Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Steckverbinder verstehen
Ein Konnektor integriert externe Systeme und Amazon-Services mit Apache Kafka, indem er kontinuierlich Streaming-Daten aus einer Datenquelle in Ihren Apache-Kafka-Cluster kopiert oder kontinuierlich Daten aus Ihrem Cluster in einen Daten-Sink kopiert. Ein Konnektor kann auch einfache Logik wie Transformation, Formatkonvertierung oder Filterung von Daten ausführen, bevor die Daten an ein Ziel gesendet werden. Quell-Konnektoren rufen Daten aus einer Datenquelle ab und übertragen diese Daten in den Cluster, während Sink-Konnektoren Daten aus dem Cluster abrufen und diese Daten in einen Daten-Sink übertragen.
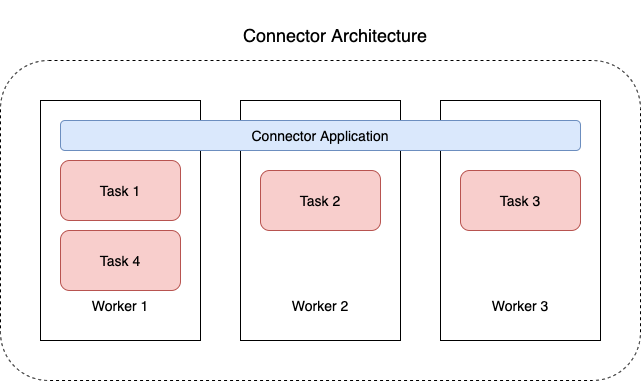
Das folgende Diagramm illustriert die Architektur eines Konnektors. Ein Worker ist ein virtueller Java-Maschine (JVM)-Prozess, der die Konnektor-Logik betreibt. Jeder Worker erstellt eine Reihe von Aufgaben, die in parallelen Threads ausgeführt werden und das Kopieren der Daten übernehmen. Aufgaben speichern keinen Status und können daher jederzeit gestartet, gestoppt oder neu gestartet werden, um eine stabile und skalierbare Datenpipeline bereitzustellen.