Aviso de fim do suporte: em 7 de outubro de 2026,AWS o suporte para o.AWS IoT Greengrass Version 1 Depois de 7 de outubro de 2026, você não poderá mais acessar os AWS IoT Greengrass V1 recursos. Para obter mais informações, visite Migrar de AWS IoT Greengrass Version 1.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Executar a inferência de machine learning
Esse recurso está disponível para AWS IoT Greengrass Core v1.6 ou posterior.
Com AWS IoT Greengrass, você pode realizar inferência de aprendizado de máquina (ML) na borda em dados gerados localmente usando modelos treinados na nuvem. Você se beneficia da baixa latência e da redução de custos na execução da inferência local, e ainda aproveita a capacidade de computação em nuvem para modelos de treinamento e processamento complexo.
Para começar a realizar a inferência local, consulte Como configurar a inferência de aprendizado de máquina usando o Console de gerenciamento da AWS.
Como AWS IoT Greengrass A inferência de ML funciona
Você pode treinar seus modelos de inferência em qualquer lugar, implantá-los localmente como recursos de machine learning em um grupo do Greengrass e, em seguida, acessá-los a partir das funções do Lambda do Greengrass. Por exemplo, você pode criar e treinar modelos de aprendizado profundo em SageMaker IA
O diagrama a seguir mostra o fluxo de trabalho AWS IoT Greengrass de inferência de ML.
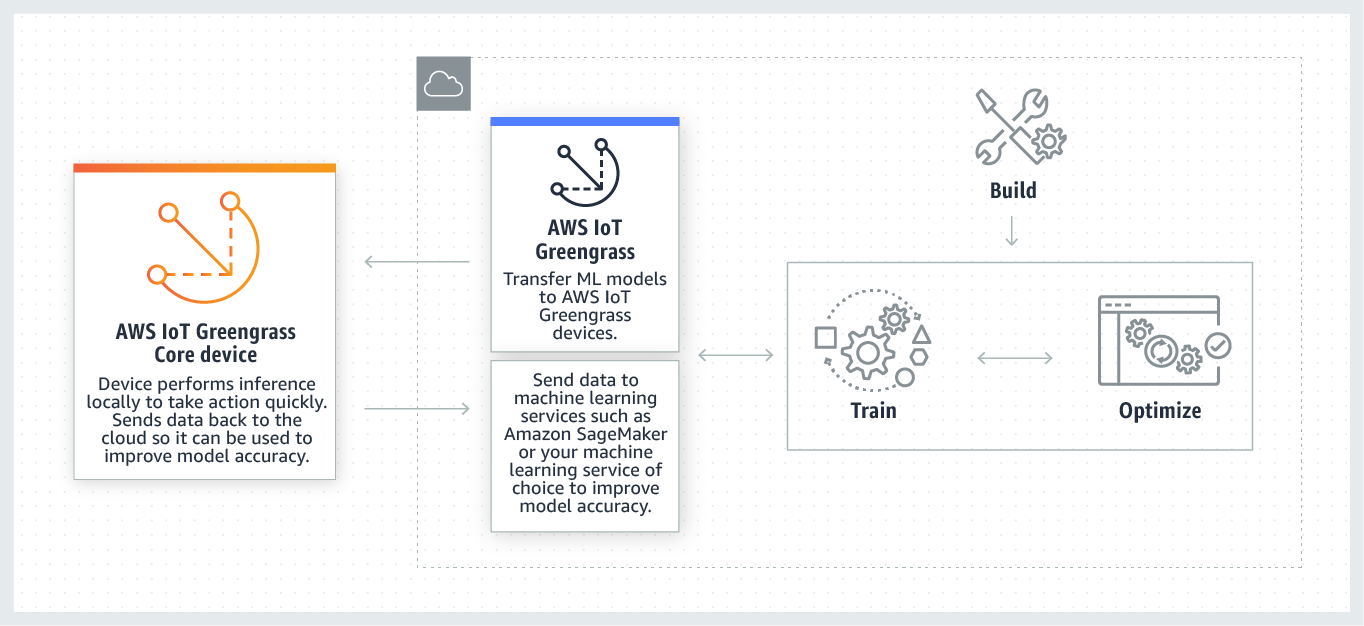
AWS IoT Greengrass A inferência de ML simplifica cada etapa do fluxo de trabalho de ML, incluindo:
-
Criação e implantação de protótipos de estrutura do ML.
-
Acesso aos modelos treinados em nuvem e implementação em dispositivos de núcleo do Greengrass.
-
Criação de aplicativos de inferência que podem acessar aceleradores de hardware (por exemplo, GPUs e FPGAs) como recursos locais.
Recursos de machine learning
Os recursos de aprendizado de máquina representam modelos de inferência treinados na nuvem que são implantados em um núcleo. AWS IoT Greengrass Para implantar recursos de machine learning, primeiro adicione os recursos a um grupo do Greengrass e defina como as funções do Lambda no grupo poderão acessá-los. Durante a implantação em grupo, AWS IoT Greengrass recupera os pacotes do modelo de origem da nuvem e os extrai para diretórios dentro do namespace de tempo de execução do Lambda. Em seguida, as funções do Lambda do Greengrass usam os modelos implantados localmente para realizar a inferência.
Para atualizar um modelo implantado localmente, primeiro atualize o modelo de origem (na nuvem) que corresponde ao recurso de machine learning e, em seguida, implemente o grupo. Durante a implantação, o AWS IoT Greengrass verifica se há alterações na origem. Se forem detectadas alterações, AWS IoT Greengrass atualiza o modelo local.
Fontes de modelo compatíveis
AWS IoT Greengrass suporta fontes de modelos de SageMaker IA e Amazon S3 para recursos de aprendizado de máquina.
Os requisitos a seguir se aplicam a fontes de modelo:
-
Os buckets do S3 que armazenam suas fontes de modelos de SageMaker IA e Amazon S3 não devem ser criptografados usando. SSE-C Para buckets que usam criptografia do lado do servidor, a inferência de AWS IoT Greengrass ML atualmente oferece suporte somente às opções de criptografia ou. SSE-S3 SSE-KMS Para obter mais informações sobre as opções criptografia no lado do servidor, consulte Protegendo dados usando criptografia no lado do servidor no Guia do usuário do Amazon Simple Storage Service.
-
Os nomes dos buckets do S3 que armazenam suas fontes de modelos de SageMaker IA e Amazon S3 não devem incluir pontos ().
.Para obter mais informações, consulte a regra sobre como usar buckets hospedados virtualmente com SSL em Regras para nomenclatura de buckets no Guia do usuário do Amazon Simple Storage Service. -
Service-level Região da AWS o suporte deve estar disponível para ambos AWS IoT Greengrasse para a SageMaker IA. Atualmente, AWS IoT Greengrass oferece suporte a modelos de SageMaker IA nas seguintes regiões:
-
Leste dos EUA (Ohio)
-
Leste dos EUA (N. da Virgínia)
-
Oeste dos EUA (Oregon)
-
Ásia-Pacífico (Mumbai)
-
Ásia-Pacífico (Seul)
-
Ásia-Pacífico (Singapura)
-
Ásia-Pacífico (Sydney)
-
Ásia-Pacífico (Tóquio)
-
Europa (Frankfurt)
-
Europa (Irlanda)
-
Europa (Londres)
-
-
AWS IoT Greengrass deve ter
readpermissão para acessar a fonte do modelo, conforme descrito nas seções a seguir.
- SageMaker AI
-
AWS IoT Greengrass oferece suporte a modelos que são salvos como trabalhos de treinamento de SageMaker IA. SageMaker A IA é um serviço de ML totalmente gerenciado que você pode usar para criar e treinar modelos usando algoritmos integrados ou personalizados. Para obter mais informações, consulte O que é SageMaker IA? no Guia do desenvolvedor de SageMaker IA.
Se você configurou seu ambiente de SageMaker IA criando um bucket cujo nome contém
sagemaker, então AWS IoT Greengrass tem permissão suficiente para acessar seus trabalhos de treinamento de SageMaker IA. A política gerenciadaAWSGreengrassResourceAccessRolePolicypermite o acesso a buckets cujo nome contém a stringsagemaker. Esta política é anexada à função de serviço do Greengrass.Caso contrário, você deverá conceder AWS IoT Greengrass
readpermissão ao bucket em que seu trabalho de treinamento está armazenado. Para fazer isso, incorpore a seguinte política em linha no perfil de serviço. Você pode listar vários ARNs do bucket. - Amazon S3
-
AWS IoT Greengrass suporta modelos que são armazenados no Amazon S3 como
tar.gzarquivos..zipPara permitir o acesso AWS IoT Greengrass aos modelos armazenados nos buckets do Amazon S3, você deve conceder AWS IoT Greengrass
readpermissão para acessar os buckets fazendo o seguinte:-
Armazene seu modelo em um recipiente cujo nome contém
greengrass.A política gerenciada
AWSGreengrassResourceAccessRolePolicypermite o acesso a buckets cujo nome contém a stringgreengrass. Esta política é anexada à função de serviço do Greengrass. -
Incorpore uma política inline na função de serviço do Greengrass.
Se o nome do seu intervalo não contiver
greengrass, adicione a seguinte política inline à função de serviço. Você pode listar vários ARNs do bucket.Para mais informações, consulte Incorporando políticas inline no Guia do usuário do IAM.
-
Requisitos
Os requisitos a seguir se aplicam para criar e usar recursos de machine learning:
-
Você deve estar usando o AWS IoT Greengrass Core v1.6 ou posterior.
-
User-defined As funções Lambda podem executar
readouread and writeoperar no recurso. Permissões para outras operações não estão disponíveis. O modo de conteinerização das funções afiliadas do Lambda determina as permissões de acesso são definidas. Para obter mais informações, consulte Acesse os recursos de machine learning das funções do Lambda. -
Você precisa fornecer o caminho completo do recurso no sistema operacional do dispositivo de núcleo.
-
Um nome de recurso ou ID tem um comprimento máximo de 128 caracteres e deve usar o padrão
[a-zA-Z0-9:_-]+.
Tempos de execução e bibliotecas para inferência de ML
Você pode usar os seguintes tempos de execução e bibliotecas de ML com AWS IoT Greengrass.
-
Tempo de execução de aprendizado profundo do Amazon SageMaker Neo
-
Apache MXNet
-
TensorFlow
Esses tempos de execução e bibliotecas podem ser instalados nas plataformas NVIDIA Jetson TX2, Intel Atom e Raspberry Pi. Para baixar as informações, consulte Bibliotecas e tempos de execução de machine learning compatíveis. Você pode instalá-los diretamente no dispositivo principal.
Leia as seguintes informações sobre compatibilidade e limitações.
SageMaker Tempo de execução de aprendizado profundo AI Neo
Você pode usar o tempo de execução de aprendizado profundo SageMaker AI Neo para realizar inferências com modelos otimizados de aprendizado de máquina em seus AWS IoT Greengrass dispositivos. Esses modelos são otimizados usando o compilador de aprendizado profundo SageMaker AI Neo para melhorar as velocidades de previsão de inferência de aprendizado de máquina. Para obter mais informações sobre otimização de modelos em SageMaker IA, consulte a documentação do SageMaker AI Neo.
nota
No momento, é possível otimizar modelos de machine learning usando o compilador de aprendizado profundo do Neo somente em Regiões específicas da Amazon Web Services. No entanto, você pode usar o tempo de execução de aprendizado profundo Neo com modelos otimizados em cada um Região da AWS onde o AWS IoT Greengrass núcleo é suportado. Para obter informações, consulte Como configurar a inferência otimizada de Machine Learning.
Versionamento do MXNet
O Apache MXNet atualmente não garante compatibilidade com versões futuras, portanto, os modelos que você treina usando versões posteriores da estrutura podem não funcionar corretamente em versões anteriores da estrutura. Para evitar conflitos entre os estágios de treinamento de modelo e a veiculação de modelo e fornecer uma experiência completa e consistente, use a mesma versão de estrutura do MXNet em ambos os estágios.
MXNet no Raspberry Pi
As funções do Lambda do Greengrass que acessam modelos locais do MXNet devem definir a seguinte variável de ambiente:
MXNET_ENGINE_TYPE=NativeEngine
É possível definir a variável de ambiente no código da função ou adicioná-la à configuração específica do grupo da função. Para um exemplo que a adiciona como uma configuração, consulte esta etapa.
nota
Para uso geral da estrutura do MXNet, como executar um exemplo de código de terceiros, a variável de ambiente deve ser configurada no Raspberry Pi.
TensorFlow limitações de fornecimento de modelos no Raspberry Pi
As recomendações a seguir para melhorar os resultados da inferência são baseadas em nossos testes com as bibliotecas Arm de TensorFlow 32 bits na plataforma Raspberry Pi. Estas recomendações são destinadas apenas para usuários avançados, sem garantias de qualquer tipo.
-
Modelos treinados usando o formato de ponto de verificação
deve ser "congelado" para o formato de buffer de protocolo antes do fornecimento. Para ver um exemplo, consulte a biblioteca de modelos de classificação de TensorFlow-Slim imagens . -
Não use as TF-Slim bibliotecas TF-Estimator and em código de treinamento ou inferência. Em vez disso, use o arquivo
.pbpadrão de carregamento do modelo mostrado no exemplo a seguir.graph = tf.Graph() graph_def = tf.GraphDef() graph_def.ParseFromString(pb_file.read()) with graph.as_default(): tf.import_graph_def(graph_def)
nota
Para obter mais informações sobre as plataformas suportadas pelo TensorFlow, consulte Instalação TensorFlow
