本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 Amazon SageMaker AI 的機器學習概觀
本節說明典型的機器學習 (ML) 工作流程,並說明如何使用 Amazon SageMaker AI 完成這些任務。
在機器學習中,您會教導電腦進行預測或推論。首先,請使用演算法和範例資料來訓練模型。然後,您將模型整合到您的應用程式中,以即時和大規模地產生推論。
下圖顯示建立 ML 模型的典型工作流程。它包含循環流程中的三個階段,我們會更詳細地進行圖表:
-
產生範例資料
-
訓練模型
-
部署模型
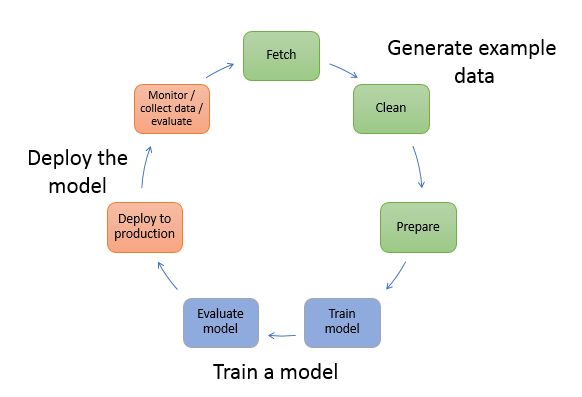
圖表顯示如何在大多數典型案例中執行下列任務:
-
產生範例資料 – 若要訓練模型,您需要範例資料。您需要的資料類型取決於您希望模型解決的業務問題。這與您希望模型產生的推論相關。例如,如果您想要建立從手寫數字的輸入影像預測數字的模型。若要訓練此模型,您需要手寫數字的範例影像。
資料科學家通常會花時間探索和預先處理範例資料,然後再將其用於模型訓練。如需預處理資料,通常需要執行以下作業:
-
擷取資料 – 您可能有內部範例資料儲存庫,或者您可能使用可公開取得的資料集。一般而言,您會將資料集提取至單一儲存庫。
-
清除資料 – 為了改善模型訓練,請視需要檢查資料並進行清除。例如,如果您的資料具有具有值
United States和 的country name屬性US,您可以編輯資料以保持一致。 -
準備或轉換資料 – 為了改善效能,您可以執行額外的資料轉換。例如,您可以選擇合併模型的屬性,以預測需要將飛機除冰的條件。您可以將這些屬性合併為新的屬性,以獲得更好的模型,而不是分別使用溫度和濕度屬性。
在 SageMaker AI 中,您可以在整合開發環境 (IDE) 中使用 SageMaker APIs搭配 SageMaker Python SDK
預先處理範例資料。使用適用於 Python 的 SDK (Boto3),您可以擷取、探索和準備資料以進行模型訓練。如需有關資料準備、處理和轉換資料的資訊,請參閱 在 SageMaker AI 中選擇正確資料準備工具的建議、 使用 SageMaker Processing 的資料轉換工作負載和 使用 Feature Store 建立、存放和共用功能。 -
-
訓練模型 – 模型訓練包括訓練和評估模型,如下所示:
-
訓練模型 – 若要訓練模型,您需要演算法或預先訓練的基礎模型。您所選的演算法會視多種因素而定。對於內建解決方案,您可以使用 SageMaker 提供的其中一個演算法。如需 SageMaker 提供的演算法清單以及相關考量事項,請參閱Amazon SageMaker 中的內建演算法和預先訓練的模型。如需提供演算法和模型的基於使用者介面的訓練解決方案,請參閱SageMaker JumpStart 預先訓練的模型。
您亦需擁有適用於訓練的運算資源。您的資源使用取決於訓練資料集的大小,以及您需要結果的速度。您可以使用從單一一般用途執行個體到 GPU 執行個體分散式叢集的各種資源。如需詳細資訊,請參閱使用 Amazon SageMaker 訓練模型。
-
評估模型 – 訓練模型後,您會評估模型,以判斷推論的準確性是否可接受。若要訓練和評估模型,請使用 SageMaker Python SDK
,透過其中一個可用的 IDEs 將請求傳送至模型以進行推論。如需評估模型的詳細資訊,請參閱使用 Amazon SageMaker Model Monitor 進行資料和模型品質監控。
-
-
部署模型 – 您傳統上在將模型與應用程式整合並部署模型之前,會將其重新設計。使用 SageMaker AI 託管服務,您可以獨立部署模型,將其與應用程式程式碼分離。如需詳細資訊,請參閱部署用於推論的模型。
機器學習屬於連續循環作業。部署模型後,您可以監控推論、收集更高品質的資料,以及評估模型以識別偏離。然後,您可以更新訓練資料以包含新收集的高品質資料,藉此提高推論的準確性。隨著更多範例資料可供使用,您可以繼續重新訓練模型以提高準確性。
