Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
AWS Lake Formation bietet ein RDBMS-Berechtigungsmodell (Relational Database Management System), um Zugriff auf Datenkatalogressourcen wie Datenbanken, Tabellen und Spalten mit zugrunde liegenden Daten in Amazon S3 zu gewähren oder zu entziehen. Die einfach zu verwaltenden Lake Formation Formation-Berechtigungen ersetzen die komplexen Amazon S3 S3-Bucket-Richtlinien und die entsprechenden IAM-Richtlinien.
In Lake Formation können Sie Berechtigungen auf zwei Ebenen implementieren:
Erzwingen von Berechtigungen auf Metadatenebene für Datenkatalogressourcen wie Datenbanken und Tabellen
Verwaltung von Speicherzugriffsberechtigungen für die zugrunde liegenden Daten, die in Amazon S3 gespeichert sind, im Auftrag integrierter Engines
Workflow zur Verwaltung von Berechtigungen in Lake Formation
Lake Formation lässt sich in Analyse-Engines integrieren, um Amazon S3 S3-Datenspeicher und Metadatenobjekte abzufragen, die bei Lake Formation registriert sind. Das folgende Diagramm zeigt, wie die Rechteverwaltung in Lake Formation funktioniert.
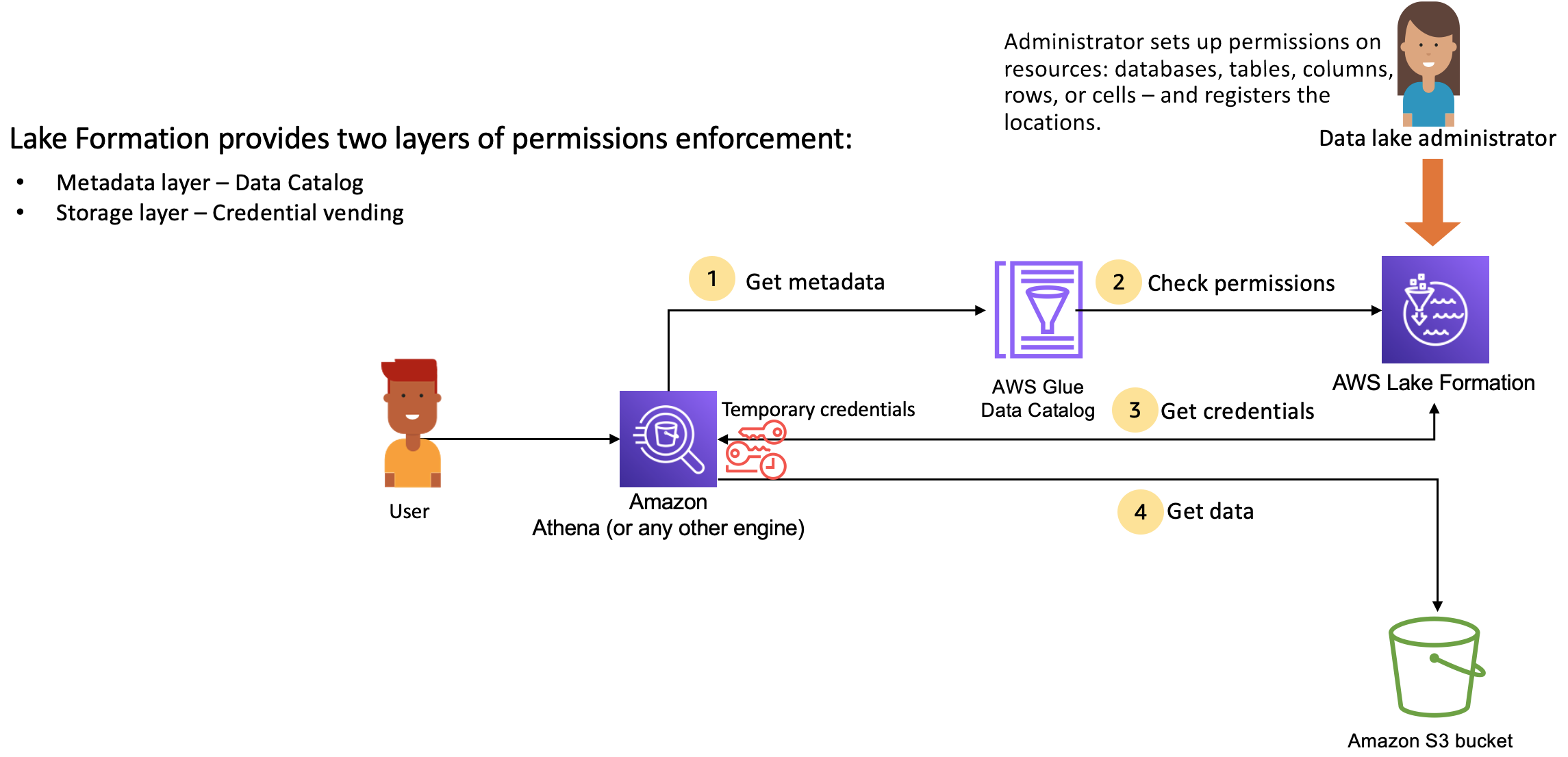
Wichtige Schritte zur Verwaltung von Berechtigungen bei Lake Formation
Bevor Lake Formation Zugriffskontrollen für Daten in Ihrem Data Lake bereitstellen kann, richtet ein Data Lake-Administrator oder ein Benutzer mit Administratorberechtigungen individuelle Benutzerrichtlinien für Datenkatalogtabellen ein, um den Zugriff auf Datenkatalogtabellen mithilfe von Lake Formation Formation-Berechtigungen zuzulassen oder zu verweigern.
Anschließend erteilt entweder der Data Lake-Administrator oder ein vom Administrator delegierter Benutzer Lake Formation-Berechtigungen für Benutzer in den Data Catalog-Datenbanken und -Tabellen und registriert den Amazon S3 S3-Speicherort der Tabelle bei Lake Formation.
Metadaten abrufen — Ein Principal (Benutzer) sendet eine Abfrage oder ein ETL-Skript an eine integrierte Analyse-Engine wie Amazon Athena AWS Glue, Amazon EMR oder Amazon Redshift Spectrum. Die integrierte Analyse-Engine identifiziert die Tabelle, die angefordert wird, und sendet eine Anfrage nach Metadaten an den Datenkatalog.
-
Berechtigungen überprüfen — Der Datenkatalog überprüft die Benutzerberechtigungen mit Lake Formation. Wenn der Benutzer berechtigt ist, auf die Tabelle zuzugreifen, gibt er die Metadaten, die der Benutzer sehen darf, an die Engine zurück.
-
Anmeldeinformationen abrufen — Der Datenkatalog teilt der Engine mit, ob die Tabelle von Lake Formation verwaltet wird oder nicht. Wenn die zugrunde liegenden Daten bei Lake Formation registriert sind, fordert die Analyse-Engine Lake Formation auf, Datenzugriff zu gewähren, indem temporärer Zugriff gewährt wird.
-
Daten abrufen — Wenn der Benutzer berechtigt ist, auf die Tabelle zuzugreifen, bietet Lake Formation temporären Zugriff auf die integrierte Analyse-Engine. Mithilfe des temporären Zugriffs ruft die Analyse-Engine die Daten von Amazon S3 ab und führt die erforderlichen Filter wie Spalten-, Zeilen- oder Zellenfilterung durch. Wenn die Engine die Ausführung des Jobs beendet hat, gibt sie die Ergebnisse an den Benutzer zurück. Dieser Vorgang wird als Verkauf von Anmeldeinformationen bezeichnet.
Wenn die Tabelle nicht von Lake Formation verwaltet wird, erfolgt der zweite Aufruf von der Analyse-Engine direkt an Amazon S3. Die betreffende Amazon S3 S3-Bucket-Richtlinie und die IAM-Benutzerrichtlinie werden im Hinblick auf den Datenzugriff bewertet.
Wenn Sie IAM-Richtlinien verwenden, stellen Sie sicher, dass Sie die bewährten IAM-Methoden befolgen. Weitere Informationen finden Sie unter Bewährte Methoden für die Sicherheit in IAM im IAM-Benutzerhandbuch.
Themen
