기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
다음 코드 샘플은 Studio Classic 노트북 내에서 특별히 빌드된 지리 공간 이미지를 사용하여 특정 지리적 영역의 정규화된 차이 초목 인덱스를 계산하고 SageMaker AI Python SDK에서를 사용하여 Amazon SageMaker SageMaker Processing으로 대규모 워크로드를 실행하는 방법을 보여줍니다. ScriptProcessor
이 데모에서는 지리 공간 커널과 인스턴스 유형을 사용하는 Amazon SageMaker Studio Classic 노트북 인스턴스도 사용합니다. Studio Classic 지리 공간 노트북 인스턴스를 만드는 방법은 지리 공간 이미지를 사용하여 Amazon SageMaker Studio Classic 노트북 만들기 섹션을 참조하세요.
다음 코드 스니펫을 복사하여 붙여넣으면 자신의 노트북 인스턴스에서 이 데모를 따라할 수 있습니다.
SearchRasterDataCollection를 사용하여 Sentinel-2래스터 데이터 컬렉션을 쿼리합니다.
search_raster_data_collection를 사용하여 지원되는 래스터 데이터 컬렉션을 쿼리할 수 있습니다. 이 예시에서는 Sentinel-2 위성에서 가져온 데이터를 사용합니다. 지정된 관심 지역(AreaOfInterest)은 아이오와 북부 시골이며, 시간 범위(TimeRangeFilter)는 2022년 1월 1일부터 2022년 12월 30일까지입니다. AWS 리전 에서 사용 가능한 래스터 데이터 컬렉션을 보려면 list_raster_data_collections을 사용하세요. 이 API를 사용하는 코드 예제를 보려면 Amazon SageMaker AI 개발자 안내서ListRasterDataCollections의 섹션을 참조하세요.
다음 코드 예시에서는 Sentinel-2 래스터 데이터 컬렉션과 관련된 ARN인 arn:aws:sagemaker-geospatial:us-west-2:378778860802:raster-data-collection/public/nmqj48dcu3g7ayw8을 사용합니다.
search_raster_data_collection API 요청에는 두 개의 파라미터가 필요합니다.
-
쿼리하려는 래스터 데이터 컬렉션에 해당하는
Arn파라미터를 지정해야 합니다. -
Python 사전을 받아들이는
RasterDataCollectionQuery파라미터도 지정해야 합니다.
다음 코드 예제에는 search_rdc_query변수에 저장된 RasterDataCollectionQuery파라미터에 필요한 필수 키-값 쌍이 포함되어 있습니다.
search_rdc_query = {
"AreaOfInterest": {
"AreaOfInterestGeometry": {
"PolygonGeometry": {
"Coordinates": [[
[
-94.50938680498298,
43.22487436936203
],
[
-94.50938680498298,
42.843474642037194
],
[
-93.86520004156142,
42.843474642037194
],
[
-93.86520004156142,
43.22487436936203
],
[
-94.50938680498298,
43.22487436936203
]
]]
}
}
},
"TimeRangeFilter": {"StartTime": "2022-01-01T00:00:00Z", "EndTime": "2022-12-30T23:59:59Z"}
}search_raster_data_collection 요청을 하려면 Sentinel-2 래스터 데이터 컬렉션의 ARN인 arn:aws:sagemaker-geospatial:us-west-2:378778860802:raster-data-collection/public/nmqj48dcu3g7ayw8을 지정해야 합니다. 또한 쿼리 파라미터를 지정하는 이전에 정의된 Python 사전을 전달해야 합니다.
## Creates a SageMaker Geospatial client instance
sm_geo_client= session.create_client(service_name="sagemaker-geospatial")
search_rdc_response1 = sm_geo_client.search_raster_data_collection(
Arn='arn:aws:sagemaker-geospatial:us-west-2:378778860802:raster-data-collection/public/nmqj48dcu3g7ayw8',
RasterDataCollectionQuery=search_rdc_query
)이 API의 결과는 페이지를 매길 수 없습니다. search_raster_data_collection 작업에서 반환된 모든 위성 이미지를 수집하기 위해 while루프를 구현할 수 있습니다. 이는 API 응답에서 NextToken을 확인합니다.
## Holds the list of API responses from search_raster_data_collection
items_list = []
while search_rdc_response1.get('NextToken') and search_rdc_response1['NextToken'] != None:
items_list.extend(search_rdc_response1['Items'])
search_rdc_response1 = sm_geo_client.search_raster_data_collection(
Arn='arn:aws:sagemaker-geospatial:us-west-2:378778860802:raster-data-collection/public/nmqj48dcu3g7ayw8',
RasterDataCollectionQuery=search_rdc_query,
NextToken=search_rdc_response1['NextToken']
)API 응답은 특정 이미지 밴드에 해당하는 Assets키 아래의 URL 목록을 반환합니다. 다음은 API 응답의 잘린 버전입니다. 명확성을 위해 일부 이미지 밴드가 제거되었습니다.
{
'Assets': {
'aot': {
'Href': 'https://sentinel-cogs.s3.us-west-2.amazonaws.com/sentinel-s2-l2a-cogs/15/T/UH/2022/12/S2A_15TUH_20221230_0_L2A/AOT.tif'
},
'blue': {
'Href': 'https://sentinel-cogs.s3.us-west-2.amazonaws.com/sentinel-s2-l2a-cogs/15/T/UH/2022/12/S2A_15TUH_20221230_0_L2A/B02.tif'
},
'swir22-jp2': {
'Href': 's3://sentinel-s2-l2a/tiles/15/T/UH/2022/12/30/0/B12.jp2'
},
'visual-jp2': {
'Href': 's3://sentinel-s2-l2a/tiles/15/T/UH/2022/12/30/0/TCI.jp2'
},
'wvp-jp2': {
'Href': 's3://sentinel-s2-l2a/tiles/15/T/UH/2022/12/30/0/WVP.jp2'
}
},
'DateTime': datetime.datetime(2022, 12, 30, 17, 21, 52, 469000, tzinfo = tzlocal()),
'Geometry': {
'Coordinates': [
[
[-95.46676936182894, 43.32623760511659],
[-94.11293433656887, 43.347431265475954],
[-94.09532154452742, 42.35884880571144],
[-95.42776890002203, 42.3383710796791],
[-95.46676936182894, 43.32623760511659]
]
],
'Type': 'Polygon'
},
'Id': 'S2A_15TUH_20221230_0_L2A',
'Properties': {
'EoCloudCover': 62.384969,
'Platform': 'sentinel-2a'
}
}다음 섹션에서는 API 응답의 'Id'키를 사용하여 매니페스트 파일을 생성합니다.
search_raster_data_collection API 응답의 Id키를 사용하여 입력 매니페스트 파일을 생성합니다.
처리 작업을 실행할 때 Amazon S3의 데이터 입력을 지정해야 합니다. 입력 데이터 유형은 개별 데이터 파일을 가리키는 매니페스트 파일일 수 있습니다. 처리할 각 파일에 접두사를 추가할 수도 있습니다. 다음 코드 예제는 매니페스트 파일이 생성될 폴더를 정의합니다.
Python용 SDK(Boto3)를 사용하여 Studio Classic 노트북 인스턴스와 연결된 실행 역할의 기본 버킷과 ARN을 가져옵니다.
sm_session = sagemaker.session.Session()
s3 = boto3.resource('s3')
# Gets the default excution role associated with the notebook
execution_role_arn = sagemaker.get_execution_role()
# Gets the default bucket associated with the notebook
s3_bucket = sm_session.default_bucket()
# Can be replaced with any name
s3_folder = "script-processor-input-manifest"다음으로 매니페스트 파일을 생성합니다. 나중에 4단계에서 처리 작업을 실행할 때 처리하려는 위성 이미지의 URL이 보관됩니다.
# Format of a manifest file
manifest_prefix = {}
manifest_prefix['prefix'] = 's3://' + s3_bucket + '/' + s3_folder + '/'
manifest = [manifest_prefix]
print(manifest)다음 코드 샘플은 매니페스트 파일이 생성될 S3 URI를 반환합니다.
[{'prefix': 's3://sagemaker-us-west-2-111122223333/script-processor-input-manifest/'}]search_raster_data_collection 응답의 모든 응답 요소는 처리 작업을 실행하는 데 필요하지 않습니다.
다음 코드 스니펫은 불필요한 요소 'Properties', 'Geometry', 'DateTime'를 제거합니다. 'Id' 키-값 쌍 'Id': 'S2A_15TUH_20221230_0_L2A'에는 연도와 월이 포함됩니다. 다음 코드 예제는 해당 데이터를 구문 분석하여 Python사전 dict_month_items에 새 키를 만듭니다. 값은 SearchRasterDataCollection쿼리에서 반환되는 자산입니다.
# For each response get the month and year, and then remove the metadata not related to the satelite images.
dict_month_items = {}
for item in items_list:
# Example ID being split: 'S2A_15TUH_20221230_0_L2A'
yyyymm = item['Id'].split("_")[2][:6]
if yyyymm not in dict_month_items:
dict_month_items[yyyymm] = []
# Removes uneeded metadata elements for this demo
item.pop('Properties', None)
item.pop('Geometry', None)
item.pop('DateTime', None)
# Appends the response from search_raster_data_collection to newly created key above
dict_month_items[yyyymm].append(item)다음 코드 예제 는 .upload_file()dict_month_items를 Amazon S3에 JSON 객체로 업로드합니다.
## key_ is the yyyymm timestamp formatted above
## value_ is the reference to all the satellite images collected via our searchRDC query
for key_, value_ in dict_month_items.items():
filename = f'manifest_{key_}.json'
with open(filename, 'w') as fp:
json.dump(value_, fp)
s3.meta.client.upload_file(filename, s3_bucket, s3_folder + '/' + filename)
manifest.append(filename)
os.remove(filename)이 코드 예제는 Amazon S3에 업로드된 다른 모든 매니페스트를 가리키는 상위 manifest.json파일을 업로드합니다. 또한 로컬 변수 s3_manifest_uri의 경로를 저장합니다. 4단계에서 처리 작업을 실행할 때 이 변수를 다시 사용하여 입력 데이터의 소스를 지정하게 됩니다.
with open('manifest.json', 'w') as fp:
json.dump(manifest, fp)
s3.meta.client.upload_file('manifest.json', s3_bucket, s3_folder + '/' + 'manifest.json')
os.remove('manifest.json')
s3_manifest_uri = f's3://{s3_bucket}/{s3_folder}/manifest.json'이제 입력 매니페스트 파일을 만들고 업로드했으므로 처리 작업에서 데이터를 처리하는 스크립트를 작성할 수 있습니다. 위성 이미지의 데이터를 처리하고 NDVI를 계산한 다음 결과를 다른 Amazon S3 위치에 반환합니다.
NDVI를 계산하는 스크립트 작성
Amazon SageMaker Studio Classic은 %%writefile 셀 매직 명령 사용을 지원합니다. 이 명령으로 셀을 실행하면 해당 콘텐츠가 로컬 Studio Classic 디렉터리에 저장됩니다. 이 코드는 NDVI 계산 전용 코드입니다. 하지만 다음은 처리 작업을 위한 스크립트를 직접 작성할 때 유용할 수 있습니다.
-
처리 작업 컨테이너에서 컨테이너 내부의 로컬 경로는
/opt/ml/processing/로 시작해야 합니다. 이 예제에서input_data_path = '/opt/ml/processing/input_data/'과processed_data_path = '/opt/ml/processing/output_data/'는 이러한 방식으로 지정됩니다. -
Amazon SageMaker Processing을 사용하면 처리 작업에서 실행하는 스크립트로 처리된 데이터를 Amazon S3에 직접 업로드할 수 있습니다. 이렇게 하려면
ScriptProcessor인스턴스와 연결된 실행 역할에 S3 버킷에 액세스하는 데 필요한 요구 사항이 있는지 확인하세요. 처리 작업을 실행할 때 출력 파라미터를 지정할 수도 있습니다. 자세히 알아보려면 Amazon SageMaker Python SDK의.run()API 작업을 참조하세요. 이 코드 예제에서는 데이터 처리 결과가 Amazon S3에 직접 업로드됩니다. -
처리 작업에 연결된 Amazon EBS 컨테이너의 크기를 관리하려면
volume_size_in_gb파라미터를 사용하세요. 컨테이너의 기본 크기는 30GB입니다. 또한 Python 라이브러리 가비지 컬렉터를 사용하여 Amazon EBS 컨테이너의 스토리지를 관리할 수도 있습니다. 다음 코드 예제는 배열을 처리 작업 컨테이너로 로드합니다. 배열이 쌓여 메모리를 채우면 처리 작업이 충돌합니다. 이 충돌을 방지하기 위해 다음 예제에는 처리 작업의 컨테이너에서 배열을 제거하는 명령이 포함되어 있습니다.
%%writefile compute_ndvi.py
import os
import pickle
import sys
import subprocess
import json
import rioxarray
if __name__ == "__main__":
print("Starting processing")
input_data_path = '/opt/ml/processing/input_data/'
input_files = []
for current_path, sub_dirs, files in os.walk(input_data_path):
for file in files:
if file.endswith(".json"):
input_files.append(os.path.join(current_path, file))
print("Received {} input_files: {}".format(len(input_files), input_files))
items = []
for input_file in input_files:
full_file_path = os.path.join(input_data_path, input_file)
print(full_file_path)
with open(full_file_path, 'r') as f:
items.append(json.load(f))
items = [item for sub_items in items for item in sub_items]
for item in items:
red_uri = item["Assets"]["red"]["Href"]
nir_uri = item["Assets"]["nir"]["Href"]
red = rioxarray.open_rasterio(red_uri, masked=True)
nir = rioxarray.open_rasterio(nir_uri, masked=True)
ndvi = (nir - red)/ (nir + red)
file_name = 'ndvi_' + item["Id"] + '.tif'
output_path = '/opt/ml/processing/output_data'
output_file_path = f"{output_path}/{file_name}"
ndvi.rio.to_raster(output_file_path)
print("Written output:", output_file_path)이제 NDVI를 계산할 수 있는 스크립트가 생겼습니다. 다음으로 ScriptProcessor 인스턴스를 만들고 처리 작업을 실행할 수 있습니다.
ScriptProcessor 클래스의 인스턴스 생성
이 데모는 Amazon SageMaker Python SDK를 통해 사용할 수 있는 ScriptProcessor.run()메서드를 사용하여 처리 작업을 시작할 수 있습니다.
from sagemaker.processing import ScriptProcessor, ProcessingInput, ProcessingOutput
image_uri = '081189585635.dkr.ecr.us-west-2.amazonaws.com/sagemaker-geospatial-v1-0:latest'
processor = ScriptProcessor(
command=['python3'],
image_uri=image_uri,
role=execution_role_arn,
instance_count=4,
instance_type='ml.m5.4xlarge',
sagemaker_session=sm_session
)
print('Starting processing job.')처리 작업을 시작할 때는 ProcessingInput
-
2단계에서 만든 매니페스트 파일의 경로
s3_manifest_uri입니다. 이 소스는 컨테이너에 대한 입력 데이터의 소스입니다. -
컨테이너에서 입력 데이터를 저장하려는 위치의 경로입니다. 이 경로는 스크립트에서 지정한 경로와 일치해야 합니다.
-
s3_data_type파라미터를 사용하여 입력을"ManifestFile"로 지정합니다.
s3_output_prefix_url = f"s3://{s3_bucket}/{s3_folder}/output"
processor.run(
code='compute_ndvi.py',
inputs=[
ProcessingInput(
source=s3_manifest_uri,
destination='/opt/ml/processing/input_data/',
s3_data_type="ManifestFile",
s3_data_distribution_type="ShardedByS3Key"
),
],
outputs=[
ProcessingOutput(
source='/opt/ml/processing/output_data/',
destination=s3_output_prefix_url,
s3_upload_mode="Continuous"
)
]
)다음 코드 예제에서는 .describe()메서드
preprocessing_job_descriptor = processor.jobs[-1].describe()
s3_output_uri = preprocessing_job_descriptor["ProcessingOutputConfig"]["Outputs"][0]["S3Output"]["S3Uri"]
print(s3_output_uri)matplotlib를 사용하여 결과를 시각화
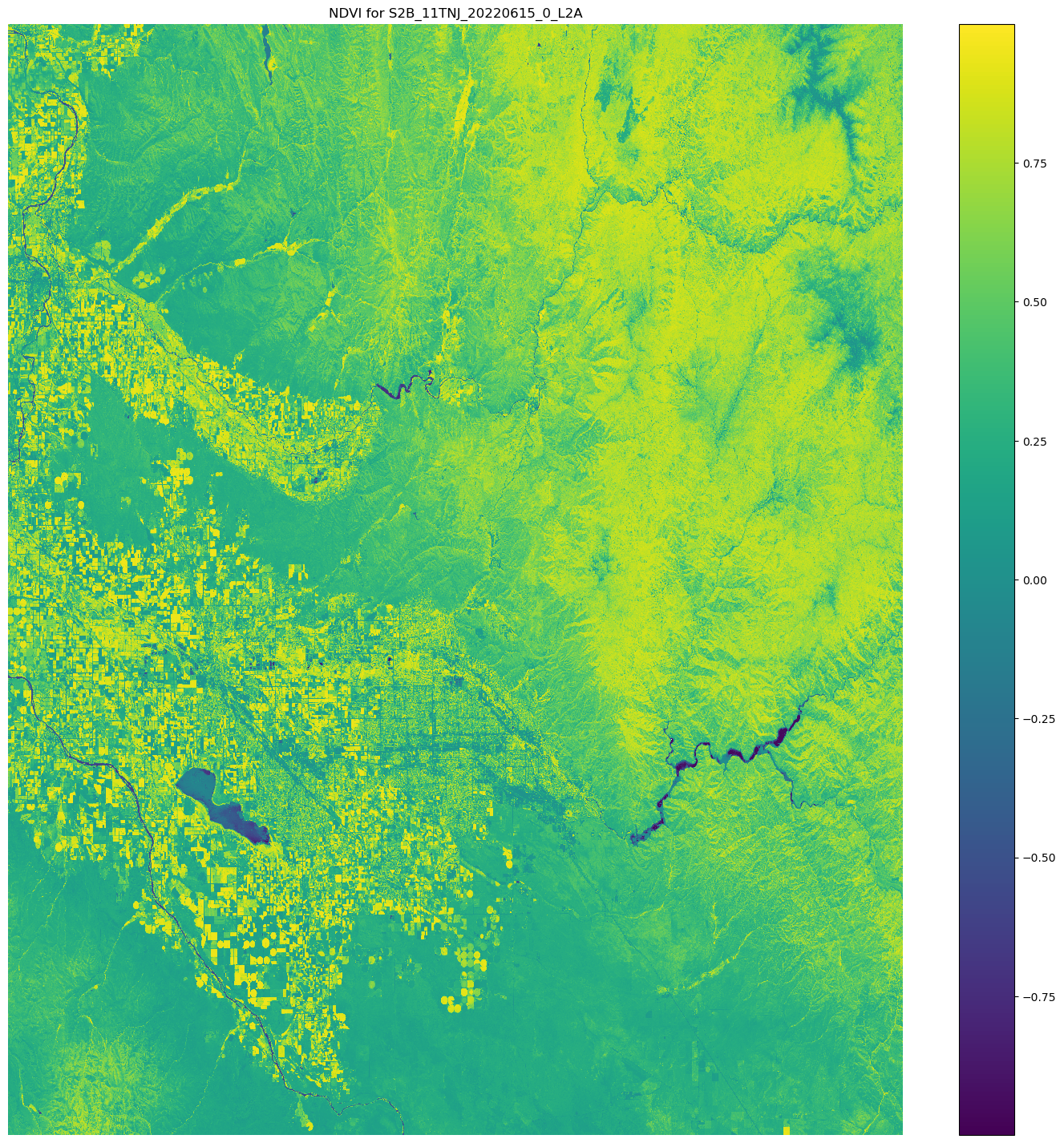
Matplotlib.open_rasterio() API 연산을 사용하여 이미지 배열을 연 다음 Sentinel-2 위성 데이터에서 nir 및 red 이미지 밴드를 이용하여 NDVI를 계산하는 코드입니다.
# Opens the python arrays
import rioxarray
red_uri = items[25]["Assets"]["red"]["Href"]
nir_uri = items[25]["Assets"]["nir"]["Href"]
red = rioxarray.open_rasterio(red_uri, masked=True)
nir = rioxarray.open_rasterio(nir_uri, masked=True)
# Calculates the NDVI
ndvi = (nir - red)/ (nir + red)
# Common plotting library in Python
import matplotlib.pyplot as plt
f, ax = plt.subplots(figsize=(18, 18))
ndvi.plot(cmap='viridis', ax=ax)
ax.set_title("NDVI for {}".format(items[25]["Id"]))
ax.set_axis_off()
plt.show()위 코드 예제의 출력은 NDVI 값이 겹쳐진 위성 이미지입니다. NDVI 값이 1에 가까우면 초목이 많이 있음을 나타내고, 값이 0에 가까우면 초목이 없음을 나타냅니다.
이것으로 ScriptProcessor사용 데모가 완료되었습니다.
