기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
다음 절차에서는 텍스트 데이터세트에 대해 단일 예측과 배치 예측을 모두 수행하는 방법을 설명합니다. 각 즉시 사용 가능 모델은 데이터 세트에 대한 단일 예측과 배치 예측을 모두 지원합니다. 단일 예측은 한 가지 예측만 하면 되는 경우입니다. 예를 들어 텍스트를 추출하려는 이미지가 하나 있고 주요 언어를 감지하려는 텍스트 단락이 하나 있다고 가정해 보겠습니다. 배치 예측은 전체 데이터 세트를 예측하려는 경우입니다. 예를 들어 고객 감정을 분석하려는 고객 리뷰 CSV 파일이나 오브젝트를 감지하려는 이미지 파일이 있을 수 있습니다.
감정 분석, 엔터티 추출, 언어 감지, 개인 정보 감지 등의 즉시 사용 가능 모델 유형에 이러한 절차를 사용할 수 있습니다.
참고
감정 분석의 경우 영어 텍스트만 사용할 수 있습니다.
단일 예측
텍스트 데이터를 수용하는 즉시 사용 가능 모형에 대한 단일 예측을 수행하려면 다음 작업을 수행합니다.
-
Canvas 애플리케이션의 왼쪽 탐색 창에서 즉시 사용 가능 모델을 선택합니다.
-
즉시 사용 가능 모델 페이지에서 사용 사례에 즉시 사용 가능 모형을 선택합니다. 텍스트 데이터의 경우 감정 분석, 개체 추출, 언어 감지 또는 개인 정보 감지 중 하나여야 합니다.
-
선택한 즉시 사용 가능 모델의 예측 실행 페이지에서 단일 예측을 선택합니다.
-
텍스트 필드에 예측을 얻으려는 텍스트를 입력합니다.
-
예측 결과 생성을 선택하여 예측을 얻습니다.
예측 결과 오른쪽 창에서 각 결과 또는 레이블에 대한 신뢰도 점수와 함께 텍스트에 대한 분석이 표시됩니다. 예를 들어 언어 감지를 선택하고 프랑스어로 텍스트 구절을 입력한 경우 신뢰도 점수가 95%인 프랑스어와 신뢰도 점수 5%의 영어와 같은 다른 언어의 흔적이 나올 수 있습니다.
다음 스크린샷은 모델이 해당 구절이 영어라고 100% 확신하는 언어 감지를 사용한 단일 예측의 결과를 보여줍니다.
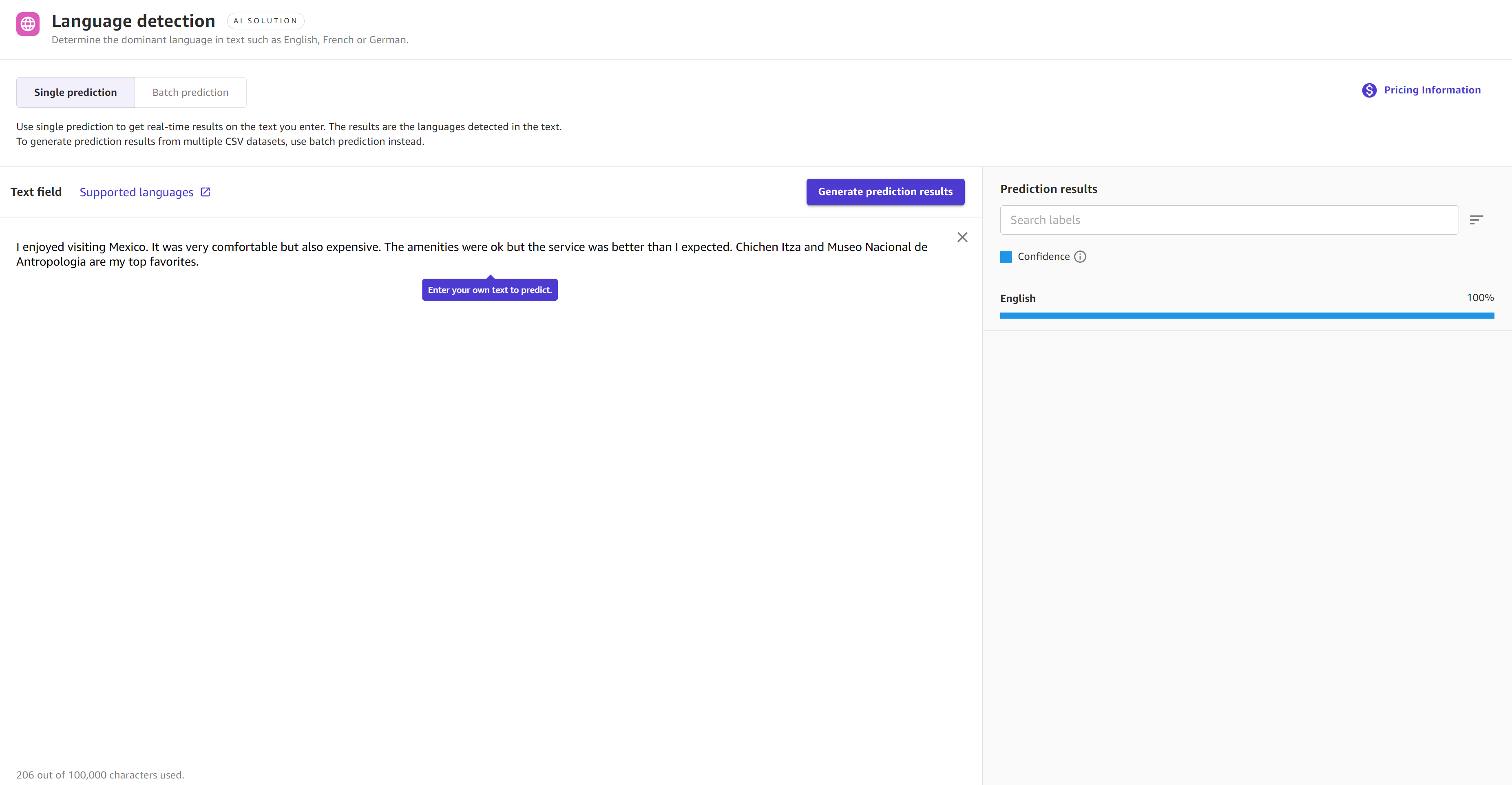
배치 예측
텍스트 데이터를 수용하는 즉시 사용 가능 모델에 대한 배치 예측을 수행하려면 다음 작업을 수행합니다.
-
Canvas 애플리케이션의 왼쪽 탐색 창에서 즉시 사용 가능 모델을 선택합니다.
-
즉시 사용 가능 모델 페이지에서 사용 사례에 즉시 사용 가능 모형을 선택합니다. 텍스트 데이터의 경우 감정 분석, 개체 추출, 언어 감지 또는 개인 정보 감지 중 하나여야 합니다.
-
선택한 즉시 사용 가능 모델의 예측 실행 페이지에서 배치 예측을 선택합니다.
-
데이터 세트를 이미 가져온 경우 데이터 세트 선택을 선택합니다. 그렇지 않은 경우 새 데이터 세트 가져오기를 선택하면 데이터 가져오기 워크플로로 안내됩니다.
-
사용 가능한 데이터 세트 목록에서 데이터 세트를 선택하고 예측 생성을 선택하여 예측을 얻습니다.
예측 작업 실행이 끝나면 예측 실행 페이지에서 예측 아래에 출력 데이터 세트가 나열되는 것을 볼 수 있습니다. 이 데이터세트에는 결과가 포함되며 추가 옵션 아이콘(
![]() )을 선택하면 출력 데이터를 미리 볼 수 있습니다. 그런 다음 다운로드를 선택하여 결과를 다운로드할 수 있습니다.
)을 선택하면 출력 데이터를 미리 볼 수 있습니다. 그런 다음 다운로드를 선택하여 결과를 다운로드할 수 있습니다.
