Pipelines 개요
Amazon SageMaker 파이프라인은 방향성 비순환 그래프(DAG)의 상호 연결된 일련의 단계로, 이 단계는 드래그 앤 드롭 UI 또는 Pipelines SDK
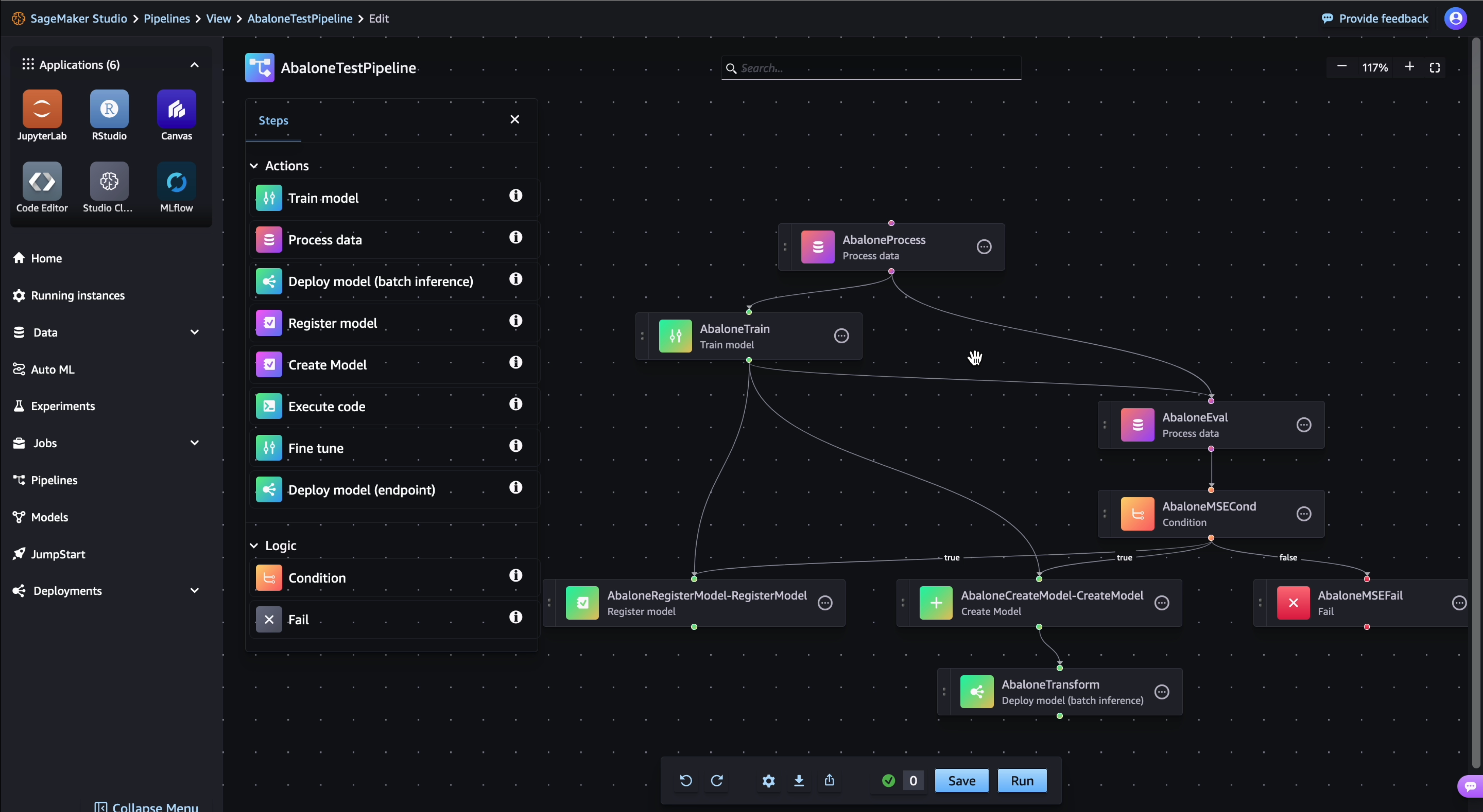
이 예시 DAG에는 다음 단계가 포함됩니다.
처리 단계의 인스턴스인
AbaloneProcess는 훈련에 사용되는 데이터에 대해 사전 처리 스크립트를 실행합니다. 예를 들어 스크립트는 누락된 값을 채우거나, 숫자 데이터를 정규화하거나, 데이터를 훈련, 검증 및 테스트 데이터세트로 분할할 수 있습니다.훈련 단계의 인스턴스인
AbaloneTrain은 하이퍼파라미터를 구성하고 사전 처리된 입력 데이터에서 모델을 훈련합니다.처리 단계의 또 다른 인스턴스인
AbaloneEval은 모델의 정확도를 평가합니다. 이 단계에서는 데이터 종속성의 예를 보여줍니다. 이 단계에서는AbaloneProcess의 테스트 데이터세트 출력을 사용합니다.AbaloneMSECond는 조건 단계의 인스턴스로, 이 예시에서는 모델 평가의 평균 제곱오차 결과가 특정 한도 미만인지 확인합니다. 모델이 기준을 충족하지 않으면 파이프라인 실행이 중지됩니다.파이프라인 실행은 다음 단계로 진행됩니다.
AbaloneRegisterModel. 여기서 SageMaker는 RegisterModel 단계를 직접 호출하여 모델을 Amazon SageMaker Model Registry에 버전 모델 패키지 그룹으로 등록합니다.AbaloneCreateModel. 여기서 SageMaker는 CreateModel 단계를 직접 호출하여 배치 변환을 준비하기 위해 모델을 만듭니다.AbaloneTransform에서 SageMaker는 변환 단계를 직접 호출하여 사용자가 지정한 데이터세트에 대한 모델 예측을 생성합니다.
다음 주제는 Pipelines의 기본 개념을 설명합니다. 이러한 개념의 구현을 설명하는 자습서는 Pipelines 작업섹션을 참조하세요.
주제
- 파이프라인 구조 및 실행
- IAM 액세스 관리
- Pipelines에 대한 교차 계정 지원 설정
- 파이프라인 파라미터
- Pipelines 단계
- @step 데코레이터를 사용한 Python 코드 리프트 앤 시프트
- 단계 간 데이터 전달
- 파이프라인 캐싱 단계
- 파이프라인 단계에 대한 재시도 정책
- 파이프라인 단계의 선택적 실행
- Amazon SageMaker Pipelines의 명확화 검사 및 품질 검사 단계를 사용한 기준 계산, 드리프트 감지 및 수명 주기
- 파이프라인 실행 예약
- Amazon SageMaker Experiments 통합
- 로컬 모드를 사용하여 파이프라인 실행
- Amazon SageMaker Pipelines 문제 해결
