本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon Kinesis Data Streams 術語和概念
開始使用 Amazon Kinesis Data Streams 之前,請先了解其架構和術語。
檢閱 Kinesis Data Streams 的高階架構
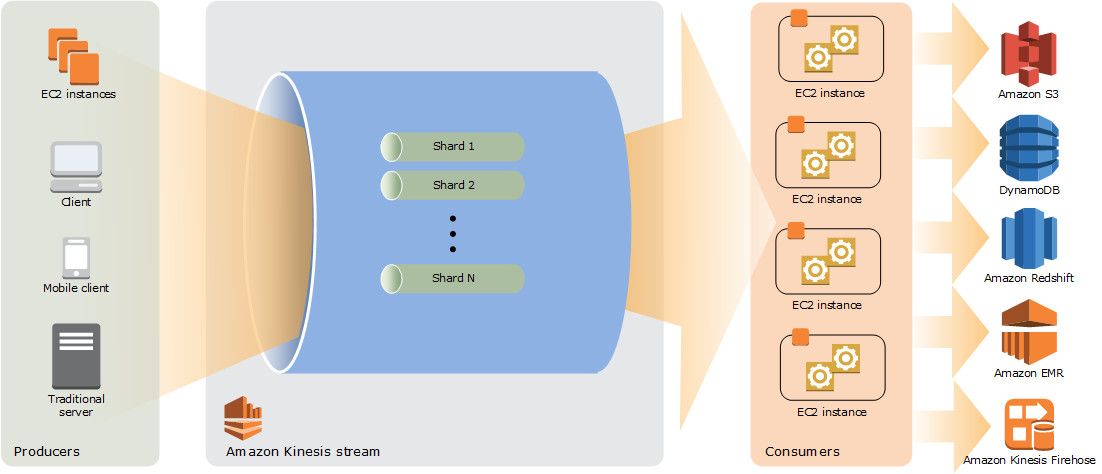
下圖說明 Kinesis Data Streams 的概要架構。生產者會持續推送資料至 Kinesis Data Streams,而取用者將即時處理資料。消費者 (例如在 Amazon EC2 或 Amazon Data Firehose 交付串流上執行的自訂應用程式) 可以使用 Amazon DynamoDB、Amazon Redshift 或 Amazon S3 等 AWS 服務來儲存其結果。
熟悉 Kinesis Data Streams 的術語
Kinesis Data Stream
Kinesis 資料串流是一組碎片。每個碎片都有一連串的資料記錄。每筆資料記錄具有由 Kinesis Data Streams 指派的序號。
資料記錄
Kinesis 資料串流存放資料的單位是資料記錄。資料記錄由序號、分割區索引鍵和資料 Blob (不可變的位元組序列) 所組成。Kinesis Data Streams 絲毫不會檢查、解譯或變更 Blob 中的資料。資料 Blob 最多可達 1 MB。
容量模式
資料串流容量模式會決定資料串流容量的管理方式,以及如何針對資料串流使用量收費。目前,在 Kinesis Data Streams 中,您可以選擇隨需模式和資料串流的佈建模式。如需詳細資訊,請參閱選擇要在 中串流的正確模式。
使用隨需模式時,Kinesis Data Streams 會自動管理碎片,以提供必要的輸送量。您只需為使用的實際輸送量付費,Kinesis Data Streams 會在工作負載增加或減少時自動滿足您的工作負載輸送量需求。如需詳細資訊,請參閱隨需標準模式功能和使用案例。
採用佈建模式,必須指定資料串流的碎片數目。資料串流的總容量是其碎片容量的總和。您可以依需要增加或減少資料串流中的碎片數目,並按小時費率向您收取碎片數目費用。如需詳細資訊,請參閱佈建模式功能和使用案例。
保留期間
保留期間是資料記錄加入至串流之後可供存取的時間長度。串流建立後,其保留期間將設為預設值 24 小時。您可以使用 IncreaseStreamRetentionPeriod 操作將保留期間增加到最長 8760 小時 (365 天),使用 DecreaseStreamRetentionPeriod 操作將保留期間減少到最短 24 小時。串流的保留期間若設為 24 小時以上,即需支付額外的費用。如需詳細資訊,請參閱 Amazon Kinesis Data Streams 定價
生產者
生產者將記錄放入 Amazon Kinesis Data Streams。例如,傳送日誌資料至串流的 web 伺服器即是生產者。
消費者
取用者會從 Amazon Kinesis Data Streams 取得記錄,並加以處理。這些消費者稱為 Amazon Kinesis Data Streams 應用程式。
Amazon Kinesis Data Streams 應用程式
Amazon Kinesis Data Streams 應用程式是通常在 EC2 執行個體機群上執行的串流取用者。
您可以開發的消費者有兩種:共用廣發功能消費者和強化廣發功能消費者。若要了解此兩者間的差異以及如何建立每一種消費者,請參閱從 Amazon Kinesis Data Streams 讀取資料。
Kinesis Data Streams 應用程式的輸出可以是另一串流的輸入,這使您能夠建立複雜的拓撲以便即時處理資料。應用程式也可以將資料傳送至各種 AWS 其他服務。單一串流可以有多個應用程式,每個應用程式均能同時各自從串流取用資料。
碎片
碎片是串流中的資料記錄的唯一識別序列。串流由一個或多個碎片所組成,每個碎片提供固定單位的容量。每個碎片最多可支援每秒 5 筆交易進行讀取,最大總資料讀取速率為每秒 2 MB,寫入時最多可支援每秒 1,000 筆記錄,最大總資料寫入速率為每秒 1 MB (包括分割區索引鍵)。串流的資料容量是您為該串流指定的碎片數目的函數。串流的總容量是其碎片容量的總和。
如果您的資料速率增加,您可以增加或減少配置給串流的碎片數目。如需詳細資訊,請參閱重新分片串流。
分割區索引鍵
分割區索引鍵用於依據串流中的碎片將資料分組。Kinesis Data Streams 會將屬於某一串流的資料記錄分隔到多個碎片中。本服務使用與每筆資料記錄相關聯的分割區索引鍵,判斷特定的資料記錄屬於哪個碎片。分割區索引鍵是 Unicode 字串,每個索引鍵的長度上限為 256 個字元。MD5 雜湊函數用於將分割區索引鍵對應到 128 位元整數值,並使用碎片的雜湊索引鍵範圍將相關聯的資料記錄對應到碎片。應用程式將資料放入串流時必須指定分割區索引鍵。
序號
每筆資料記錄在其碎片中的每個分割區索引鍵都有獨一無二的序號。Kinesis Data Streams 會在您使用 client.putRecords 或 client.putRecord 寫入串流之後指派序號。同一分割區索引鍵的序號通常會隨著時間而增加。逐次寫入請求的間隔期間愈長,序號將變得愈大。
注意
序號不能用做為同一串流中各資料集的索引。若要按照邏輯分隔資料集,請使用分割區索引鍵或為每個資料集建立個別串流。
Kinesis Client Library
Kinesis Client Library 會編譯至您的應用程式,以允許容錯使用來自串流的資料。Kinesis Client Library 會確保每個碎片都有記錄處理器正在執行並處理該碎片。本程式庫還可簡化從串流讀取資料的過程。Kinesis Client Library 使用 Amazon DynamoDB 資料表來存放與資料消耗相關的中繼資料。它為每個正在處理資料的應用程式建立三個資料表。如需詳細資訊,請參閱使用 Kinesis 用戶端程式庫。
Application Name (應用程式名稱)
Amazon Kinesis Data Streams 應用程式的名稱可識別該應用程式。您的每個應用程式都必須有一個唯一的名稱,範圍限定於應用程式所使用的 AWS 帳戶和區域。此名稱將做為 Amazon DynamoDB 中控制資料表的名稱以及 Amazon CloudWatch 指標的命名空間。
伺服器端加密
Amazon Kinesis Data Streams 可在生產者將機密資料輸入串流時自動為資料加密。Kinesis Data Streams 使用 AWS KMS 主金鑰進行加密。如需詳細資訊,請參閱Amazon Kinesis Data Streams 中的資料保護。
注意
若要讀取或寫入已加密的串流,生產者和消費者應用程式必須具備存取主金鑰的許可。如需如何對生產者和消費者應用程式授予許可的資訊,請參閱使用使用者產生之 KMS 金鑰的許可。
注意
使用伺服器端加密會產生 AWS Key Management Service (AWS KMS) 成本。如需更多資訊,請參閱 AWS Key Management Service 定價
