인쇄합니다.
# Visualize an example image.
import os
from urllib import request
import tifffile
import matplotlib.pyplot as plt
image_dir = "./images/lake_mead"
os.makedirs(image_dir, exist_ok=True)
image_dir = "./images/lake_mead"
os.makedirs(image_dir, exist_ok=True)
image_url = items_list[0]["Assets"]["visual"]["Href"]
img_id = image_url.split("/")[-2]
path_to_image = image_dir + "/" + img_id + "_TCI.tif"
response = request.urlretrieve(image_url, path_to_image)
print("Downloaded image: " + img_id)
tci = tifffile.imread(path_to_image)
plt.figure(figsize=(6, 6))
plt.imshow(tci)
plt.show()결과가 정확한 지리적 영역에 있는지 확인한 후 다음 단계에서 지구 관측 작업(EOJ)을 시작할 수 있습니다. EOJ를 사용하면 토지 세그먼트화라는 프로세스를 사용하여 위성 이미지에서 수역을 식별할 수 있습니다.
일련의 위성 이미지에 대한 토지 세그먼트화를 수행하는 지구 관측 작업(EOJ) 시작
SageMaker 지리 공간은 래스터 데이터 컬렉션의 지리 공간 데이터를 처리하는 데 사용할 수 있는 사전 훈련된 여러 모델을 제공합니다. 사용 가능한 사전 훈련된 모델과 사용자 정의 작업에 대해 자세히 알아보려면 작업 유형을 참조하세요.
수면 면적의 변화를 계산하려면 이미지의 어떤 픽셀이 물에 해당하는지 식별해야 합니다. 토지 피복 세그먼트화는 start_earth_observation_jobAPI에서 지원하는 의미 체계 분할 모델입니다. 의미 체계 분할 모델은 레이블을 각 이미지의 모든 픽셀과 연결합니다. 결과에서 각 픽셀에는 모델의 클래스 맵을 기반으로 하는 레이블이 할당됩니다. 다음은 토지 세그먼트화 모델의 클래스 맵입니다.
{
0: "No_data",
1: "Saturated_or_defective",
2: "Dark_area_pixels",
3: "Cloud_shadows",
4: "Vegetation",
5: "Not_vegetated",
6: "Water",
7: "Unclassified",
8: "Cloud_medium_probability",
9: "Cloud_high_probability",
10: "Thin_cirrus",
11: "Snow_ice"
}지구 관측 작업을 시작하려면 start_earth_observation_jobAPI를 사용하세요. 요청을 제출할 때 다음을 지정해야 합니다.
-
InputConfig(dict) - 검색하려는 영역의 좌표 및 검색과 관련된 기타 메타데이터를 지정하는 데 사용됩니다. -
JobConfig(dict) - 데이터에 대해 수행한 EOJ 연산의 유형을 지정하는 데 사용됩니다. 이 예제에서는LandCoverSegmentationConfig를 사용합니다. -
ExecutionRoleArn(문자열) - 작업을 실행하는 데 필요한 권한이 있는 SageMaker AI 실행 역할의 ARN입니다. -
Name(string) - 지구 관측 작업의 이름입니다.
InputConfig는 Python사전입니다. 다음 변수 eoj_input_config를 사용하여 검색 쿼리 파라미터를 보관합니다. start_earth_observation_job API 요청 시 이 변수를 사용하세요.
# Perform land cover segmentation on images returned from the Sentinel-2 dataset.
eoj_input_config = {
"RasterDataCollectionQuery": {
"RasterDataCollectionArn": "arn:aws:sagemaker-geospatial:us-west-2:378778860802:raster-data-collection/public/nmqj48dcu3g7ayw8",
"AreaOfInterest": {
"AreaOfInterestGeometry": {
"PolygonGeometry": {
"Coordinates":[
[
[-114.529, 36.142],
[-114.373, 36.142],
[-114.373, 36.411],
[-114.529, 36.411],
[-114.529, 36.142],
]
]
}
}
},
"TimeRangeFilter": {
"StartTime": "2021-01-01T00:00:00Z",
"EndTime": "2022-07-10T23:59:59Z",
},
"PropertyFilters": {
"Properties": [{"Property": {"EoCloudCover": {"LowerBound": 0, "UpperBound": 1}}}],
"LogicalOperator": "AND",
},
}
}JobConfig은 데이터에 대해 수행하려는 EOJ 작업을 지정하는 데 사용되는 Python사전입니다.
eoj_config = {"LandCoverSegmentationConfig": {}}이제 사전 요소가 지정되었으므로 다음 코드 샘플을 사용하여 start_earth_observation_jobAPI 요청을 제출할 수 있습니다.
# Gets the execution role arn associated with current notebook instance
execution_role_arn = sagemaker.get_execution_role()
# Starts an earth observation job
response = sm_geo_client.start_earth_observation_job(
Name="lake-mead-landcover",
InputConfig=eoj_input_config,
JobConfig=eoj_config,
ExecutionRoleArn=execution_role_arn,
)
print(response)지구 관측 작업을 시작하면 다른 메타데이터와 함께 ARN이 반환됩니다.
list_earth_observation_jobs API를 사용하면 진행 중인 모든 지구 관측 작업의 목록을 얻을 수 있습니다. 단일 지구 관측 작업의 상태를 모니터링하려면 get_earth_observation_jobAPI를 사용합니다. 이 요청을 하려면 EOJ 요청을 제출한 후 생성된 ARN을 사용하세요. 자세한 내용은 Amazon SageMaker AI API 참조의 GetEarthObservationJob을 참조하세요.
EOJ와 관련된 ARN을 찾으려면 list_earth_observation_jobsAPI 작업을 사용하세요. 자세한 내용은 Amazon SageMaker AI API 참조의 ListEarthObservationJobs를 참조하세요.
# List all jobs in the account
sg_client.list_earth_observation_jobs()["EarthObservationJobSummaries"]다음은 JSON 응답의 예입니다.
{
'Arn': 'arn:aws:sagemaker-geospatial:us-west-2:111122223333:earth-observation-job/futg3vuq935t',
'CreationTime': datetime.datetime(2023, 10, 19, 4, 33, 54, 21481, tzinfo = tzlocal()),
'DurationInSeconds': 3493,
'Name': 'lake-mead-landcover',
'OperationType': 'LAND_COVER_SEGMENTATION',
'Status': 'COMPLETED',
'Tags': {}
}, {
'Arn': 'arn:aws:sagemaker-geospatial:us-west-2:111122223333:earth-observation-job/wu8j9x42zw3d',
'CreationTime': datetime.datetime(2023, 10, 20, 0, 3, 27, 270920, tzinfo = tzlocal()),
'DurationInSeconds': 1,
'Name': 'mt-shasta-landcover',
'OperationType': 'LAND_COVER_SEGMENTATION',
'Status': 'INITIALIZING',
'Tags': {}
}EOJ 작업 상태가 COMPLETED로 변경되면 다음 섹션으로 이동하여 Mead's 호수 표면적의 변화를 계산하세요.
Mead 호수 표면적의 변화 계산
미드 호수의 표면적 변화를 계산하려면 먼저 export_earth_observation_job을 사용하여 EOJ 결과를 Amazon S3로 내보냅니다.
sagemaker_session = sagemaker.Session()
s3_bucket_name = sagemaker_session.default_bucket() # Replace with your own bucket if needed
s3_bucket = session.resource("s3").Bucket(s3_bucket_name)
prefix = "export-lake-mead-eoj" # Replace with the S3 prefix desired
export_bucket_and_key = f"s3://{s3_bucket_name}/{prefix}/"
eoj_output_config = {"S3Data": {"S3Uri": export_bucket_and_key}}
export_response = sm_geo_client.export_earth_observation_job(
Arn="arn:aws:sagemaker-geospatial:us-west-2:111122223333:earth-observation-job/7xgwzijebynp",
ExecutionRoleArn=execution_role_arn,
OutputConfig=eoj_output_config,
ExportSourceImages=False,
)내보내기 작업의 상태를 보려면 get_earth_observation_job을 사용하세요.
export_job_details = sm_geo_client.get_earth_observation_job(Arn=export_response["Arn"])미드 호수의 수위 변화를 계산하려면 토지 피복 마스크를 로컬 SageMaker 노트북 인스턴스에 다운로드하고 이전 쿼리에서 소스 이미지를 다운로드하세요. 토지 세그먼트화 모델의 클래스 맵에서 물의 클래스 인덱스는 6입니다.
Sentinel-2 이미지에서 워터 마스크를 추출하려면 다음 단계를 따르세요. 먼저, 이미지에서 물(클래스 인덱스 6)로 표시된 픽셀 수를 셉니다. 그런 다음 개수에 각 픽셀이 차지하는 영역을 곱합니다. 밴드는 공간 해상도가 다를 수 있습니다. 토지 피복 세그먼트화 모델의 경우 모든 밴드는 60미터와 동일한 공간 해상도로 다운 샘플링됩니다.
import os
from glob import glob
import cv2
import numpy as np
import tifffile
import matplotlib.pyplot as plt
from urllib.parse import urlparse
from botocore import UNSIGNED
from botocore.config import Config
# Download land cover masks
mask_dir = "./masks/lake_mead"
os.makedirs(mask_dir, exist_ok=True)
image_paths = []
for s3_object in s3_bucket.objects.filter(Prefix=prefix).all():
path, filename = os.path.split(s3_object.key)
if "output" in path:
mask_name = mask_dir + "/" + filename
s3_bucket.download_file(s3_object.key, mask_name)
print("Downloaded mask: " + mask_name)
# Download source images for visualization
for tci_url in tci_urls:
url_parts = urlparse(tci_url)
img_id = url_parts.path.split("/")[-2]
tci_download_path = image_dir + "/" + img_id + "_TCI.tif"
cogs_bucket = session.resource(
"s3", config=Config(signature_version=UNSIGNED, region_name="us-west-2")
).Bucket(url_parts.hostname.split(".")[0])
cogs_bucket.download_file(url_parts.path[1:], tci_download_path)
print("Downloaded image: " + img_id)
print("Downloads complete.")
image_files = glob("images/lake_mead/*.tif")
mask_files = glob("masks/lake_mead/*.tif")
image_files.sort(key=lambda x: x.split("SQA_")[1])
mask_files.sort(key=lambda x: x.split("SQA_")[1])
overlay_dir = "./masks/lake_mead_overlay"
os.makedirs(overlay_dir, exist_ok=True)
lake_areas = []
mask_dates = []
for image_file, mask_file in zip(image_files, mask_files):
image_id = image_file.split("/")[-1].split("_TCI")[0]
mask_id = mask_file.split("/")[-1].split(".tif")[0]
mask_date = mask_id.split("_")[2]
mask_dates.append(mask_date)
assert image_id == mask_id
image = tifffile.imread(image_file)
image_ds = cv2.resize(image, (1830, 1830), interpolation=cv2.INTER_LINEAR)
mask = tifffile.imread(mask_file)
water_mask = np.isin(mask, [6]).astype(np.uint8) # water has a class index 6
lake_mask = water_mask[1000:, :1100]
lake_area = lake_mask.sum() * 60 * 60 / (1000 * 1000) # calculate the surface area
lake_areas.append(lake_area)
contour, _ = cv2.findContours(water_mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
combined = cv2.drawContours(image_ds, contour, -1, (255, 0, 0), 4)
lake_crop = combined[1000:, :1100]
cv2.putText(lake_crop, f"{mask_date}", (10,50), cv2.FONT_HERSHEY_SIMPLEX, 1.5, (0, 0, 0), 3, cv2.LINE_AA)
cv2.putText(lake_crop, f"{lake_area} [sq km]", (10,100), cv2.FONT_HERSHEY_SIMPLEX, 1.5, (0, 0, 0), 3, cv2.LINE_AA)
overlay_file = overlay_dir + '/' + mask_date + '.png'
cv2.imwrite(overlay_file, cv2.cvtColor(lake_crop, cv2.COLOR_RGB2BGR))
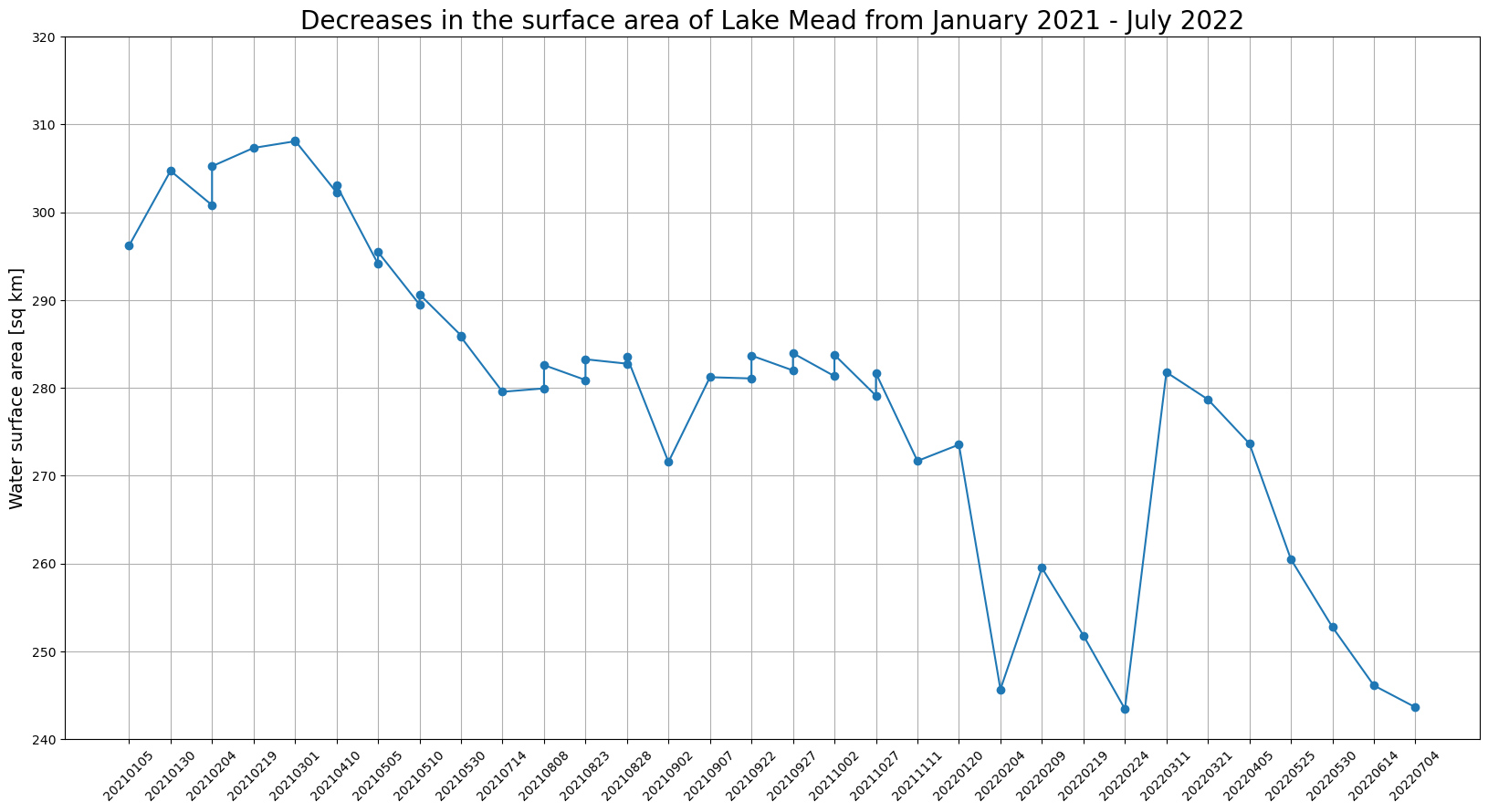
# Plot water surface area vs. time.
plt.figure(figsize=(20,10))
plt.title('Lake Mead surface area for the 2021.02 - 2022.07 period.', fontsize=20)
plt.xticks(rotation=45)
plt.ylabel('Water surface area [sq km]', fontsize=14)
plt.plot(mask_dates, lake_areas, marker='o')
plt.grid('on')
plt.ylim(240, 320)
for i, v in enumerate(lake_areas):
plt.text(i, v+2, "%d" %v, ha='center')
plt.show()matplotlib를 사용하면 결과를 그래프로 시각화할 수 있습니다. 그래프는 2021년 1월부터 2022년 7월까지 Mead호수의 표면적이 감소했음을 보여줍니다.