本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
搭配 Amazon SageMaker AI 使用強化學習
強化學習 (RL) 結合電腦科學、神經科學和心理學等領域,以釐清如何將各種情況映射到相關動作,藉此最大化數值獎勵訊號。RL 中獎勵訊號的這種概念源於神經科學研究,探究人類大腦如何決定哪些動作可最大化獎勵並最小化懲罰。在大多數情況下,人類並無明確指示該採取哪些動作,而是必須了解哪些動作會產生最立即的獎勵,以及這些動作如何影響未來的情況和後果。
RL 的問題使用源於動態系統理論的馬可夫決策過程 (MDP) 來公式化。MDP 旨在擷取學習代理程式在嘗試實現一些最終目標時,於一段時間內所遇到的真實問題之高層次細節。學習代理程式應能夠判斷自身環境的目前狀態,並識別會影響學習代理程式目前狀態的可能動作。此外,學習代理程式的目標應與環境的狀態有極大的相互關聯。以這種方式公式化的問題之解決方案稱為:強化學習方法。
強化、監督式和非監督式學習範例之間有何區別?
機器學習可分為三種不同的學習範例:監督式、非監督式和強化。
在監督式學習中,外部主管提供一組標籤範例的訓練集。每個範例都包含狀況的相關資訊、屬於哪個類別,並具有識別其所屬類別的標籤。監督式學習的目標是推廣,以便出現訓練資料中不存在的情況時能正確預測。
相較之下,RL 處理的是互動問題,因此收集所有使用代理程式可能遇到的正確標籤的情況範例是不可行的。當代理程式能夠準確地從自身經驗中學習並相應地進行調整時,這種類型的學習會是最有前途的。
在非監督式學習中,代理程式會透過發現未標籤資料中的結構來學習。雖然 RL 代理程式可能會從基於其經驗的結構探索中受益,但 RL 的唯一目的是最大化獎勵訊號。
主題
為什麼強化學習很重要?
RL 非常適合解決大型複雜的問題,例如供應鏈管理、HVAC 系統、工業機器人、遊戲人工智慧、對話系統和自動駕駛汽車。由於 RL 模型是透過代理程式所採取動作的獎勵與懲罰連續程序來學習的,因此可以在不確定及動態的環境下訓練系統以進行決策。
馬可夫決策過程 (MDP)
RL 是以稱為馬可夫決策過程 (MDP) 的模型為基礎。MDP 由一系列的時間步驟組成。每個時間步驟都包含下列項目:
- Environment
-
定義 RL 模型運作的空間。這可以是真實世界環境或模擬器。例如,若您訓練一台實體道路上的實體自動車,該環境便是一個真實世界環境。若您訓練一個電腦程式,為在道路上行駛的自動車建立模型,該環境便是一個模擬器。
- State
-
指定與環境相關的所有資訊,以及與未來相關的過去步驟。例如,在機器人可以在任何時間步驟中往任何方向移動的 RL 模型中,目前時間步驟中機器人的位置便是狀態,因為我們知道機器人所在的位置,而無須了解機器人到達該位置所需採取的步驟。
- Action
-
代理程式的功能 例如,機器人可以向前一步。
- 獎勵
-
代表狀態值的數字,該狀態是代理程式所採取最近一個動作的結果。例如,若機器人的目標是尋找寶藏,則尋找寶藏的獎勵可以是 5,而沒有找到寶藏的獎勵則可以是 0。RL 模型會嘗試尋找一個策略,最佳化長期下來的累積獎勵。此策略稱為政策。
- 觀察
-
與環境狀態有關的資訊,可供代理程式在每個步驟時使用。這可以是整個狀態,或是狀態的一部分。例如,下西洋棋模型中的代理程式可能可以在任何步驟中觀察棋盤的整個狀態,但迷宮中的機器人則可能只能觀察到迷宮中其目前所處位置的那一小部分。
一般而言,在 RL 中進行訓練包含了許多集。每一集都包含 MDP 中所有的時間步驟,從初始狀態開始,直到環境到達最終狀態為止。
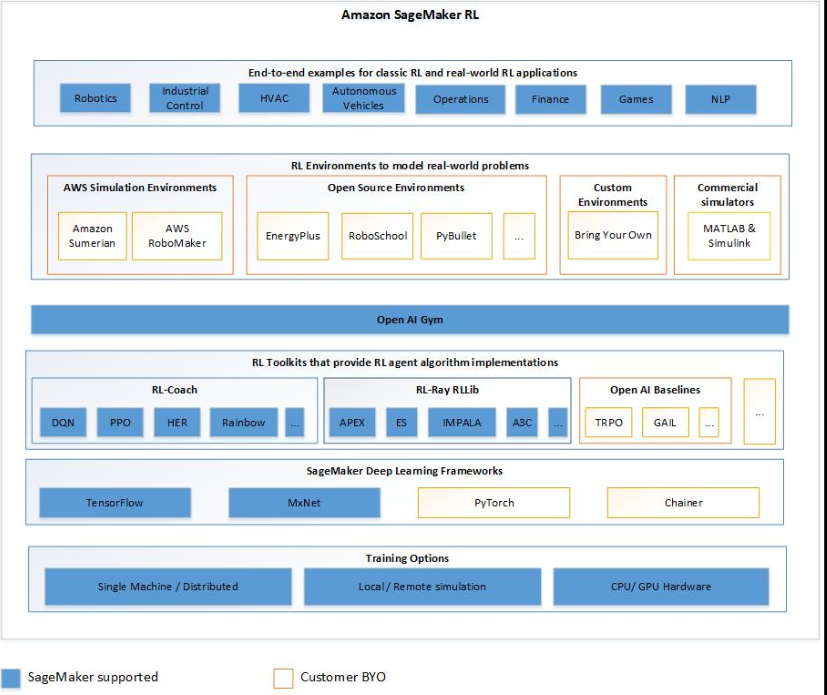
Amazon SageMaker AI RL 的主要功能
若要在 SageMaker AI RL 中訓練 RL 模型,請使用下列元件:
-
一個深度學習 (DL) 框架。目前,SageMaker AI 支援 TensorFlow 和 Apache MXNet 中的 RL。
-
RL 工具組。RL 工具組可管理代理程式和環境間的互動,並提供各種最先進的 RL 演算法。SageMaker AI 支援 Intel Coach 和 Ray RLlib 工具組。如需 Intel Coach 的資訊,請參閱 https://nervanasystems.github.io/coach/
。如需 Ray RLlib 的資訊,請參閱 https://ray.readthedocs.io/en/latest/rllib.html 。 -
RL 環境。您可以使用自訂環境、開放原始碼環境,或是商業環境。如需相關資訊,請參閱Amazon SageMaker AI 中的 RL 環境。
下圖顯示 SageMaker AI RL 中支援的 RL 元件。
強化學習範例筆記本
如需完整的程式碼範例,請參閱 SageMaker AI 範例儲存庫中的強化學習範例筆記本
