本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 AWS 主控台訓練和評估 DeepRacer AWS DeepRacer 模型
若要訓練強化學習模型,您可以使用 AWS DeepRacer 主控台。在主控台中,建立訓練工作、選擇支援的架構和可用的演算法、新增獎勵函數,並設定訓練設定。您也可以在模擬器中觀賞繼續的訓練。您可以在中找到step-by-step指示訓練您的第一個 AWS DeepRacer 模型 。
本節說明如何訓練和評估 AWS DeepRacer 模型。它還會示範如何建立和改善獎勵函數、動作空間如何影響模型效能,以及超參數如何影響訓練效能。您也可以了解如何複製訓練模型以延長訓練工作階段、如何使用模擬器評估訓練效能,以及如何解決一些將模擬搬到真實世界的挑戰。
主題
創建您的獎勵功能
獎勵功能描述 AWS DeepRacer 車輛從賽道上的某個位置移動到新位置時的即時反饋 (作為獎勵或罰分)。此函數旨在鼓勵車輛沿著賽道移動快速抵達目的地,不發生意外或違規。令人滿意的移動會為動作或其目標狀態獲得較高分數。非法或無效的移動會獲得較低的分數。培訓 AWS DeepRacer 模型時,獎勵功能是唯一特定於應用程式的部分。
一般而言,您設計的獎勵函數就像獎勵計劃。不同的獎勵策略會導致不同的車輛行為。為讓車輛跑得更快,函數應獎勵沿著賽道跑的車輛。當車輛跑完一圈花費太長時間或出軌時,函數應該給予處罰。為避免之字形駕駛模式,它可以獎勵在賽道較直部分轉向較少的車輛。當車輛通過某些里程碑時,獎勵函數可能會給予正分,如 waypoints 所測量。這可以減少等待或駛向錯誤方向。您也可能會變更獎勵函數,為賽道條件負責。不過,您獎勵函數考慮的環境特定資訊愈多,您經過訓練的模型愈可能過度擬合且較不一般。為了讓您的模型更適用於一般情況,您可以探索動作空間。
如不謹慎考量獎勵計劃,可能會導致相反效果的意外後果
建立獎勵函數的良好實務是從涵蓋基本案例的簡單函數開始。您可以增強函數以處理更多動作。現在讓我們來看看一些簡單的獎勵函數。
簡單的獎勵功能實例
我們可以先考慮最基本的情況,開始建立獎勵函數。此情況是在直道賽道上駕駛,從開始到結束都不出軌。在這種情況下,獎勵函數邏輯僅取決於 on_track 和 progress。您可以先從下列邏輯開始測試:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else if params["progress"] == 1 : reward = 10 return reward
此邏輯會在它自行駕駛出軌時處罰代理。當它駛至終點線時獎勵代理。其能夠合理地實現指定目標。不過,代理可以自由在起點和終點線之間四處遊蕩,包括在賽道上逆向行駛。訓練不僅可能需要很長的時間才能完成,經過訓練的模型還可能在部署到真實世界車輛後,導致駕駛效率不彰。
在實踐中,代理是否可以在bit-by-bit整個培訓過程中這樣做,會更有效地學習。這表示獎勵函數應該隨著軌道上的進度,給予較小的逐步獎勵。若要讓代理程式在直線軌道上行駛,我們可以改善獎勵函數,如下所示:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else: reward = params["progress"] return reward
使用此函數,代理程式越接近終點線就會取得更多獎勵。這應該會減少或消除逆向行駛這種沒有建設性的嘗試。一般而言,我們希望獎勵函數能夠更均勻地分配給動作空間。建立有效的獎勵函數可能會是艱鉅的挑戰。您應該先從簡單的函數開始,再逐步增強或改善。使用系統化的試驗,函數可以變得更強大且更有效率。
提升您的獎勵功能
成功訓練 AWS DeepRacer 模型以進行簡單直線通道之後,AWS DeepRacer 車輛 (虛擬或實體) 就可以自行駕駛,而無需離開軌道。如果您讓車輛在環狀軌道上行駛,就會脫軌。獎勵函數忽略了轉彎以保持在軌道上的動作。
為了讓您的車輛處理這些動作,您必須增強獎勵函數。當代理建立允許的轉向時,函數會給予獎勵,如果代理建立非法的轉向時會產生處罰。然後,您就準備好開始另一輪的訓練。若要善用先前的訓練,您可以複製先前經過訓練之模型開始新的訓練,將先前學到的知識傳承下去。您可以按照此模式逐步向獎勵功能新增更多功能,以訓練 AWS DeepRacer 車輛在日益複雜的環境中駕駛。
如需更多進階獎勵函數,請參閱下列範例:
探索動作空間以訓練強大的模型
一般規則是盡可能訓練強大的模型,以便套用到盡可能多的環境。強大的模型是可套用到各種形態和條件賽道的模型。一般而言,穩固的模型不「聰明」,因為它的獎勵函數不能包含明確的環境特定知識。否則,您的模型可能僅適用於類似經過訓練的環境。
將環境特定資訊明確併入特色工程的獎勵函數數量。功能工程有助於降低訓練時間,對特定的環境量身打造的解決方案非常有用。但若要訓練一般適用性的模型,您應該避免嘗試大量的特色工程。
例如,在環形賽道上訓練模型時,如果您在獎勵函數中明確納入這類的幾何屬性,您無法預期取得適用於任何非環形賽道之經過訓練的模型。
您要如何盡可能訓練強大的模型,同時盡可能保持獎勵函數簡單? 其中一個方法是探索在您代理可採取動作的動作空間範圍。另一個方法是實驗基本訓練演算法的超參數。您通常會兩種都執行。在這裡,我們專注於如何探索動作空間,為您的 AWS DeepRacer 車輛訓練強大的模型。
在訓練 AWS DeepRacer 模型時,action (a) 是速度 (t公尺/秒) 和轉向角度 (以度為單s位) 的組合。代理的動作空間會定義代理可接受的速度和轉向角度範圍。在有 m 種速度 ((v1, .., vn)) 和 n 種轉向角度 ((s1, ..,
sm)) 的分散動作空間,動作空間中可能有 m*n 個動作:
a1: (v1, s1) ... an: (v1, sn) ... a(i-1)*n+j: (vi, sj) ... a(m-1)*n+1: (vm, s1) ... am*n: (vm, sn)
(vi,
sj) 的實際值取決於 vmax 和 |smax| 的範圍,且為不規則分佈。
每次開始訓練或迭代 AWS DeepRacer 模型時,都必須先指定nm、vmax和|smax|或同意使用其預設值。AWS DeepRacer 服務會根據您的選擇產生您的代理程式可以在訓練中選擇的可用動作。產生的動作不規則分佈在動作空間。
一般而言,動作數量和動作範圍較大,您的代理就有較多的空間或選項反應更多變的賽道條件,例如轉彎角度或方向不規則的彎道賽道。代理可用的選項愈多,處理賽道變化的準備就愈充分。因此,即使使用簡單的獎勵函數,您也可以預期經過訓練的模型有更廣泛的適用性。
例如,您的代理可使用速度和轉向角度不多的粗略分級動作空間,快速學習直道賽道。在有彎道的賽道上,此粗略分級的動作容間可能會造成代理在轉彎時過衝及出軌。這是因為它能動用的選項不足,無法調整其速度或轉向。增加速度或轉向角度的數量,或兩者都增加,代理應該更能夠處理彎道,同時保持不出軌。同樣地,如果您的代理以之字形方式移動,您可以嘗試增加轉向範圍,降低任何指定步驟的劇烈轉彎。
當動作空間太大時,訓練效能可能會受挫,因為它要花較長的時間探索動作空間。請務必平衡模型的一般適用性優點及其訓練效能需求。此最佳化涉及系統化實驗。
系統地調整超參數
其中一種方法,是施行更佳或更有效率的訓練程序,以改善模型的效能。例如,為取得強大的模型,訓練必須向代理提供更多或更少的代理動作空間平均分散取樣。這需要混合足夠的探索和開發。影響此項目的變數包括使用的訓練資料量 (number of episodes between each
training 和 batch size)、代理的學習速度 (learning rate)、探索的部分 (entropy)。為了讓訓練更實際,您可能想要加快學習程序。影響此項目的變數包括 learning rate、batch size、number of
epochs 和 discount factor。
影響訓練程序的這些變數稱為訓練的超參數。這些演算法屬性不是基礎模型的屬性。不幸的是,超參數在本質上為經驗性。它們的最佳值不出自所有實際用途,而是需要衍生自系統化試驗。
在討論可調整以調整 AWS DeepRacer 模型訓練效能的超參數之前,讓我們定義下列術語。
- 資料點
-
資料點,也稱為「體驗」,是 (s,a,r,s’) 的元組,其中 s 代表攝影機擷取的觀察 (或狀態)、a 代表車輛採取的動作、r 代表前述動作產生的預期獎勵,而 s' 代表採取動作後的新觀察。
- 回合
-
回合是一段期間,在此期間車輛從指定的起點開始,結束於跑完賽道或出軌。它包含一系列的體驗。不同的回合可以有不同的長度。
- 體驗緩衝
-
體驗緩衝包含許多在訓練期間,收集自固定回合數量但長度各異的排序資料點。對於 AWSDeepRacer,它對應於安裝在 AWS DeepRacer 車輛上的攝影機擷取的影像,以及車輛採取的動作,並做為更新基礎 (政策和價值) 神經網路的輸入來源。
- 批次
-
批次處理是體驗的排序清單,代表一段期間的部分模擬,用來更新政策網路權數。這是體驗緩衝的一部分。
- 訓練資料
-
訓練資料是從體驗緩衝隨機採樣的批次集,用於訓練政策網路權數。
| 超參數 | 描述 |
|---|---|
|
梯度下降批次大小 |
最近車輛體驗隨機採樣的數量,取自體驗緩衝,用於更新基礎深度學習類神經網路權數。隨機取樣有助於降低輸入資料固有的關聯性。使用較大的批次大小,能為類神經網路權數提升更穩定和更順暢的更新,但請記住,訓練可能會變得較久或較慢。
|
|
Number of epochs (epoch 數目) |
在梯度下降期間更新類神經網路權數的訓練資料傳遞數。對應體驗緩衝中隨機樣本的訓練資料。使用較多數量的 epoch 提升更穩定的更新,但預期訓練速度會較慢。當批次大小很小時,您可以使用的 epoch 數量也較少
|
|
Learning rate (學習率) |
在每次更新期間,一部分的新權數會出自梯度下降 (或上升) 投入,其餘則來自現有的權數值。學習率控制梯度下降 (或上升) 對網路權數更新投入的程度。使用較高的學習率以包含更多梯度下降投入,可獲得更快的訓練,但請注意,如果學習率過大,預期的獎勵可能不會集中。
|
Entropy |
決定何時將隨機性新增至政策分佈的不確定性程度。增加的不確定性有助於 AWS DeepRacer 車輛更廣泛地探索行動空間。較大的熵值鼓勵車輛更徹底地探索動作空間。
|
| Discount factor (折扣因素) |
係數會指定未來獎勵對預期獎勵的投入程度。Discount factor (折扣係數) 值愈大,車輛考慮移動的投入就愈遠,訓練速度就愈較慢。折扣係數為 0.9 時,車輛移動會包含前進 10 步為獎勵的規律。折扣係數為 0.999 時,車輛移動會考慮前進 1000 步的獎勵。建議的折扣係數值為 0.99、0.999 和 0.9999。
|
| 損失類型 |
目標函數的類型可用來更新網路權重。良好的訓練演算法應能對代理程式的策略進行增量變更,使其從採取隨機動作逐步轉換為採取策略動作以提高獎勵。但是,如果其變更規模太大則會造成訓練不穩定,而代理程式最後什麼都沒學到。Huber loss (Huber 遺失)
|
| 每個重複政策更新之間的體驗回合數 | 針對學習政策網路權數提取訓練資料所用的體驗緩衝大小。體驗回合是一段期間,在此期間代理從指定的起點開始,結束於跑完賽道或出軌。它包含一系列的體驗。不同的回合可以有不同的長度。對於簡單的強化學習問題,小型的體驗緩衝可能就足夠,學習很快。至於有較多區域最大值的更複雜問題,就需要有較大的體驗緩衝提供更多的不相關資料點。在這種情況下,訓練速度較慢,但較穩定。建議值為 10、20 和 40。
|
檢查 AWS DeepRacer 培訓任務進度
開始訓練工作之後,您可以檢查獎勵的訓練指標和每個回合的軌道完成情況,以確定模型訓練工作的效能。在 AWS DeepRacer 主控台上,指標會顯示在獎勵圖表中,如下圖所示。
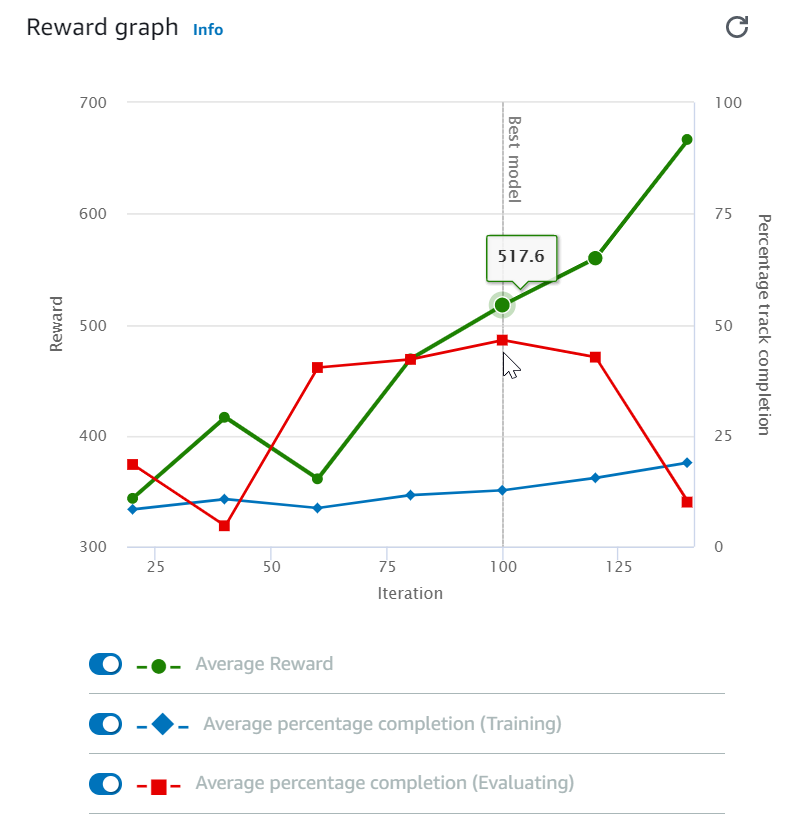
您可以選擇檢視每個回合獲得的獎勵、每個反覆項目的平均獎勵、每個回合的進度、每個反覆項目的平均進度或其任意組合。若要這麼做,請切換獎勵圖表底部的「獎勵」(劇集、平均)或「進度」(劇集、平均)切換開關。每個回合的獎勵和進度會以不同顏色顯示為散佈圖。平均獎勵和軌道完成會以折線圖顯示,並在第一次反覆運算之後開始。
獎勵範圍顯示在圖表的左側,且進度範圍 (0-100) 位於右側。若要讀取訓練指標的確切值,請將滑鼠移至圖形上的資料點附近。
訓練進行時,圖表會每 10 秒會自動更新一次。您可以選擇重新整理按鈕來手動更新指標顯示畫面。
如果平均獎勵和軌道完成顯示趨向收斂的趨勢,則訓練工作良好。尤其是,如果每個回合的進度持續達到 100% 且獎勵達到平穩,模型就有可能收斂。如果沒有,請複製模型並重新訓練。
複製訓練過的模型以開始新的訓練通行證
如果您複製之前經過訓練的模型,做為新一輪訓練的起點,有可能提升訓練效率。若要執行此作業,請修改超參數使用已經學會的知識。
在本節中,您將學習如何使用 AWS DeepRacer 主控台複製經過訓練的模型。
使用 AWS DeepRacer 主控台重複訓練強化學習模型
-
如果尚未登入,請登入 AWS DeepRacer 主控台。
-
在「模型」頁面上,選擇訓練過的模型,然後從「動作」下拉式功能表清單中選擇「複製」。
-
對於 Model details (模型詳細資訊),請執行下列動作:
-
如果您不想為克隆的模型
RL_model_1生成名稱,請鍵入模型名稱。 -
或者,在模型描述中提供to-be-cloned模型的描述-可選。
-
-
對於環境模擬,請選擇另一個追蹤選項。
-
針對 Reward function (獎勵函數),選擇其中一個可用的獎勵函數範例。修改獎勵函數。例如,考慮轉向。
-
展開 Algorithm settings (演算法設定) 嘗試不同的選項。例如,將 Gradient descent batch size (梯度下降批次大小) 值從 32 變更到 64,或增加 Learning rate (學習率) 加速訓練。
-
實驗不同 Stop conditions (停止條件) 的選項。
-
選擇 Start training (開始訓練) 開始新一輪的訓練。
如同訓練可靠的機器學習模型,進行系統化實驗以取得最佳解決方案非常重要。
在模擬中評估 AWS DeepRacer 模型
評估模型就是測試已訓練模型的效能。在 AWS 中DeepRacer,標準效能指標是完成連續三圈的平均時間。使用此指標,對於任何兩個模型,如果一個模型可以使代理在同一軌道上更快地運行,則一個模型優於另一個模型。
一般而言,評估模型涉及以下任務:
-
設定並開始評估工作。
-
在執行工作的同時觀察正在進行的評估。這可以在 AWS DeepRacer 模擬器中完成。
-
在評估工作完成之後檢查評估摘要。您可以隨時終止評估工作。
注意
評估時間取決於您選取的條件。如果您的模型不符合評估標準,評估將繼續執行,直到達到 20 分鐘上限為止。
-
選擇性地將評估結果提交給合格的 AWS DeepRacer 排行榜。排行榜的排名可讓您了解您的模型相對於其他參與者的表現如何。
在實體軌道上使用 AWS DeepRacer 車輛駕駛來測試 AWS DeepRacer 模型,請參閱操作您的 AWS DeepRacer 車輛 。
針對真實環境優化 AWS DeepRacer 模型培訓
許多因素會影響經過訓練的模型在真實世界的效能,包括選擇的動作空間、獎勵函數、用於訓練的超參數和車輛校正,以及真實世界賽道條件。此外,模擬僅為近似 (通常粗略) 的真實世界。它們讓將模擬訓練的模型套用到真實世界,並達到滿意的效能,成為一項挑戰。
訓練模型以提供穩固的真實世界效能,通常需要在模擬中無數次反覆探索獎勵函數、動作空間、超參數和評估,以及在實際環境中測試。最後一步涉及所謂的simulation-to-real世界(sim2real)轉移,並且會感到笨拙。
為助於處理 sim2real 挑戰,請注意以下事項:
-
確保車輛經過完善校正。
這很重要,因為模擬的環境很可能呈現部分的實際環境。此外,代理在每個步驟會根據自攝影機影像擷取之目前的賽道條件採取動作。它看不到足夠遠,無法快速計劃路線。為包含此項目,模擬會強制執行速度和轉向的限制。為確保經過訓練的模型能在真實世界運作,車輛必須正確校正,以符合這項及其他模擬設定。如需校正車輛的詳細資訊,請參閱 校準您的 AWS DeepRacer 車輛。
-
先使用預設的模型測試您的車輛。
您的 AWS DeepRacer 車輛隨附預先訓練的模型,載入其推論引擎。在真實世界測試您自己的模型之前,請先驗證車輛能以預設模型合理執行作業。如果不能,請檢查實體賽道設定。在不正確建立的實體賽道中測試模型,可能會導致很差勁的效能。在這種情況下,請先重新設定或修復您的賽道,再開始或繼續測試。
注意
執行 AWS DeepRacer 車輛時,會根據訓練有素的政策網路推斷動作,而不需要呼叫獎勵功能。
-
請確認模型能在模擬中運作。
如果您的模型在真實世界不能運作,可能是模型或賽道有瑕疵。若要排查根本原因,您應該先評估模擬中的模型,檢查是否有模擬代理可完成至少一圈不出軌。您可以透過檢查獎勵的收歛,同時觀察代理在模擬器中的軌跡,完成此作業。如果模擬代理完成一圈不搖晃時,獎勵達到最大,則模型可能是良好的。
-
請勿過度訓練模型。
在模型堅持完成模擬賽道後繼續訓練,會造成模型過度擬合。過度訓練的模型在真實世界的表現不是很好,因為它甚至無法處理模擬賽道和實際環境間的微小差異。
-
使用來自不同反覆運算的多個模型。
一般的訓練工作階段會產生介於擬合不足和過度擬合的模型範圍。因為沒有最優先的條件可決定對的模型,所以您應該從代理在模擬器中完成一圈的時間到它能持續跑圈的點中,挑選幾個候選模型。
-
起步緩慢,在測試中逐漸提速。
當測試部署在您車輛的模型時,開始請使用小的最大速度值。例如,您可以將測試速度限制設為 <10% 的訓練速度限制。然後逐漸提高測試速度限制,直到車輛開始移動。您使用裝置控制主控台設定校正車輛時的測試速度限制。如果車輛變得太快,例如,如果速度超過在模擬器中訓練過程中看到的速度,則該模型不可能在真實賽道上表現良好。
-
用您的車輛在不同的開始位置測試模型。
模型在模擬中學習採用特定的路徑,而且對它在賽道內的位置很敏感。您應該在賽道界限內的不同位置 (從左側到中心再到右側) 開始車輛測試,看看模型在某些位置是否表現良好。大多數的模型都傾向讓車輛盡量保持靠近白線的某一邊。為協助分析車輛的路徑,請在真實環境中,從模擬到識別車輛可能採行的路徑,逐步標繪車輛的位置 (x, y)。
-
開始測試直道賽道。
與有彎道的賽道相比,直道賽道更容易引導。從直道賽道開始測試,有利於快速淘汰不良模型。如果車輛大多數時間無法在直道賽道上行駛,則模型在有彎道的賽道上也無法有良好的表現。
-
注意車輛只採用一種動作的行為,
當您的車輛只能採取一種類型的動作時,例如僅將車輛轉向左側時,該模型可能是過度裝配或裝配不足。使用指定的模型參數,在訓練中過多反覆運算可能會讓模型變得過度擬合。反覆運算太少會讓模型變得擬合不足。
-
注意車輛能沿著賽道邊緣修正路徑的能力。
一個好的模型能讓車輛在接近賽道邊緣時自行修正。大多數訓練良好的模型都擁有這項功能。如果車輛能在賽道兩側邊緣自行修正,則模型會被視為更強大和具有更高品質。
-
注意車輛表現出的不一致行為。
政策模型代表在指定狀態下採取動作的機率分佈。將經過訓練的模型載入其推論引擎,車輛會根據模型的指示,一次一步驟地挑選最可能的動作。如果動作機率平均分佈,則車輛可以採取有相同或近似機率的任何動作。這會導致不規律的行為。例如,當車輛有時沿著直線路徑(例如,一半的時間)並在其他時間進行不必要的轉彎時,該模型的裝配不足或過裝。
-
注意車輛僅進行的一種轉彎(左或右)。
如果車輛能處理左轉但無法掌握右轉,或者車輛只能掌握右轉卻無法處理左轉,您需要仔細校正或重新校正您的車輛轉向。或者,您也可以嘗試使用以接近測試時實體設定之設定訓練的模型。
-
注意車輛突然轉彎和離開軌道。
如果車輛在大部分的行程中都正確行駛,但突然轉向出軌,可能是受到環境干擾。大部分的常見干擾包括無預期或意外的反光。在這種情況下,請使用護欄圍住賽道或其他手段,降低炫光。
