Aviso de fin de soporte: el 7 de octubre de 2026,AWS suspenderemos el soporte para AWS IoT Greengrass Version 1. Después del 7 de octubre de 2026, ya no podrá acceder a los AWS IoT Greengrass V1 recursos. Para obtener más información, visita Migrar desde AWS IoT Greengrass Version 1.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Opcional: Configuración del dispositivo para la cualificación ML
IDT for AWS IoT Greengrass ofrece pruebas de calificación de aprendizaje automático (ML) para validar que sus dispositivos pueden realizar inferencias de aprendizaje automático de forma local mediante modelos entrenados en la nube.
Para ejecutar pruebas de cualificación de ML, primero debe configurar los dispositivos como se describe en Configuración de su dispositivo para ejecutar pruebas de IDT. A continuación, siga los pasos de este tema para instalar dependencias para los marcos de ML que desea ejecutar.
Es necesario IDT v3.1.0 o posterior para realizar pruebas de cualificación de ML.
Instalación de dependencias del marco de ML
Todas las dependencias del marco de ML deben instalarse en el directorio /usr/local/lib/python3.x/site-packages. Para asegurarse de que están instalados en el directorio correcto, le recomendamos que utilice permisos raíz de sudo al instalar las dependencias. Los entornos virtuales no son compatibles con las pruebas de cualificación.
nota
Si está probando funciones de Lambda que se ejecutan con la creación de contenedores (en modo contenedor de Greengrass), la creación de enlaces simbólicos para las bibliotecas Python en /usr/local/lib/python3.x no se admite. Para evitar errores, debe instalar las dependencias en el directorio correcto.
Siga los pasos para instalar las dependencias para su marco de destino:
Instalar dependencias de Apache MXNet
Las pruebas de cualificación IDT para este marco tienen las siguientes dependencias:
-
Python 3.6 o Python 3.7.
nota
Si está utilizando Python 3.6, debe crear un enlace simbólico desde binarios de Python 3.7 a Python 3.6. Esto configura su dispositivo para que cumpla con el requisito de Python para AWS IoT Greengrass. Por ejemplo:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7 -
Apache MXNet v1.2.1 o posterior.
-
NumPy. La versión debe ser compatible con su versión de MXNet.
Instalación de MXNet
Siga las instrucciones de la documentación de MXNet para instalar MXNet
nota
Si en el dispositivo están instalados Python 2.x y Python 3.x, use Python 3.x en los comandos que ejecute para instalar las dependencias.
Validación de la instalación de MXNet
Elija una de las siguientes opciones para validar la instalación de MXNet.
Opción 1: SSH en su dispositivo y ejecutar scripts
-
SSH en su dispositivo.
-
Ejecute los siguientes scripts para comprobar que las dependencias están instaladas correctamente.
sudo python3.7 -c "import mxnet; print(mxnet.__version__)"sudo python3.7 -c "import numpy; print(numpy.__version__)"El resultado imprime el número de versión y el script debe salir sin errores.
Opción 2: Ejecutar la prueba de dependencia IDT
-
Asegúrese de que
device.jsonesté configurado para la cualificación de ML. Para obtener más información, consulte Configurar device.json para cualificación de ML. -
Ejecute la prueba de dependencias para el marco.
devicetester_[linux | mac | win_x86-64]run-suite --group-id mldependencies --test-id mxnet_dependency_checkEl resumen de la prueba muestra un resultado
PASSEDparamldependencies.
Instale TensorFlow las dependencias
Las pruebas de cualificación IDT para este marco tienen las siguientes dependencias:
-
Python 3.6 o Python 3.7.
nota
Si está utilizando Python 3.6, debe crear un enlace simbólico desde binarios de Python 3.7 a Python 3.6. Esto configura su dispositivo para que cumpla con el requisito de Python para AWS IoT Greengrass. Por ejemplo:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7 -
TensorFlow 1.x.
Instalando TensorFlow
Siga las instrucciones de la TensorFlow documentación para instalar TensorFlow 1.x con pip
nota
Si en el dispositivo están instalados Python 2.x y Python 3.x, use Python 3.x en los comandos que ejecute para instalar las dependencias.
Validar la instalación TensorFlow
Elija una de las siguientes opciones para validar la TensorFlow instalación.
Opción 1: SSH en su dispositivo y ejecutar un script
-
SSH en su dispositivo.
-
Ejecute el siguiente script para comprobar que la dependencia está instalada correctamente.
sudo python3.7 -c "import tensorflow; print(tensorflow.__version__)"El resultado imprime el número de versión y el script debe salir sin errores.
Opción 2: Ejecutar la prueba de dependencia IDT
-
Asegúrese de que
device.jsonesté configurado para la cualificación de ML. Para obtener más información, consulte Configurar device.json para cualificación de ML. -
Ejecute la prueba de dependencias para el marco.
devicetester_[linux | mac | win_x86-64]run-suite --group-id mldependencies --test-id tensorflow_dependency_checkEl resumen de la prueba muestra un resultado
PASSEDparamldependencies.
Instalación de las dependencias de Amazon SageMaker AI Neo Deep Learning Runtime (DLR)
Las pruebas de cualificación IDT para este marco tienen las siguientes dependencias:
-
Python 3.6 o Python 3.7.
nota
Si está utilizando Python 3.6, debe crear un enlace simbólico desde binarios de Python 3.7 a Python 3.6. Esto configura su dispositivo para que cumpla con el requisito de Python para AWS IoT Greengrass. Por ejemplo:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7 -
SageMaker DLR AI Neo.
-
numpy.
Después de instalar las dependencias de prueba DLR, debe compilar el modelo.
Instalación de DLR
Siga las instrucciones de la documentación de DLR para instalar el DLR Neo
nota
Si en el dispositivo están instalados Python 2.x y Python 3.x, use Python 3.x en los comandos que ejecute para instalar las dependencias.
Validación de la instalación de DLR
Elija una de las siguientes opciones para validar la instalación de DLR.
Opción 1: SSH en su dispositivo y ejecutar scripts
-
SSH en su dispositivo.
-
Ejecute los siguientes scripts para comprobar que las dependencias están instaladas correctamente.
sudo python3.7 -c "import dlr; print(dlr.__version__)"sudo python3.7 -c "import numpy; print(numpy.__version__)"El resultado imprime el número de versión y el script debe salir sin errores.
Opción 2: Ejecutar la prueba de dependencia IDT
-
Asegúrese de que
device.jsonesté configurado para la cualificación de ML. Para obtener más información, consulte Configurar device.json para cualificación de ML. -
Ejecute la prueba de dependencias para el marco.
devicetester_[linux | mac | win_x86-64]run-suite --group-id mldependencies --test-id dlr_dependency_checkEl resumen de la prueba muestra un resultado
PASSEDparamldependencies.
Compilar el modelo DLR
Debe compilar el modelo DLR antes de poder usarlo para pruebas de cualificación de ML. Para los pasos, elija una de las siguientes opciones.
Opción 1: usar Amazon SageMaker AI para compilar el modelo
Siga estos pasos para usar la SageMaker IA para compilar el modelo de aprendizaje automático proporcionado por IDT. Este modelo está entrenado previamente con Apache MXNet.
-
Compruebe que su tipo de dispositivo sea compatible con SageMaker AI. Para obtener más información, consulta las opciones del dispositivo de destino en la referencia de la API de Amazon SageMaker AI. Si tu tipo de dispositivo no es compatible actualmente con la SageMaker IA, sigue los pasos que se indicanOpción 2: Utilice TVM para compilar el modelo DLR.
nota
La ejecución de la prueba de DLR con un modelo compilado por la SageMaker IA puede tardar entre 4 y 5 minutos. No detenga IDT durante este tiempo.
-
Descargue el archivo tarball que contiene el modelo MXNet no compilado y entrenado previamente para DLR:
-
Descomprima el tarball. Este comando genera la siguiente estructura de directorios.

-
Saque
synset.txtdel directorioresnet18. Anote la nueva ubicación. Copie este archivo en el directorio del modelo compilado más adelante. -
Comprima el contenido del directorio
resnet18.tar cvfz model.tar.gz resnet18v1-symbol.json resnet18v1-0000.params -
Suba el archivo comprimido a un bucket de Amazon S3 de su cuenta y Cuenta de AWS, a continuación, siga los pasos de Compilar un modelo (consola) para crear un trabajo de compilación.
-
En Configuración de entrada, utilice los siguientes valores:
-
En Configuración de entrada de datos, escriba
{"data": [1, 3, 224, 224]}. -
En Marco de machine learning, elija
MXNet.
-
-
En Configuración de salida, utilice los siguientes valores:
-
En Ubicación de salida de S3, escriba la ruta de acceso al bucket de Amazon S3 o carpeta donde desea almacenar el modelo compilado.
-
En Dispositivo de destino, elija el tipo de dispositivo.
-
-
-
Descargue el modelo compilado desde la ubicación de salida especificada y, a continuación, descomprima el archivo.
-
Copie
synset.txten el directorio del modelo compilado. -
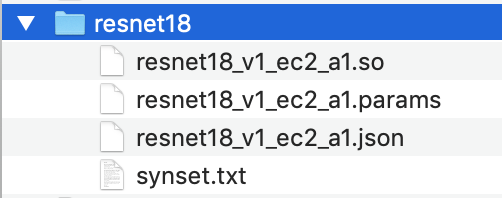
Cambie el nombre del directorio del modelo compilado a
resnet18.El directorio del modelo compilado debe tener la siguiente estructura de directorios.
Opción 2: Utilice TVM para compilar el modelo DLR
Siga estos pasos para utilizar TVM para compilar el modelo de ML proporcionado por IDT. Este modelo está entrenado previamente con Apache MXNet, por lo que debe instalar MXNet en el equipo o dispositivo donde se compila el modelo. Para instalar MXNet, siga las instrucciones de la documentación de MXNet
nota
Le recomendamos que compile el modelo en el dispositivo de destino. Esta práctica es opcional, pero puede ayudar a garantizar la compatibilidad y mitigar posibles problemas.
-
Descargue el archivo tarball que contiene el modelo MXNet no compilado y entrenado previamente para DLR:
-
Descomprima el tarball. Este comando genera la siguiente estructura de directorios.
-
Siga las instrucciones de la documentación de TVM para compilar e instalar TVM desde el origen para su plataforma
. -
Una vez compilado TVM, ejecute la compilación TVM para el modelo resnet18. Los siguientes pasos se basan en la explicación de inicio rápido para compilar modelos de aprendizaje profundo
en la documentación de TVM. -
Abra el archivo
relay_quick_start.pydesde el repositorio de TVM clonado. -
Actualice el código que define una red neuronal en relé
. Puede utilizar una de las siguientes opciones: -
Opción 1: Utilice
mxnet.gluon.model_zoo.vision.get_modelpara obtener el módulo de relé y los parámetros:from mxnet.gluon.model_zoo.vision import get_model block = get_model('resnet18_v1', pretrained=True) mod, params = relay.frontend.from_mxnet(block, {"data": data_shape}) -
Opción 2: Desde el modelo no compilado que descargó en el paso 1, copie los siguientes archivos en el mismo directorio que el archivo
relay_quick_start.py. Estos archivos contienen el módulo de relé y los parámetros.-
resnet18v1-symbol.json -
resnet18v1-0000.params
-
-
-
Actualice el código que guarda y carga el módulo compilado
para utilizar el siguiente código. from tvm.contrib import util path_lib = "deploy_lib.so" # Export the model library based on your device architecture lib.export_library("deploy_lib.so", cc="aarch64-linux-gnu-g++") with open("deploy_graph.json", "w") as fo: fo.write(graph) with open("deploy_param.params", "wb") as fo: fo.write(relay.save_param_dict(params)) -
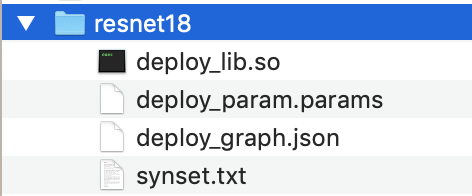
Compile el modelo:
python3 tutorials/relay_quick_start.py --build-dir ./modelEste comando genera los archivos siguientes.
-
deploy_graph.json -
deploy_lib.so -
deploy_param.params
-
-
-
Copie los archivos de modelo generados en un directorio denominado
resnet18. Este es su directorio de modelo compilado. -
Copie el directorio del modelo compilado en el equipo host. A continuación, copie
synset.txtdel modelo sin compilar que descargó en el paso 1 en el directorio del modelo compilado.El directorio del modelo compilado debe tener la siguiente estructura de directorios.
A continuación, configure AWS las credenciales y device.json el archivo.
