기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
AWS Lambda 함수 계측
참고
X-Ray SDK/데몬 유지 관리 공지 - 2026년 2월 25일에 AWS X-Ray SDKs/데몬은 유지 관리 모드로 전환되며, 여기서 AWS 는 보안 문제만 해결하도록 X-Ray SDK 및 데몬 릴리스를 제한합니다. 지원 일정에 대한 자세한 내용은 X-Ray SDK 및 데몬 지원 타임라인 섹션을 참조하세요. OpenTelemetry로 마이그레이션하는 것이 좋습니다. OpenTelemetry로 마이그레이션하는 방법에 대한 자세한 내용은 X-Ray 계측에서 OpenTelemetry 계측으로 마이그레이션을 참조하세요.
Scorekeep은 두 가지 AWS Lambda 함수를 사용합니다. 첫 번째 함수는 새 사용자를 위한 임의의 이름을 생성하는 lambda 분기의 Node.js 함수입니다. 사용자가 이름을 입력하지 않고 세션을 생성하면 애플리케이션은 AWS SDK for Java를 사용하여 random-name이라는 함수를 호출합니다. Java용 X-Ray SDK는 계측된 AWS SDK 클라이언트로 이루어진 다른 호출과 마찬가지로 Lambda 호출에 대한 정보를 하위 세그먼트에 기록합니다.
참고
random-name Lambda 함수를 실행하려면 Elastic Beanstalk 환경 외부에서 추가 리소스를 생성해야 합니다. 자세한 내용과 지침은 추가 정보 파일(AWS
Lambda Integration
두 번째 함수인 scorekeep-worker는 Scorekeep API와 독립적으로 실행하는 Python 함수입니다. 게임이 끝나면 이 API는 세션 ID와 게임 ID를 SQS 대기열에 씁니다. 작업자 함수는 대기열에서 항목을 읽고 Scorekeep API를 직접 호출하여 Amazon S3에 저장할 각 게임 세션의 전체 레코드를 생성합니다.
Scorekeep에는 두 함수를 모두 생성하기 위한 CloudFormation 템플릿과 스크립트가 포함되어 있습니다. X-Ray SDK를 함수 코드와 함께 번들링해야 하므로 템플릿은 코드가 없는 함수를 생성합니다. Scorekeep를 배포할 때 .ebextensions 폴더에 포함된 구성 파일은 SDK가 포함된 소스 번들을 생성하고 AWS Command Line Interface를 사용하여 함수 코드와 구성을 업데이트합니다.
Random name
사용자가 로그인하지 않거나 사용자 이름을 입력하지 않고 게임 세션을 시작하면 Scorekeep는 random name 함수를 호출합니다. Lambda는 random-name에 대한 직접 호출을 처리할 때 추적 헤더를 읽습니다. 이 헤더에는 Java용 X-Ray SDK가 기록한 추적 ID 및 샘플링 결정이 포함되어 있습니다.
샘플링된 각 요청에 대해 Lambda는 X-Ray 대몬(daemon)을 실행하고 두 개의 세그먼트를 기록합니다. 첫 번째 세그먼트에는 함수를 불러오는 Lambda 직접 호출에 대한 정보가 기록됩니다. 이 세그먼트에는 Scorekeep이 기록하는 하위 세그먼트와 동일한 정보가 포함되지만 Lambda 관점에서 기록됩니다. 두 번째 세그먼트에는 함수가 수행하는 작업이 표현됩니다.
Lambda는 함수 컨텍스트를 통해 함수 세그먼트를 X-Ray SDK에 전달합니다. Lambda 함수를 계측할 때는 SDK를 사용하여 수신 요청에 대한 세그먼트를 생성하지 않습니다. Lambda는 세그먼트를 제공하고, 사용자는 SDK를 사용하여 클라이언트를 계측하고 하위 세그먼트를 작성합니다.
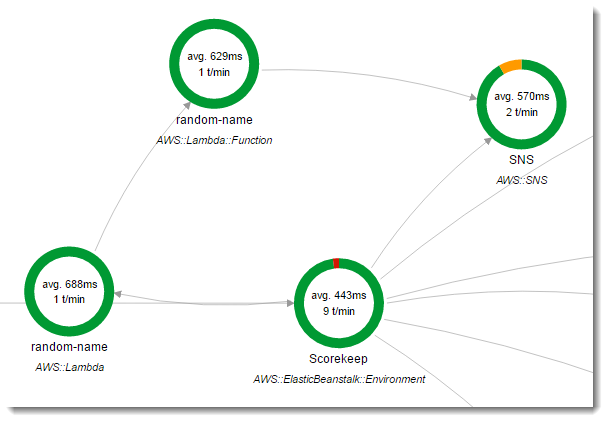
random-name 함수는 Node.js에서 구현됩니다. Node.js의 JavaScript용 SDK를 사용하여 Amazon SNS로 알림을 보내고 Node.js용 X-Ray SDK를 사용하여 AWS SDK 클라이언트를 계측합니다. 주석을 쓰기 위해 이 함수는 AWSXRay.captureFunc를 사용하여 사용자 지정 하위 세그먼트를 만들고 구성된 함수에 주석을 씁니다. Lambda에서는 함수 세그먼트에 주석을 직접 쓸 수 없고 생성한 하위 세그먼트에만 쓸 수 있습니다.
예 function/index.js
var AWSXRay = require('aws-xray-sdk-core');
var AWS = AWSXRay.captureAWS(require('aws-sdk'));
AWS.config.update({region: process.env.AWS_REGION});
var Chance = require('chance');
var myFunction = function(event, context, callback) {
var sns = new AWS.SNS();
var chance = new Chance();
var userid = event.userid;
var name = chance.first();
AWSXRay.captureFunc('annotations', function(subsegment){
subsegment.addAnnotation('Name', name);
subsegment.addAnnotation('UserID', event.userid);
});
// Notify
var params = {
Message: 'Created randon name "' + name + '"" for user "' + userid + '".',
Subject: 'New user: ' + name,
TopicArn: process.env.TOPIC_ARN
};
sns.publish(params, function(err, data) {
if (err) {
console.log(err, err.stack);
callback(err);
}
else {
console.log(data);
callback(null, {"name": name});
}
});
};
exports.handler = myFunction;이 함수는 샘플 애플리케이션을 Elastic Beanstalk에 배포할 때 자동으로 생성됩니다. xray 브랜치에는 빈 Lambda 함수를 생성하기 위한 스크립트가 포함됩니다. .ebextensions 폴더의 구성 파일은 배포 npm install 중에 로 함수 패키지를 빌드한 다음 AWS CLI로 Lambda 함수를 업데이트합니다.
작업자
구성된 작업자 함수는 xray-worker라는 고유 분기에 제공됩니다. 작업자 함수와 관련 리소스를 먼저 생성하지 않은 상태에서는 실행할 수 없기 때문입니다. 지침은 분기 readme
이 기능은 5분마다 번들로 제공되는 Amazon CloudWatch 이벤트에 의해 트리거됩니다. 이 함수가 실행되면 Scorekeep이 관리하는 Amazon SQS 대기열에서 항목을 가져옵니다. 각 메시지에는 완료된 게임에 대한 정보가 들어있습니다.
작업자는 게임 레코드와 게임 레코드가 참조하는 다른 테이블의 게임 문서를 가져옵니다. 예를 들면 DynamoDB의 게임 레코드에는 게임 중 실행된 동작 목록이 포함됩니다. 이 목록에는 이동 자체는 들어 있지 않고, 별도 테이블에 저장된 이동의 ID만 들어 있습니다.
세션과 상태도 참조로 저장됩니다. 따라서 게임 테이블의 항목이 너무 크지 않은 상태로 유지되지만 게임에 대한 모든 정보를 가져오려면 추가 호출이 필요합니다. 작업자는 이러한 모든 항목을 역참조하여 게임의 전체 레코드를 Amazon S3에서 단일 문서로 구성합니다. 데이터에 대한 분석을 수행하려면 읽기 중심의 데이터 마이그레이션을 실행하지 않고 Amazon Athena를 통해 Amazon S3에서 직접 쿼리를 실행하여 DynamoDB에서 데이터를 가져올 수 있습니다.
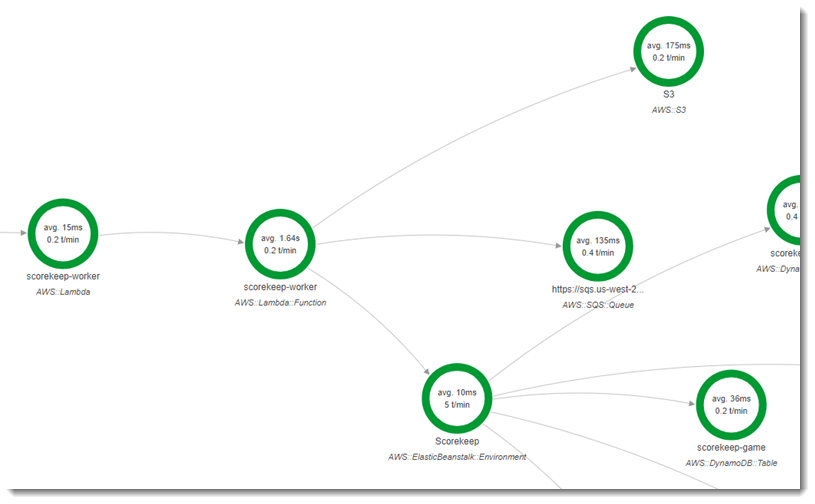
이 작업자 함수는 AWS Lambda의 구성에서 활성 추적이 활성화되어 있습니다. 무작위 이름 함수와 달리 작업자는 계측된 애플리케이션으로부터 요청을 수신하지 않으므로 AWS Lambda 는 추적 헤더를 수신하지 않습니다. Lambda는 활성 추적을 사용하여 추적 ID를 생성하고 샘플링 결정을 내립니다.
Python용 X-Ray SDK는 함수 상단에서 SDK를 가져오고 patch_all 함수를 실행하여 Amazon SQS 및 Amazon S3를 호출하는 데 사용하는 AWS SDK for Python (Boto) 및 HTTclients하는 몇 줄에 불과합니다. 이 작업자가 Scorekeep API를 호출하면 SDK는 추적 헤더를 요청에 추가하여 API를 통해 호출을 추적합니다.
예_lambda/scorekeep-worker/scorekeep-worker.py
import os
import boto3
import json
import requests
import time
from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.core import patch_all
patch_all()
queue_url = os.environ['WORKER_QUEUE']
def lambda_handler(event, context):
# Create SQS client
sqs = boto3.client('sqs')
s3client = boto3.client('s3')
# Receive message from SQS queue
response = sqs.receive_message(
QueueUrl=queue_url,
AttributeNames=[
'SentTimestamp'
],
MaxNumberOfMessages=1,
MessageAttributeNames=[
'All'
],
VisibilityTimeout=0,
WaitTimeSeconds=0
)
...