本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
減少規劃開銷
正如 Apache 星火中所討論的關鍵主題,星火驅動程序生成執行計劃。根據該計劃,任務被分配給 Spark 執行程序進行分佈式處理。不過,如果有大量的小檔案,或者如果 AWS Glue Data Catalog 包含大量的磁碟分割,Spark 驅動程式可能會成為瓶頸。若要識別高規劃額外負荷,請評估下列指標。
CloudWatch 度量
檢查下列情況的「CPU負載」和「記憶體使用率」:
-
火花驅動器CPU負載和內存利用率記錄為高。通常,Spark 驅動程序不會處理您的數據,因此CPU負載和內存利用率不會激增。但是,如果 Amazon S3 資料來源有太多小檔案,列出所有 S3 物件和管理大量任務可能會導致資源使用率很高。
-
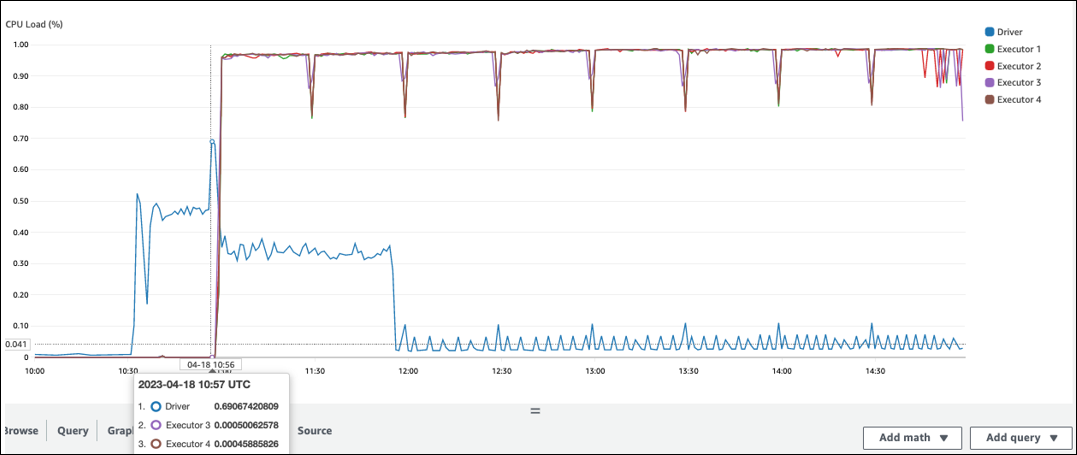
在 Spark 執行程序處理開始之前有一個很長的差距。在下面的示例屏幕截圖中,Spark 執行程序的CPU負載太低,直到 10:57,即使 AWS Glue 工作在 10:00 開始。這表明 Spark 驅動程序可能需要很長時間才能生成執行計劃。在此範例中,擷取資料目錄中的大量分割區,並在 Spark 驅動程式中列出大量的小檔案需要很長時間。
Spark UI
在 Spark UI 的 [Job] 索引標籤上,您可以看到提交的時間。在下列範例中,Spark 驅動程式會在 10:56:46 啟動工作,即使工作是在 10:00:00 開始。 AWS Glue

您也可以在「Job」標籤上看到「工作」(針對所有階段):成功/總時間。在這種情況下,任務的數量被記錄為58100。如同平行化任務頁面的 Amazon S3 一節所述,任務數量大致對應於 S3 物件的數目。這意味著 Amazon S3 中有大約 58,100 個對象。
如需有關此工作和時間表的詳細資訊,請檢閱階段索引標籤。如果您發現 Spark 驅動程式出現瓶頸,請考慮下列解決方案:
-
當 Amazon S3 有太多檔案時,請考慮「並行化任務」頁面的「分割太多」區段中有關過度平行處理的指導。
-
當 Amazon S3 有太多的分割區時,請在「減少資料掃描量」頁面的 Amazon S3 分割區過多一節中考慮有關過度分割的指導。如果有許多分割區,請啟用AWS Glue 分割區索引,以減少從「資料目錄」擷取分割區中繼資料的延遲。如需詳細資訊,請參閱使用資料 AWS Glue 分割索引改善查詢效能
。 -
如果JDBC分割區太多,請降低該
hashpartition值。 -
當 DynamoDB 有太多分割區時,請降低該
dynamodb.splits值。 -
當串流工作有太多的分割區時,請降低碎片數目。
