本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
通过同构数据迁移从 PostgreSQL 数据库迁移数据 AWS DMS
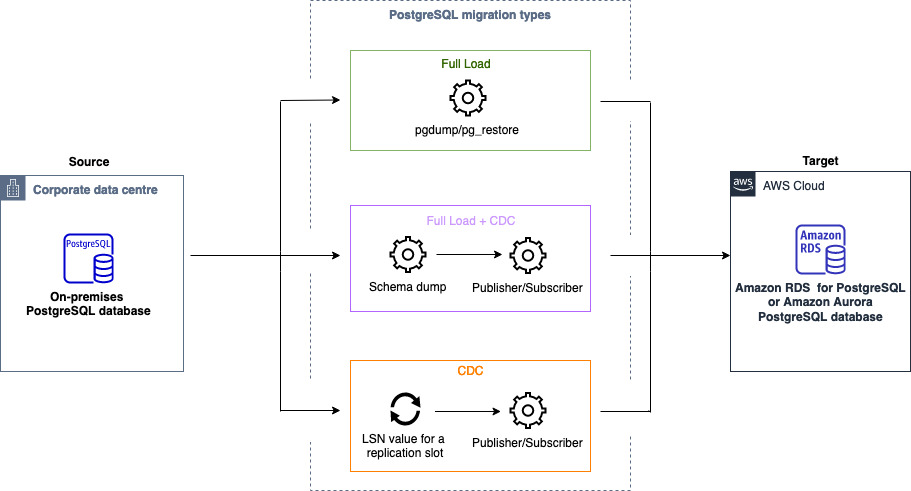
您可以使用同构数据迁移,将自管理 PostgreSQL 数据库迁移到 RDS for PostgreSQL 或 Aurora PostgreSQL。 AWS DMS 会为数据迁移创建无服务器环境。对于不同类型的数据迁移, AWS DMS 会使用不同的本机 PostgreSQL 数据库工具。
对于满负荷类型的同构数据迁移, AWS DMS 使用 pg_dump 从源数据库读取数据并将其存储在连接到无服务器环境的磁盘上。 AWS DMS 读取所有源数据后,它使用目标数据库中的 pg_restore 来恢复您的数据。
对于完全加载和更改数据捕获 (CDC) 类型的同构数据迁移, AWS DMS 使用pg_dump从源数据库中读取没有表数据的架构对象,并将它们存储在连接到无服务器环境的磁盘上。然后使用目标数据库中的 pg_restore 还原架构对象。 AWS DMS 完成该pg_restore过程后,它会自动切换到发布者和订阅者模式进行逻辑复制,Initial Data Synchronization可以选择将初始表数据直接从源数据库复制到目标数据库,然后启动正在进行的复制。在此模式中,一个或多个订阅用户会订阅发布者节点上的一个或多个发布。
对于变更数据捕获 (CDC) 类型的同构数据迁移, AWS DMS 需要本机起点才能开始复制。如果您提供了本机起点,则会 AWS DMS 捕获从该点开始的更改。或者,在数据迁移设置中选择立即,以便在实际数据迁移开始时自动捕获复制的开始点。
注意
要使 CDC-only 迁移工作正常,所有源数据库架构和对象都必须已存在于目标数据库中。不过,目标可能具有源上不存在的对象。
您可以使用以下代码示例获取 PostgreSQL 数据库中的本机开始点。
select confirmed_flush_lsn from pg_replication_slots where slot_name=‘migrate_to_target';
此查询使用 PostgreSQL 数据库中的 pg_replication_slots 视图,捕获日志序列号(LSN)值。
将 PostgreSQL 同构数据迁移的状态 AWS DMS 设置为 “已停止” 、 “失败” 或 “已删除” 后,不会删除发布者和复制。如果您不希望恢复迁移,可使用以下命令删除复制时隙和发布者。
SELECT pg_drop_replication_slot('migration_subscriber_{ARN}'); DROP PUBLICATION publication_{ARN};
下图显示了使用同构数据迁移将 PostgreSQL 数据库迁移 AWS DMS 到适用于 PostgreSQL 的 RDS 或 Aurora PostgreSQL 的过程。
使用 PostgreSQL 数据库作为同构数据迁移的源的最佳实践
要加快 FLCDC 任务在订阅用户端的初始数据同步,必须调整
max_logical_replication_workers和max_sync_workers_per_subscription。增加这些值可以提高表的同步速度。max_logical_replication_workers – 指定逻辑复制工作线程的最大数量。这既包括订阅用户端的应用工作线程,也包括表同步工作线程。
max_sync_workers_per_subscription – 增加
max_sync_workers_per_subscription只会影响并行同步的表的数量,而不会影响每个表的工作线程的数量。
注意
max_logical_replication_workers不应超过max_worker_processes,max_sync_workers_per_subscription应小于或等于max_logical_replication_workers。要迁移大型表,请考虑使用选择规则将它们分成几项单独的任务。例如,您可以将大型表分成几项单独的任务,将小型表分成另一项单独的任务。
监控订阅用户端的磁盘和 CPU 使用率,以保持出色性能。
