本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
訓練您的第一個 AWS DeepRacer 模型
本逐步解說示範如何使用 AWS DeepRacer 主控台訓練您的第一個模型。
使用 AWS DeepRacer 主控台訓練強化學習模型
了解如何在 AWS DeepRacer 主控台中找到 [建立模型] 按鈕,以開始您的模型訓練之旅。
訓練強化學習模型
-
如果這是您第一次使用 AWS DeepRacer,請從服務登陸頁面選擇「建立模型」,或在主導覽窗格的「強化學習」標題下選取「開始使用」。
-
在「開始使用強化學習」頁面的「步驟 2:建立模型」下,選擇「建立模型」。
或者,從主要導覽窗格中,選擇鋼筋學習標題下的您的模型。在 Your Models (您的模型) 頁面中,選擇 Create model (建立模型)。
指定模型名稱和環境
為您的模型命名,並瞭解如何挑選適合您的模擬軌跡。
指定模型名稱和環境
-
在「建立模型」頁面的「訓練詳細資料」下,輸入模型的名稱。
-
您可以選擇新訓練工作描述。
-
若要進一步瞭解如何新增選用標籤,請參閱標記。
-
在環境模擬下,選擇要做為 AWS DeepRacer 代理程式培訓環境的軌道。在軌道方向下,選擇順時針或逆時針。然後選擇 Next (下一步)。
初次執行時,請選擇形狀簡單且轉彎順暢的軌道。在稍後的反覆執行中,您可以選擇更複雜的軌道,漸進式地改善您的模型。若要針對特定競賽事件訓練模型,請選擇與事件軌道最相近的軌道。
-
選擇頁面底部的 Next (下一步)。
選擇比賽類型和訓練算法
AWS 主 DeepRacer 控台有三種競賽類型和兩種訓練演算法可供選擇。了解哪些適合您的技能水平和培訓目標。
選擇競賽類型和訓練演算法
-
在「建立模型」頁面的「競賽類型」下,選取「計時賽」、「避免物件」或「H」ead-to-bot。
對於您的第一次運行,我們建議您選擇時間試用。如需針對此競賽類型最佳化客服感測器組態的指引,請參閱為時間試用量身打造 AWS DeepRacer 培訓。
-
或者,在稍後的跑步中,選擇「避免物件」以繞過放置在所選軌道上固定或隨機位置的固定障礙物。如需詳細資訊,請參閱為避免物件競賽量身打造 AWS DeepRacer 培訓。
-
選擇「固定位置」,在軌道的兩條車道上,在使用者指定的固定位置產生方塊,或選取「隨機位置」,以產生在訓練模擬每個單集開始時隨機分配到兩條車道上的物件。
-
接下來,為軌道上的對象數量選擇一個值。
-
如果您選擇「固定位置」,則可以調整每個物件在軌道上的位置。對於「車道放置」,請在內側車道和外側車道之間進行選擇。依預設,物件會平均分佈在軌道上。若要變更物件的起點與終點線之間的距離,請在「起始與終點之間的位置 (%)」欄位中輸入 7 到 90 之間距離的百分比。
-
-
或者,對於更雄心勃勃的跑步,請選擇 Head-to-bot Racing 來與最多四輛以恆定速度移動的機器人車輛競賽。如需進一步了解,請參閱 為 head-to-bot 比賽量身打造 AWS DeepRacer 培訓。
-
在「選擇機器人車輛數量」下,選擇您希望代理訓練的機器人車輛數量。
-
接下來,選擇您希望機器人車輛在軌道上行駛的速度(以毫米/秒為單位)。
-
選擇性地勾選「啟用車道變更」方塊,讓機器人車輛能夠每 1-5 秒隨機變更車道。
-
-
在 [訓練演算法和超參數] 底下,選擇 [軟性演員評論家 (SAC)] 或 [近端原則最佳化 (PPO)] 演算法。在 AWS 主 DeepRacer控台中,SAC 模型必須在連續的動作空間中進行訓練。PPO 模型可以在連續或離散的動作空間中進行訓練。
-
在訓練演算法和超參數下,依原樣使用預設的超參數值。
稍後,如要改善培訓效能,請展開 Hyperparameters (超參數) 並修改預設超參數值如下:
-
針對 Gradient descent batch size (梯度下降批次大小),請選擇可用選項。
-
針對 Number of epochs (epoch 數),設定有效值。
-
針對 Learning rate (學習率),設定有效值。
-
若為 SAC 阿爾法值 (僅限 SAC 演算法),請設定有效值。
-
針對 Entropy (熵),設定有效值。
-
針對 Discount factor (折扣係數),設定有效值。
-
針對 Loss type (損失類型),選擇可用選項。
-
針對 Number of experience episodes between each policy-updating iteration (每次政策更新反覆操作間的經驗回合數),設定有效值。
如需超參數的詳細資訊,請參閱系統地調整超參數。
-
-
選擇 下一步。
定義動作空間
在「定義動作空間」頁面上,如果您已選擇使用「軟演員評論家」(SAC) 演算法進行訓練,則預設動作空間為連續動作空間。如果您已選擇使用近端原則最佳化 (PPO) 演算法進行訓練,請在 [連續動作空間] 和 [離散動作空間] 之間進行選擇。要了解有關每個動作空間和算法如何塑造代理的培訓體驗的更多信息,請參閱AWS DeepRacer 動作空間和獎勵功能。
-
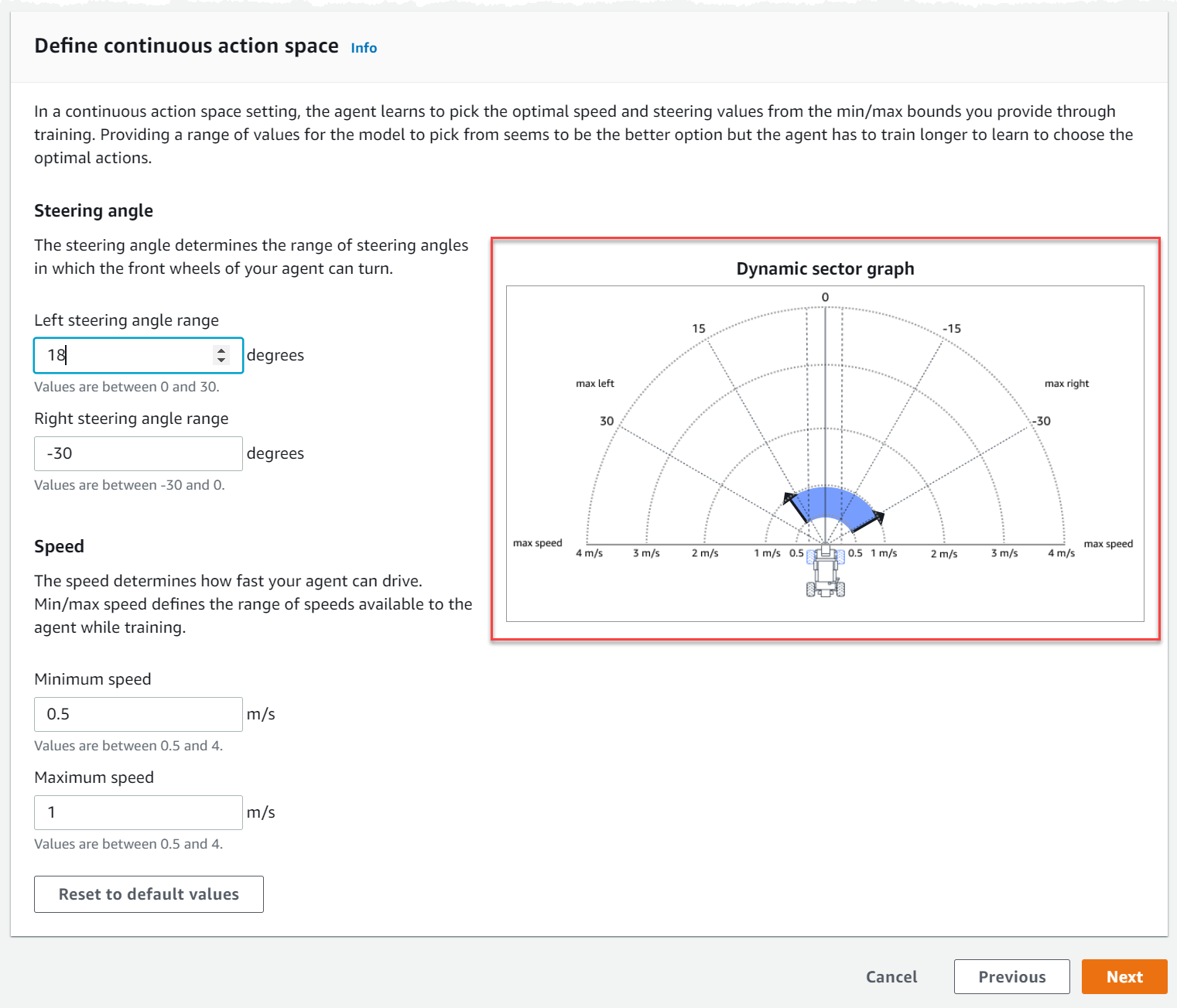
在定義連續動作空間之下,選擇左轉向角度範圍的度數和右轉向角度範圍。
嘗試為每個轉向角度範圍輸入不同的角度,然後觀看範圍變化的視覺效果,以在動態扇區圖表上代表您的選擇。
-
在速度下,輸入代理程式的最小和最大速度 (以公釐/秒為單位)。
請注意您的變更如何反映在動態扇區圖上。
-
或者,選擇「重設為預設值」以清除不需要的值。我們鼓勵在圖表上嘗試不同的值進行實驗和學習。
-
選擇 下一步。
-
從下拉式清單中選擇轉向角度粒度的值。
-
為代理的最大轉向角度選擇介於 1-30 之間的值。
-
從下拉式清單選擇速度粒度的值。
-
選擇一個介於 0.1-4 之間的毫米/秒值作為代理的最大速度。
-
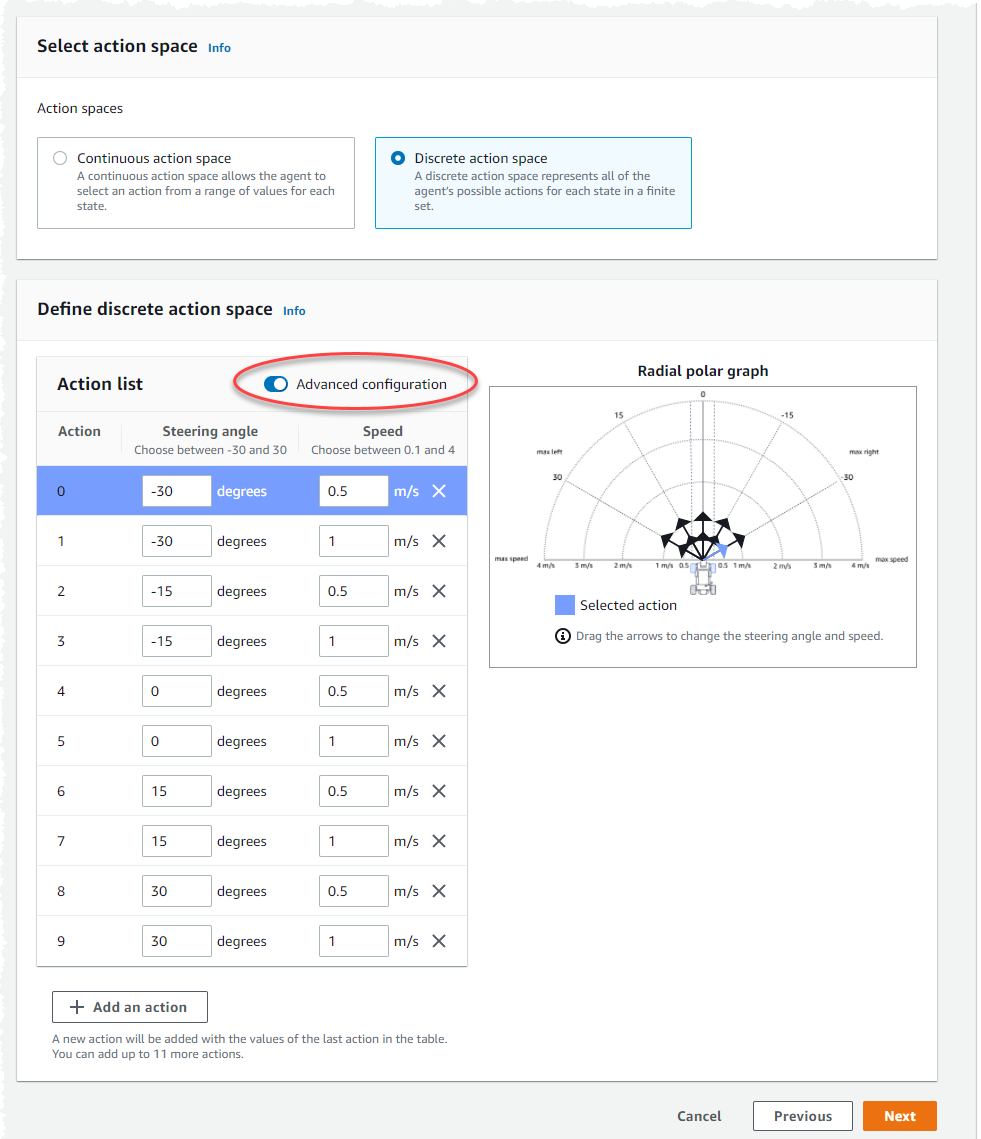
使用 [動作] 清單上的預設動作設定,或選擇性地切換 [進階組態] 來微調您的設定。如果您選擇「上一步」或在調整值後關閉「進階」組態,則會遺失變更。
-
在「轉向角度」欄中輸入介於 -30 到 30 之間的度數值。
-
在「速度」欄中輸入介於 0.1 到 4 之間的值 (以公釐/秒為單位),最多可執行九個動作。
-
(可選) 選取「新增動作」以增加動作清單中的列數。
![影像:選取 [新增動作],將動作新增至動作清單。](images/deepracer-add-an-action.png)
-
或者,選取列上的 X 以將其移除。
-
-
選擇 下一步。
選擇虛擬汽車
了解如何開始使用虛擬汽車。每個月參加公開賽,賺取新的自定義車,油漆工作和修改。
選擇虛擬汽車
-
在 「選擇車輛外殼和感應器配置」頁面中,選擇與您的競賽類型和動作空間兼容的外殼。如果您的車庫中沒有相符的車輛,請前往主導覽窗格中「強化」學習標題下的「你的車庫」建立車庫。
對於時間試驗訓練,原始版的預設感測器配置和單鏡頭攝影機 DeepRacer是您所需要的,但只要動作空間相符,所有其他的砲彈和傳感器配置都可以正常工作。如需詳細資訊,請參閱為時間試用量身打造 AWS DeepRacer 培訓。
對於避免物體訓練,立體攝像機很有幫助,但也可以使用單個攝像頭來避免固定位置的固定障礙物。LiDAR 傳感器是可選的。請參閱 AWS DeepRacer 動作空間和獎勵功能。
對於 Head-to-bot 訓練,除了單個攝像頭或立體攝像機外,LiDAR 單元還是最佳選擇,用於在通過其他移動車輛時檢測和避免盲點。如需進一步了解,請參閱 為 head-to-bot 比賽量身打造 AWS DeepRacer 培訓。
-
選擇 下一步。
自訂您的獎勵功能
獎勵功能是強化學習的核心。學習如何使用它來激勵您的汽車(代理)在探索軌道(環境)時採取特定行動。就像鼓勵和阻止寵物的某些行為一樣,您可以使用此工具來鼓勵您的汽車盡快完成一圈,並阻止它離開賽道或與物體碰撞。
自訂您的獎勵功能
-
在 Create model (建立模型) 頁面上,於 Reward function (獎勵函數) 下方,為您的模型直接使用預設獎勵函數範例。
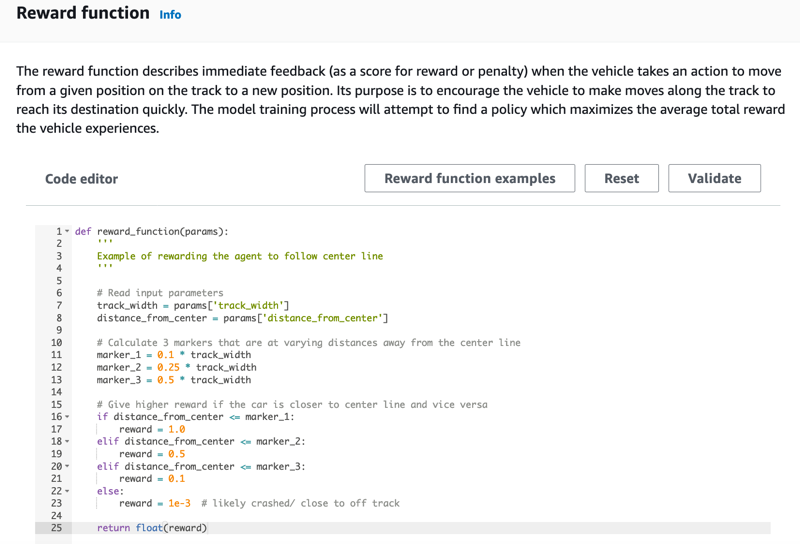
稍後,您可以選擇 Reward function examples (獎勵函數範例) 來選取其他範例函數,然後選擇 Use code (使用程式碼) 來接受選取的獎勵函數。
有四個示例函數,您可以啟動。他們說明瞭如何跟隨軌道中心(默認),如何將代理保持在軌道邊界內,如何防止鋸齒形行駛,以及如何避免撞到固定的障礙物或其他移動的車輛。
若要進一步了解獎勵函數,請參閱 AWS DeepRacer 獎勵函數參考。
-
在停止條件下,保留預設的最大時間值,或設定新值以終止訓練工作,以協助防止長時間執行 (和可能失控) 的訓練工作。
在訓練的早期階段進行實驗時,建議您針對此參數從較小的值開始,然後逐步訓練更長的時間。
-
在「自動提交至 AWS」下 DeepRacer,依預設會勾選訓練完成後 DeepRacer 自動將此模型提交至 AWS,並有機會贏得獎品。或者,您可以選取核取標記來選擇不輸入模型。
-
在「聯盟要求」下,選取您的居住國家/地區,並勾選方塊以接受條款與條件。
-
選擇建立模型以開始建立模型並佈建訓練工作執行處理。
-
在提交後,查看您的培訓任務初始化並接著開始執行。
初始化程序需要幾分鐘的時間才能從 [初始化] 變更為 [進行中]。
-
觀看 Reward graph (獎勵圖表) 和 Simulation video stream (模擬視訊串流),以觀察訓練任務的進度。您可以定期選擇 Reward graph (獎勵圖表) 旁邊的重新整理按鈕來重新整理 Reward graph (獎勵圖表),直到訓練任務完成為止。
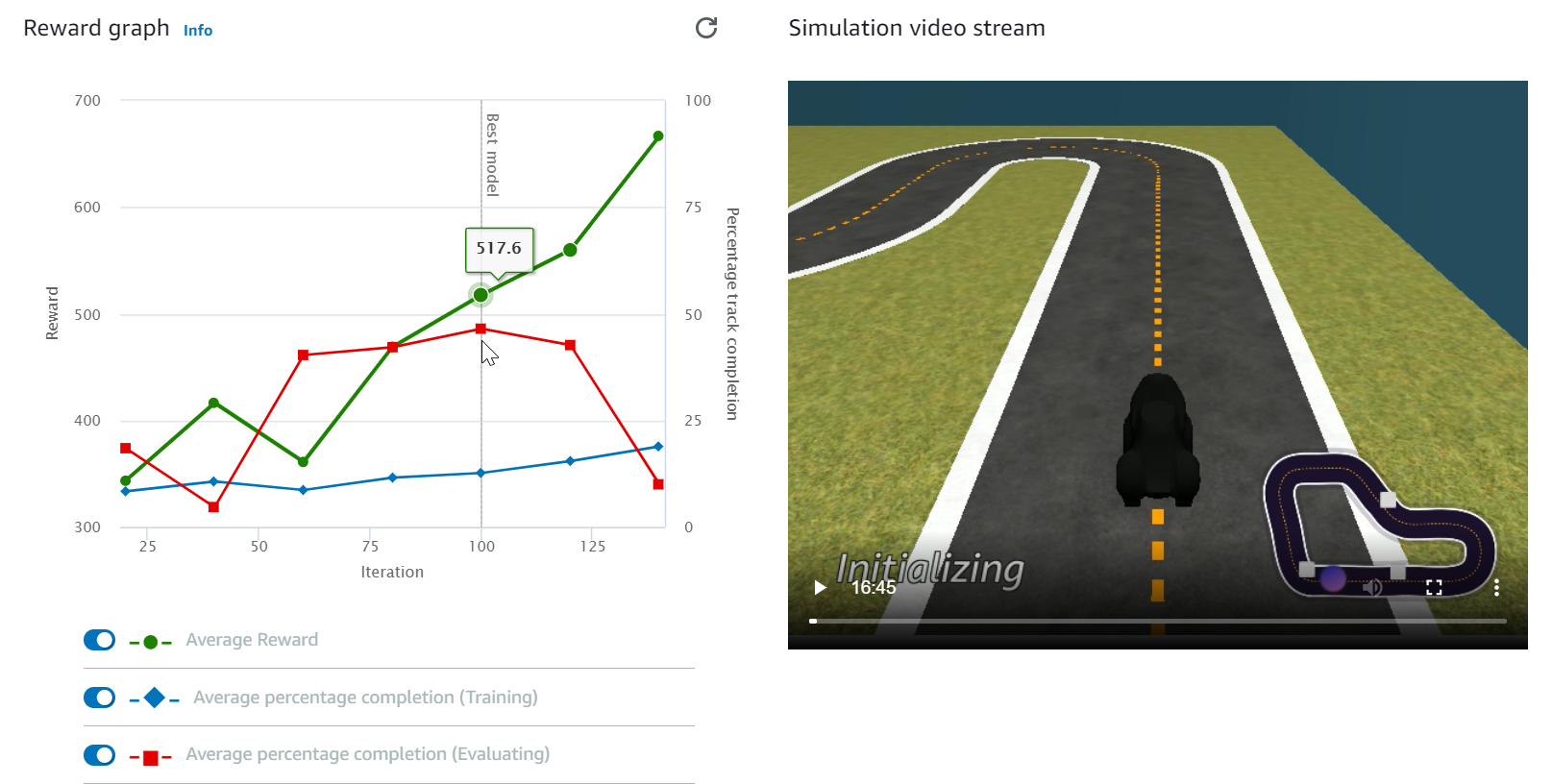
訓練任務會在AWS雲端執行,因此您不需要讓 AWS DeepRacer 主控台保持開啟狀態。在工作進行中時,您隨時都可以返回主控台以檢查您的模型。
如果模擬視頻流窗口或獎勵圖表顯示沒有響應,請刷新瀏覽器頁面以更新培訓進度。
