Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
AWS Lake Formation unterstützt die Erstellung von Apache Iceberg-Tabellen, die das Apache Parquet-Datenformat verwenden, AWS Glue Data Catalog wobei sich die Daten in Amazon S3 befinden. Eine Tabelle im Datenkatalog ist die Metadatendefinition, die die Daten in einem Datenspeicher darstellt. Standardmäßig erstellt Lake Formation Iceberg v2-Tabellen. Den Unterschied zwischen v1- und v2-Tabellen finden Sie unter Formatversionsänderungen
Apache Iceberg
Sie können die Lake Formation Formation-Konsole oder die CreateTable Operation in verwenden AWS Glue API, um eine Iceberg-Tabelle im Datenkatalog zu erstellen. Weitere Informationen finden Sie unter CreateTable action (Python: create_table).
Wenn Sie eine Iceberg-Tabelle im Datenkatalog erstellen, müssen Sie das Tabellenformat und den Metadatendateipfad in Amazon S3 angeben, um Lese- und Schreibvorgänge durchführen zu können.
Sie können Lake Formation verwenden, um Ihre Iceberg-Tabelle mithilfe detaillierter Zugriffskontrollberechtigungen zu sichern, wenn Sie den Amazon S3 S3-Datenstandort bei registrieren. AWS Lake Formation Für Quelldaten in Amazon S3 und Metadaten, die nicht bei Lake Formation registriert sind, wird der Zugriff durch die IAM Berechtigungsrichtlinien für Amazon S3 und AWS Glue Aktionen bestimmt. Weitere Informationen finden Sie unter Verwaltung von Lake Formation Formation-Berechtigungen.
Anmerkung
Data Catalog unterstützt nicht das Erstellen von Partitionen und das Hinzufügen von Iceberg-Tabelleneigenschaften.
Voraussetzungen
Um Iceberg-Tabellen im Datenkatalog zu erstellen und Lake Formation Formation-Datenzugriffsberechtigungen einzurichten, müssen Sie die folgenden Anforderungen erfüllen:
-
Zum Erstellen von Iceberg-Tabellen ohne die bei Lake Formation registrierten Daten sind Berechtigungen erforderlich.
Zusätzlich zu den Berechtigungen, die zum Erstellen einer Tabelle im Datenkatalog erforderlich sind, benötigt der Tabellenersteller die folgenden Berechtigungen:
s3:PutObjectauf der Ressource arn:aws:s3::: {} bucketName-
s3:GetObjectauf der Ressource arn:aws:s3::: {} bucketName -
s3:DeleteObjectauf der Ressource arn:aws:s3::: {} bucketName
-
Erforderliche Berechtigungen zum Erstellen von Iceberg-Tabellen mit bei Lake Formation registrierten Daten:
Um Lake Formation zur Verwaltung und Sicherung der Daten in Ihrem Data Lake zu verwenden, registrieren Sie Ihren Amazon S3 S3-Standort, der die Daten für Tabellen enthält, bei Lake Formation. Auf diese Weise kann Lake Formation Anmeldeinformationen an AWS Analysedienste wie Athena, Redshift Spectrum und Amazon weitergeben, EMR um auf Daten zuzugreifen. Weitere Informationen zur Registrierung eines Amazon S3 S3-Standorts finden Sie unterHinzufügen eines Amazon S3 S3-Standorts zu Ihrem Data Lake.
Ein Principal, der die zugrunde liegenden Daten liest und schreibt, die bei Lake Formation registriert sind, benötigt die folgenden Berechtigungen:
-
lakeformation:GetDataAccess -
DATA_LOCATION_ACCESSEin Principal, der über Datenspeicherberechtigungen für einen Standort verfügt, hat auch Standortberechtigungen für alle untergeordneten Standorte.
Weitere Informationen zu Datenstandortberechtigungen finden Sie unterZugrundeliegende Datenzugriffskontrolle.
-
Um die Komprimierung zu aktivieren, muss der Dienst eine IAM Rolle übernehmen, die über Berechtigungen zum Aktualisieren von Tabellen im Datenkatalog verfügt. Einzelheiten finden Sie unter Voraussetzungen für die Tabellenoptimierung.
Eine Iceberg-Tabelle erstellen
Sie können Iceberg v1- und v2-Tabellen mit der Lake Formation Formation-Konsole oder AWS Command Line Interface wie auf dieser Seite dokumentiert erstellen. Sie können Iceberg-Tabellen auch mit der AWS Glue Konsole oder erstellen. AWS-Glue-Crawler Weitere Informationen finden Sie unter Datenkatalog und Crawler im AWS Glue Entwicklerhandbuch.
Um eine Iceberg-Tabelle zu erstellen
Melden Sie sich bei an AWS Management Console und öffnen Sie die Lake Formation Formation-Konsole unter https://console.aws.amazon.com/lakeformation/
. Wählen Sie unter Datenkatalog die Option Tabellen aus, und verwenden Sie die Schaltfläche Tabelle erstellen, um die folgenden Attribute anzugeben:
-
Tabellenname: Geben Sie einen Namen für die Tabelle ein. Wenn Sie Athena für den Zugriff auf Tabellen verwenden, verwenden Sie diese Benennungstipps im Amazon Athena Athena-Benutzerhandbuch.
-
Datenbank: Wählen Sie eine bestehende Datenbank aus oder erstellen Sie eine neue.
-
Beschreibung: Die Beschreibung der Tabelle. Sie können eine Beschreibung zum besseren Verständnis der Inhalte der Tabelle schreiben.
-
Tabellenformat: Wählen Sie als Tabellenformat Apache Iceberg.
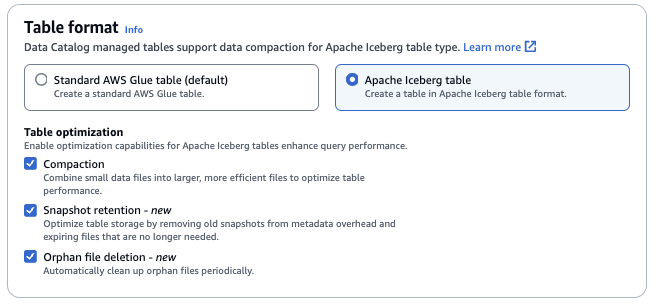
Tabellenoptimierung
-
Komprimierung — Datendateien werden zusammengeführt und neu geschrieben, veraltete Daten werden entfernt und fragmentierte Daten werden zu größeren, effizienteren Dateien konsolidiert.
Aufbewahrung von Snapshots — Snapshots sind Versionen einer Iceberg-Tabelle mit Zeitstempel. Mit Konfigurationen zur Aufbewahrung von Snapshots können Kunden festlegen, wie lange und wie viele Snapshots aufbewahrt werden sollen. Die Konfiguration eines Optimizers für die Aufbewahrung von Snapshots kann helfen, den Speicheraufwand zu minimieren, indem ältere, unnötige Snapshots und die zugehörigen zugrunde liegenden Dateien entfernt werden.
Löschen verwaister Dateien — Verwaiste Dateien sind Dateien, auf die in den Metadaten der Iceberg-Tabelle nicht mehr verwiesen wird. Diese Dateien können sich im Laufe der Zeit ansammeln, insbesondere nach Vorgängen wie dem Löschen von Tabellen oder fehlgeschlagenen Aufträgen. ETL Wenn Sie das Löschen verwaister Dateien aktivieren AWS Glue , können Sie diese unnötigen Dateien regelmäßig identifizieren und entfernen, wodurch Speicherplatz frei wird.
Weitere Informationen finden Sie unter Optimieren von Iceberg-Tabellen.
-
-
IAMRolle: Um die Komprimierung auszuführen, übernimmt der Dienst eine IAM Rolle in Ihrem Namen. Sie können über das Drop-down-Menü eine IAM Rolle auswählen. Die Rolle sollte die erforderlichen Berechtigungen für die Verdichtung haben.
Weitere Informationen zu den erforderlichen Berechtigungen finden Sie unter Voraussetzungen für die Tabellenoptimierung.
-
Speicherort: Geben Sie den Pfad zu dem Ordner in Amazon S3 an, in dem die Metadatentabelle gespeichert ist. Iceberg benötigt eine Metadatendatei und einen Speicherort im Datenkatalog, um Lese- und Schreibvorgänge durchführen zu können.
-
Schema: Wählen Sie Spalten hinzufügen, um Spalten und Datentypen der Spalten hinzuzufügen. Sie haben die Möglichkeit, eine leere Tabelle zu erstellen und das Schema später zu aktualisieren. Der Datenkatalog unterstützt Hive-Datentypen. Weitere Informationen finden Sie unter Hive-Datentypen
. Mit Iceberg können Sie Schema und Partition weiterentwickeln, nachdem Sie die Tabelle erstellt haben. Sie können Athena-Abfragen verwenden, um das Tabellenschema zu aktualisieren, und Spark-Abfragen
, um Partitionen zu aktualisieren.
-
