As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Esta seção fornece informações para detectar rótulos em imagens e vídeos com o Amazon Rekognition Image e o Amazon Rekognition Video.
Um rótulo ou tag é um objeto ou conceito (incluindo cenas e ações) encontrado em uma imagem ou vídeo com base em seu conteúdo. Por exemplo, uma imagem de pessoas em uma praia tropical pode conter rótulos como Palmeira (objeto), Praia (cena), Corrida (ação) e Ao ar livre (conceito).
Rótulos compatíveis com as operações de detecção de rótulos do Rekognition
nota
O Amazon Rekognition faz previsões binárias de gênero (homem, mulher, menina etc.) com base na aparência física de uma pessoa em uma imagem específica. Esse tipo de previsão não foi projetado para categorizar a identidade de gênero de uma pessoa, e você não deve usar o Amazon Rekognition para fazer essa determinação. Por exemplo, um ator masculino usando uma peruca de cabelos compridos e brincos para um papel pode ser considerado feminino.
Usar o Amazon Rekognition para fazer previsões binárias de gênero é mais adequado para casos de uso em que estatísticas agregadas de distribuição por gênero precisam ser analisadas sem identificar usuários específicos. Por exemplo, a porcentagem de usuários que são mulheres em comparação com homens em uma plataforma de mídia social.
Não recomendamos o uso de previsões binárias de gênero para tomar decisões que afetam os direitos, a privacidade ou o acesso de um indivíduo aos serviços.
O Amazon Rekognition devolve etiquetas em inglês. Você pode usar o Amazon Translate
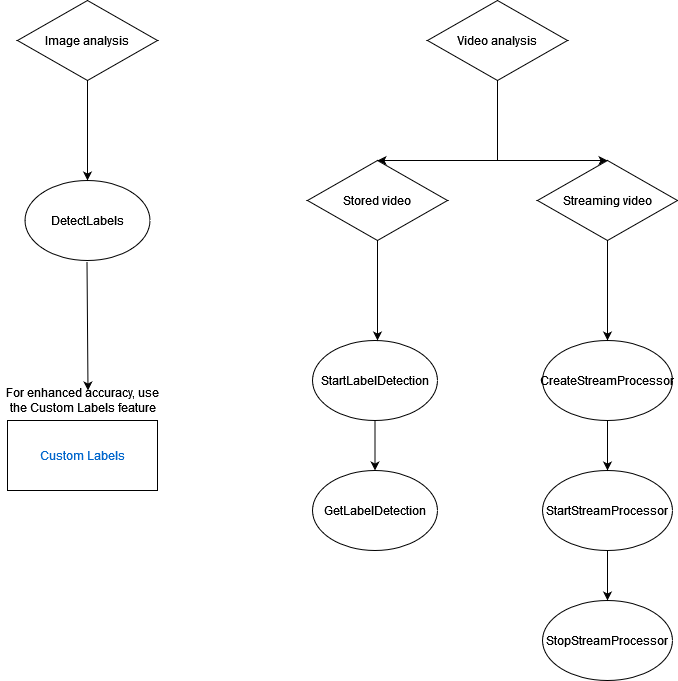
O diagrama a seguir mostra a ordem das operações de chamada, dependendo de suas metas de uso das operações do Amazon Rekognition Image ou do Amazon Rekognition Video:
Objetos de resposta de rótulos
Caixas delimitadoras
O Amazon Rekognition Image e o Amazon Rekognition Video podem devolver a caixa delimitadora para rótulos de objetos comuns, como carros, móveis, roupas ou animais de estimação. As informações da caixa delimitadora não são retornadas para rótulos de objetos menos comuns. Você pode usar caixas delimitadoras para encontrar as localizações exatas de objetos em uma imagem, contar instâncias de objetos detectados ou para medir o tamanho de um objeto usando as dimensões da caixa delimitadora.
Por exemplo, na imagem a seguir, o Amazon Rekognition Image é capaz de detectar a presença de uma pessoa, um skate, carros estacionados e outras informações. O Amazon Rekognition Image também retorna a caixa delimitadora de uma pessoa detectada e de outros objetos detectados, como carros e rodas.

Escore de confiança
O Amazon Rekognition Video e o Amazon Rekognition Image fornecem uma pontuação percentual da confiança que o Amazon Rekognition tem na precisão de cada rótulo detectado.
Pais
O Amazon Rekognition Image e o Amazon Rekognition Video usam uma taxonomia hierárquica de rótulos ancestrais para categorizá-los. Por exemplo, uma pessoa caminhando em uma rua pode ser detectada como um Pedestre. O rótulo pai de um Pedestre é Pessoa. Ambos os rótulos são retornados na resposta. Todos os rótulos ancestrais são retornados e cada rótulo contém uma lista do pai e de outros rótulos ancestrais. Por exemplo, rótulos de avós e bisavós, se existirem. Você pode usar rótulos pai para criar grupos de rótulos relacionados e permitir a consulta de rótulos semelhantes em uma ou mais imagens. Por exemplo, uma consulta para todos os Veículos pode retornar um carro de uma imagem e uma moto de outra.
Categorias
O Amazon Rekognition Image e o Amazon Rekognition Video retornam informações sobre categorias de etiquetas. Os rótulos fazem parte de categorias que agrupam rótulos individuais com base em funções e contextos comuns, como "Veículos e automóveis" e "Alimentos e bebidas". Uma categoria de rótulo pode ser uma subcategoria de uma categoria principal.
Aliases
Além de devolver etiquetas, o Amazon Rekognition Image e o Amazon Rekognition Video retornam quaisquer aliases associados à etiqueta. Os aliases são rótulos com o mesmo significado ou rótulos que são visualmente intercambiáveis com o rótulo principal retornado. Por exemplo, "Cell Phone" é um alias de "Mobile Phone".
Nas versões anteriores, o Amazon Rekognition Image retornava aliases como "Celular" na mesma lista de nomes de rótulos primários que continha "Dispositivo móvel". Agora, o Amazon Rekognition Image retorna "Celular" em um campo chamado "aliases" e "Dispositivo móvel" na lista de nomes de etiquetas primárias. Se seu aplicativo depende das estruturas retornadas por uma versão anterior do Rekognition, talvez seja necessário transformar a resposta atual retornada pelas operações de detecção de rótulos de imagem ou vídeo na estrutura de resposta anterior, na qual todos os rótulos e aliases são retornados como rótulos primários.
Se você precisar transformar a resposta atual da DetectLabels API (para detecção de rótulos em imagens) na estrutura de resposta anterior, veja o exemplo de código emTransformando a resposta DetectLabels.
Se você precisar transformar a resposta atual da GetLabelDetection API (para detecção de rótulos em vídeos armazenados) na estrutura de resposta anterior, veja o exemplo de código emTransformando a resposta GetLabelDetection .
Propriedades da imagem
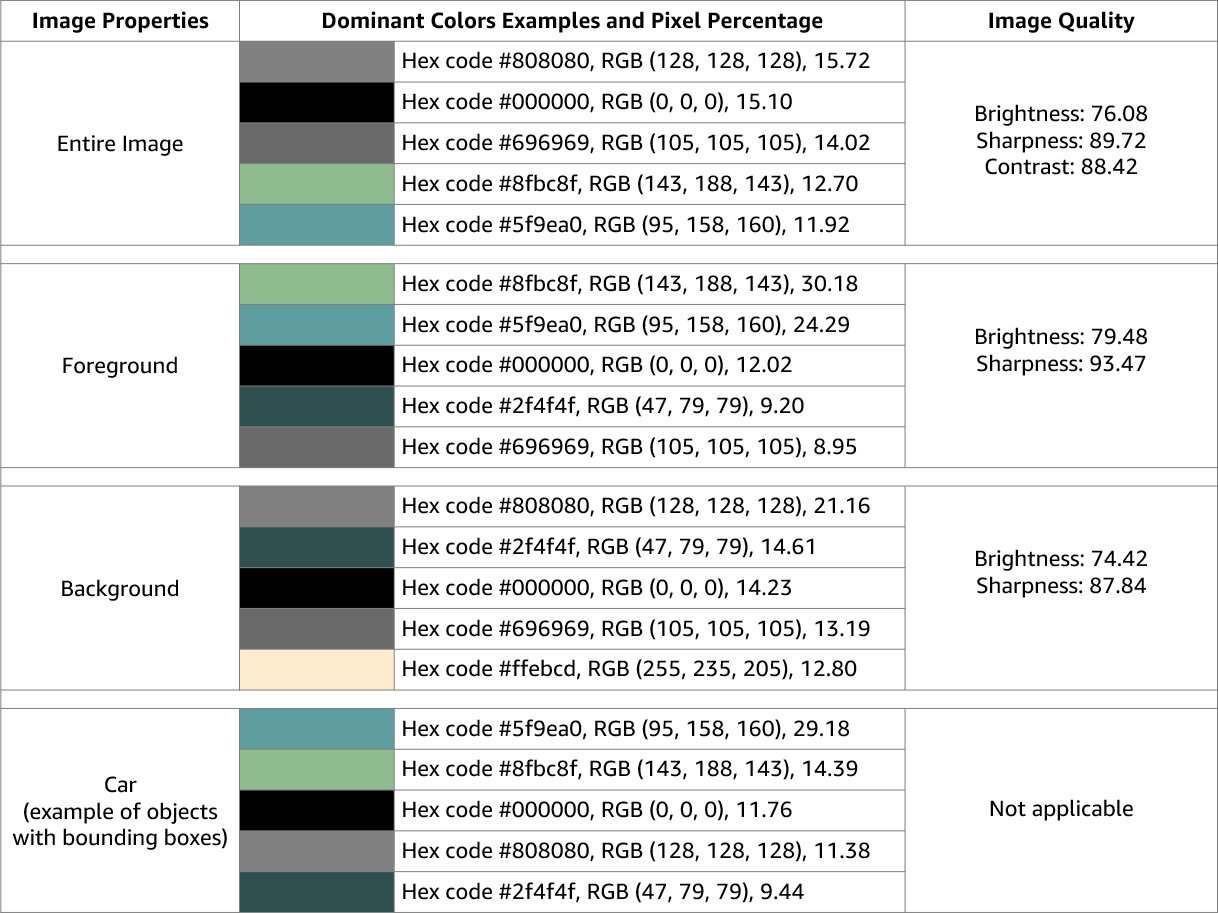
O Amazon Rekognition Image retorna informações sobre a qualidade da imagem (nitidez, brilho e contraste) de toda a imagem. A nitidez e o brilho também são retornados para o primeiro plano e o plano de fundo da imagem. As propriedades da imagem também podem ser usadas para detectar cores dominantes de toda a imagem, primeiro plano, fundo e objetos com caixas delimitadoras.

Veja a seguir um exemplo dos ImageProperties dados contidos na resposta de uma DetectLabels operação para a imagem em andamento:
As propriedades da imagem não estão disponíveis para o Amazon Rekognition Video.
Versão do modelo
Tanto o Amazon Rekognition Image quanto o Amazon Rekognition Video retornam a versão do modelo de detecção de rótulos usado para detectar rótulos em uma imagem ou vídeo armazenado.
Filtros de inclusão e exclusão
Você pode filtrar os resultados retornados pelas operações de detecção de rótulos do Amazon Rekognition Image e do Amazon Rekognition Video. Filtre os resultados fornecendo critérios de filtragem para rótulos e categorias. Os filtros de etiquetas podem ser inclusivos ou exclusivos.
Consulte Detectar rótulos em uma imagem para obter mais informações sobre a filtragem dos resultados obtidos com DetectLabels.
Consulte Detectando rótulos em um vídeo para obter mais informações sobre a filtragem dos resultados obtidos por GetLabelDetection.
Classificação e agregação de resultados
Os resultados obtidos de determinadas operações do Amazon Rekognition Video podem ser classificados e agregados de acordo com registros de data e hora e segmentos de vídeo. Ao recuperar os resultados de um trabalho de Detecção de Rótulos ou Moderação de Conteúdo, com GetLabelDetection ou GetContentModeration respectivamente, você pode usar os argumentos AggregateBy e SortBy para especificar como deseja que seus resultados sejam retornados. Você pode usar SortBy com TIMESTAMP ou NAME (nomes de rótulos) e usar TIMESTAMPS ou SEGMENTS com o AggregateBy argumento.
