Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Entraînez et évaluez DeepRacer des modèles AWS à l'aide de la DeepRacer console AWS
Pour former un modèle d'apprentissage par renforcement, vous pouvez utiliser la DeepRacer console AWS. Dans la console, créez une tâche de formation, choisissez une infrastructure prise en charge et un algorithme disponible, ajoutez une fonction de récompense et configurez les paramètres de formation. Vous pouvez également observer l'exécution de la formation dans un simulateur. Vous trouverez les step-by-step instructions dansEntraînez votre premier DeepRacer modèle AWS .
Cette section explique comment former et évaluer un DeepRacer modèle AWS. Elle explique également la création et l'amélioration d'une fonction de récompense, l'impact de l'espace d'action sur les performances d'un modèle ainsi que l'impact des hyperparamètres sur l'efficacité de la formation. Vous pouvez également apprendre à cloner un modèle de formation afin d'étendre une session de formation, à utiliser le simulateur pour évaluer les performances de la formation et à adapter la simulation aux défis des situations réelles.
Rubriques
- Créez votre fonction de récompense
- Explorez l'espace d'action pour entraîner un modèle robuste
- Régler systématiquement les hyperparamètres
- Examinez la progression DeepRacer des tâches de formation AWS
- Clonez un modèle entraîné pour démarrer une nouvelle passe d'entraînement
- Évaluez les DeepRacer modèles AWS dans le cadre de simulations
- Optimisez les DeepRacer modèles AWS de formation pour les environnements réels
Créez votre fonction de récompense
Une fonction de récompense décrit un feedback immédiat (sous forme de récompense ou de score de pénalité) lorsque votre DeepRacer véhicule AWS passe d'une position sur la piste à une nouvelle position. La fonction vise à encourager le véhicule à se déplacer le long de la piste pour atteindre une destination rapidement, sans accident ni infraction. Un déplacement préféré entraîne un score plus élevé pour l'action ou son état cible. Un déplacement illégal ou inefficace entraîne un score inférieur. Lors de la formation d'un DeepRacer modèle AWS, la fonction de récompense est la seule partie spécifique à l'application.
En général, vous concevez votre fonction de récompense comme un programme incitatif. Les différentes stratégies incitatives peuvent entraîner différents comportements du véhicule. Pour que le véhicule aille plus vite, la fonction doit accorder une récompense lorsque le véhicule suit la piste. La fonction doit donner des pénalités lorsque le véhicule effectue un tour trop lentement ou sort de la piste. Pour éviter les zig-zags, la fonction peut récompenser le véhicule s'il effectue moins de changements de direction sur les lignes les plus droites de la piste. La fonction de récompense peut accorder des scores positifs lorsque le véhicule atteint des points intermédiaires, mesurés par les waypoints. Cela permet de réduire l'attente ou d'éviter de prendre la mauvaise direction. Il est également possible de modifier la fonction de récompense pour tenir compte des conditions de la piste. Cependant, plus votre fonction de récompense prend en compte les informations spécifiques à l'environnement, plus votre modèle formé est trop spécialisé et précis. Pour que votre modèle soit plus généralement applicable, vous pouvez explorer la notion d'espace d'action.
S'il n'est pas soigneusement réfléchi, un programme incitatif peut entraîner un effet inverse à celui souhaité et des conséquences inattendues
Pour créer une fonction de récompense, une bonne pratique consiste à commencer par une fonction simple qui couvre des scénarios élémentaires. Vous pouvez perfectionner la fonction afin de prendre en charge un plus grand nombre d'actions. Examinons maintenant quelques fonctions de récompense simples.
Exemples de fonctions de récompense simples
Nous pouvons commencer à créer la fonction de récompense à partir de la situation la plus élémentaire possible : piloter une sur piste rectiligne de la ligne de départ à la ligne d'arrivée, sans sortir de la piste. Dans ce scénario, la logique de la fonction de récompense dépend uniquement de on_track et de progress. À titre d'expérimentation, vous pouvez commencer avec la logique suivante :
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else if params["progress"] == 1 : reward = 10 return reward
Cette logique pénalise l'agent lorsqu'il sort de la piste. Elle récompense l'agent lorsqu'il passe la ligne d'arrivée. Compte tenu de l'objectif défini, cette logique est acceptable. Toutefois, l'agent erre librement entre la ligne de départ et la ligne d'arrivée, par exemple en roulant en sens inverse. Cela signifie non seulement que la formation risque de prendre beaucoup de temps, mais aussi que le modèle formé limitera l'efficacité de la conduite une fois qu'il aura été déployé sur un véhicule réel.
Dans la pratique, un agent apprend plus efficacement s'il peut le faire bit-by-bit tout au long de sa formation. Cela signifie qu'une fonction de récompense doit distribuer des récompenses plus petites, étape par étape, tout le long du parcours. Pour permettre à l'agent d'évoluer sur la piste rectiligne, nous pouvons améliorer la fonction de récompense comme suit :
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else: reward = params["progress"] return reward
Avec cette fonction, plus l'agent se rapproche de la ligne d'arrivée, plus il reçoit de récompenses. Cela vise à réduire ou à éliminer les essais improductifs de déplacement en sens inverse. En général, la fonction de récompense doit mieux répartir les récompenses dans l'espace d'action. Créer une fonction de récompense efficace peut être une tâche ardue. Vous devez commencer par une fonction simple que vous améliorerez et perfectionnerez progressivement. En procédant à une expérimentation systématique, la fonction peut devenir plus fiable et efficace.
Améliorez votre fonction de récompense
Une fois que vous avez correctement entraîné votre DeepRacer modèle AWS à suivre la voie droite, le DeepRacer véhicule AWS (virtuel ou physique) peut se conduire tout seul sans sortir de la piste. Si vous faites circuler le véhicule sur une piste en anneau, il ne restera pas sur la piste. La fonction de récompense a ignoré les actions permettant de prendre les virages et de suivre la piste.
Pour que votre véhicule gère ces actions, vous devez perfectionner la fonction de récompense. La fonction doit accorder une récompense lorsque l'agent effectue un virage autorisé et donner une pénalité si l'agent effectue un changement de direction interdit. Vous êtes ensuite prêt à démarrer une autre phase de formation. Pour mettre à profit la formation précédente, vous pouvez démarrer la nouvelle formation en clonant le modèle précédemment entraîné, ce qui permet de transmettre les connaissances acquises précédemment. Vous pouvez suivre ce modèle pour ajouter progressivement de nouvelles fonctionnalités à la fonction de récompense afin d'entraîner votre DeepRacer véhicule AWS à conduire dans des environnements de plus en plus complexes.
Pour des fonctions de récompense plus avancées, veuillez consulter les exemples suivants :
Explorez l'espace d'action pour entraîner un modèle robuste
En règle générale, vous devez former votre modèle afin qu'il soit le plus fiable possible pour que vous puissiez l'appliquer au plus grand nombre d'environnements possibles. Un modèle fiable est un modèle qui peut être appliqué à un large éventail de formes et de conditions de piste. En règle générale, un modèle fiable n'est pas « intelligent », car sa fonction de récompense n'est pas en mesure de contenir des connaissances explicites spécifiques à l'environnement. Sinon, votre modèle serait alors susceptible d'être applicable uniquement à un environnement similaire à celui de la formation.
L'intégration d'informations spécifiques à l'environnement explicitement dans la fonction de récompense s'apparente à l'ingénierie de fonctionnalité. L'ingénierie de fonctionnalité contribue à réduire le temps de formation et peut s'avérer utile dans des solutions adaptées à un environnement spécifique. Mais pour former un modèle généralement applicable, vous devez éviter de trop y recourir.
Par exemple, lorsque vous formez un modèle sur une piste en anneau, vous ne pouvez pas espérer obtenir un modèle formé applicable à n'importe quelle piste non circulaire si ces propriétés géométriques sont explicitement intégrées dans la fonction de récompense.
Comment est-il possible de former le modèle le plus fiable possible, tout en préservant une fonction de récompense la plus simple possible ? L'une des solutions consiste à explorer l'espace d'action qui couvre les actions pouvant être effectuées par votre agent. Une autre solution consiste à tester les hyperparamètres de l'algorithme de formation sous-jacent. Vous optez souvent pour les deux solutions. Nous nous concentrons ici sur la manière d'explorer l'espace d'action afin de créer un modèle robuste pour votre DeepRacer véhicule AWS.
Lors de l'entraînement d'un DeepRacer modèle AWS, une action (a) est une combinaison de la vitesse (tmètres par seconde) et de l'angle de braquage (sen degrés). L'espace d'action de l'agent définit les plages de vitesse et d'angle de direction que l'agent peut utiliser. Pour un espace d'action distinct d'un nombre de vitesses m (v1, .., vn) et d'un nombre d'angles de direction n, (s1, ..,
sm), il existe m*n actions possibles dans l'espace d'action :
a1: (v1, s1) ... an: (v1, sn) ... a(i-1)*n+j: (vi, sj) ... a(m-1)*n+1: (vm, s1) ... am*n: (vm, sn)
Les valeurs réelles de (vi,
sj) dépendent des plages de vmax et de |smax| et ne sont pas réparties uniformément.
Chaque fois que vous commencez à former ou à itérer votre DeepRacer modèle AWS, vous devez d'abord spécifier vmax les nm, |smax| et/ou accepter d'utiliser leurs valeurs par défaut. En fonction de votre choix, le DeepRacer service AWS génère les actions disponibles que votre agent peut choisir pendant la formation. Les actions générées ne sont pas réparties uniformément sur l'espace d'action.
En général, lorsque votre agent dispose d'un plus grand nombre d'actions et de plages d'action plus larges, il bénéficie d'un plus grand espace ou de plus d'options qui lui permettent de réagir à des conditions de piste plus variées, par exemple une piste courbe avec des directions ou des angles de virage irréguliers. Plus l'agent dispose d'options, plus il peut être réactif pour gérer les variations d'une piste. Le modèle formé sera alors plus largement applicable, même si vous utilisez une fonction de récompense simple.
Votre agent peut par exemple apprendre rapidement à gérer une piste linéaire à l'aide d'un espace d'action approximatif avec petit nombre de vitesses et d'angles de direction. Dans une piste courbe, l'agent risque d'aller trop loin et de sortir de la piste dans un virage si l'espace d'action est approximatif. Il dispose en effet de trop peu d'options pour ajuster la vitesse ou la direction. Si vous augmentez le nombre de vitesses ou le nombre d'angles de direction, ou les deux, l'agent sera plus à même de gérer les courbes tout en restant sur la piste. De la même façon, si votre agent se met à se déplacer en zig-zag, vous pouvez essayer d'augmenter le nombre de plages de direction pour limiter les virages serrés répétés.
Lorsque l'espace d'action est trop grand, les performances de la formation peuvent en pâtir : il faut en effet plus de temps pour l'explorer. Veillez à trouver l'équilibre entre les avantages d'un modèle applicable généralement et les exigences en matière de performances de la formation du modèle. Cette optimisation implique de procéder à une expérimentation systématique.
Régler systématiquement les hyperparamètres
Pour améliorer les performances de votre modèle, vous pouvez adopter un processus de formation plus efficace ou de meilleure qualité. Par exemple, pour obtenir un modèle fiable, la formation doit proposer à votre agent un échantillonnage réparti assez uniformément sur l'espace d'action de l'agent. Pour cela, l'exploration et l'exploitation doivent être suffisantes. Les variables qui ont un impact sont notamment la quantité de données de formation utilisées (number of episodes between each
training et batch size), la vitesse d'apprentissage de l'agent (learning rate), la portion de l'exploration (entropy). Pour que la formation soit pratique, il peut être judicieux d'accélérer le processus d'apprentissage. Les variables ayant un impact sont notamment learning rate, batch size, number of
epochs et discount factor.
Les variables ayant un impact sur le processus de formation sont appelées les hyperparamètres de la formation. Ces attributs d'algorithme ne sont pas des propriétés du modèle sous-jacent. Malheureusement, par nature, les hyperparamètres sont empiriques. Leurs valeurs optimales ne sont pas connues pour tous les usages pratiques et doivent faire l'objet d'une expérimentation systématique pour être dérivées.
Avant de discuter des hyperparamètres qui peuvent être ajustés pour optimiser les performances de formation de votre DeepRacer modèle AWS, définissons la terminologie suivante.
- Point de données
-
Un point de données, également connu sous le nom d'expérience, est un tuple de (s,a,r,s’), où s représente une observation (ou état) capturée par la caméra, a une action effectuée par le véhicule, r la récompense prévue liée à l'action concernée et s’ la nouvelle observation après l'action.
- Épisode
-
Un épisode est une période pendant laquelle le véhicule démarre d'un point de départ et termine soit après avoir parcouru toute la piste, soit à cause d'une sortie de piste. Il représente une suite d'expériences. Différents épisodes peuvent avoir des longueurs différentes.
- Tampon d'expérience
-
Un tampon d'expérience se compose d'un certain nombre de points de données triés collectés pendant un nombre d'épisodes fixe de différentes longueurs pendant la formation. Pour AWSDeepRacer, il correspond aux images capturées par la caméra montée sur votre DeepRacer véhicule AWS et aux actions entreprises par le véhicule et sert de source à partir de laquelle les données sont extraites pour mettre à jour les réseaux neuronaux sous-jacents (politiques et valeurs).
- Par lots
-
Un lot est une liste triée d'expériences, qui représente une partie d'une simulation sur une période donnée, utilisée pour mettre à jour les pondérations du réseau de politique. C'est un sous-ensemble du tampon d'expérience.
- Données de formation
-
Une donnée de formation est un ensemble de lots de données échantillonnés de façon aléatoire à partir d'un tampon d'expérience et utilisé pour la former les pondérations du réseau de politique.
| Hyperparamètres | Description |
|---|---|
|
Gradient descent batch size (Taille de lot pour la descente de gradient) |
Nombre d'expériences de véhicules récentes échantillonnées de façon aléatoire à partir d'un tampon d'expérience et utilisées pour mettre à jour les pondérations du réseau neuronal de deep learning sous-jacents. L'échantillonnage aléatoire contribue à réduire les corrélations inhérentes dans les données d'entrée. Utilisez une taille de lot plus grande pour promouvoir des mises à jour plus stables et fluides des pondérations du réseau neuronal, mais sachez que cela peut ralentir et allonger la formation.
|
|
Number of epochs (Nombre d'époques) |
Nombre de transmissions des données de formation pour mettre à jour les pondérations du réseau neuronal pendant la descente de gradient. Les données de formation correspondent à des échantillons aléatoires du tampon d'expérience. Utilisez un plus grand nombre d'époques pour promouvoir des mises à jour plus stables, mais sachez que cela peut ralentir la formation. Lorsque le lot est de petite taille, vous pouvez utiliser un nombre d'époques inférieur
|
|
Learning rate (Taux d'apprentissage) |
À chaque mise à jour, une partie de la nouvelle pondération peut provenir de la descente (ou ascension) de gradient et le reste de la valeur de pondération existante. Le taux d'apprentissage contrôle dans quelle mesure la mise à jour d'une descente (ou ascension) de gradient contribue aux pondérations du réseau. Utilisez un taux d'apprentissage plus élevé pour inclure plus de contributions de descente de gradient afin d'accélérer la formation, mais sachez que la récompense prévue peut ne pas converger si le taux d'apprentissage est trop élevé.
|
Entropy |
Degré d'incertitude utilisé pour déterminer quand ajouter un caractère aléatoire à la distribution de la politique. L'incertitude supplémentaire aide le DeepRacer véhicule AWS à explorer l'espace d'action de manière plus large. Une valeur d'entropie plus élevée encourage le véhicule à explorer plus minutieusement l'espace d'action.
|
| Discount factor (Facteur d'actualisation) |
Facteur précisant l'importance de la contribution de la future récompense à la récompense attendue. Plus la valeur de Discount factor (Facteur d'actualisation) est élevée, plus le véhicule prend en compte les contributions les plus éloignées pour effectuer un déplacement, et plus la formation est lente. Avec un facteur d'actualisation de 0,9, le véhicule inclut les récompenses de 10 étapes futures pour effectuer un déplacement. Avec un facteur d'actualisation de 0,999, le véhicule inclut les récompenses de 1 000 étapes futures pour effectuer un déplacement. Les valeurs de facteur d'actualisation recommandées sont 0,99, 0,999 et 0,9999.
|
| Loss type (Type de perte) |
Type de la fonction objective utilisée pour mettre à jour les pondérations de réseau. Un bon algorithme de formation doit apporter des modifications incrémentielles à la stratégie de l'agent de sorte que les actions aléatoires cèdent progressivement la place à des actions stratégiques pour accroître la récompense. Mais si la modification est trop importante, la formation devient instable et l'agent n'apprend plus. Les types Huber loss (Perte Huber)
|
| Nombre d'épisodes d'expérience entre chaque itération de mise à jour de politique | Taille du tampon d'expérience utilisé pour extraire les données de formation pour les pondérations du réseau de politique d'apprentissage. Un épisode d'expérience est une période pendant laquelle l'agent démarre d'un point de départ et termine soit après avoir parcouru toute la piste, soit à cause d'une sortie de piste. Il se compose d'une suite d'expériences. Différents épisodes peuvent avoir des longueurs différentes. Pour les problèmes d'apprentissage par renforcement simples, un petit tampon d'expérience peut être suffisant et l'apprentissage est rapide. Pour les problèmes plus complexes qui ont plus de maximum local, un tampon d'expérience plus grand est nécessaire pour fournir plus de points de données indépendants. Dans ce cas, la formation est plus lente, mais plus stable. Les valeurs recommandées sont 10, 20 et 40.
|
Examinez la progression DeepRacer des tâches de formation AWS
Après avoir démarré votre tâche de formation, vous pouvez examiner les métriques de formation des récompenses et l’achèvement des pistes par épisode pour vérifier les performances de votre modèle au niveau de la tâche de formation. Sur la DeepRacer console AWS, les métriques sont affichées dans le graphique des récompenses, comme le montre l'illustration suivante.
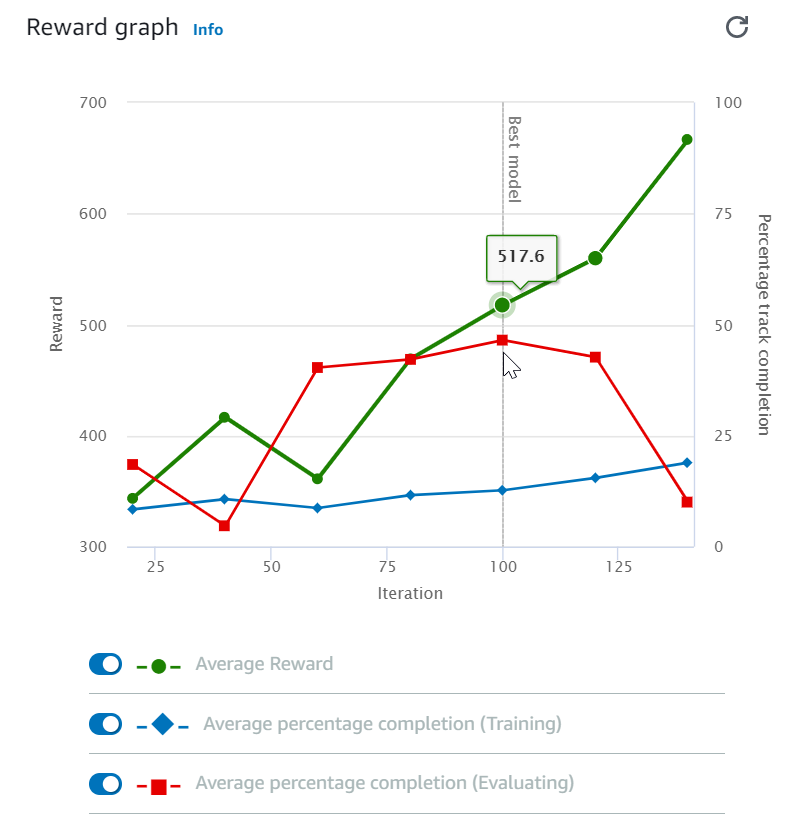
Vous pouvez choisir d'afficher la récompense obtenue par épisode, la moyenne de récompenses par itération, la progression par épisode, la progression moyenne par itération ou toute combinaison de ces éléments. Pour ce faire, basculez les commutateurs Récompense (Épisode, Moyenne) ou Progression (Épisode, Moyenne) en bas du graphique des récompenses. La récompense et la progression par épisode s'affichent sous la forme de diagrammes de dispersion dans différentes couleurs. Les moyennes des récompenses et d’achèvement des pistes sont affichées par graphique linéaire et commencent après la première itération.
La plage de récompenses est affichée sur le côté gauche du graphique et la plage de progression (0-100) est sur le côté droit. Pour lire la valeur exacte d'une métrique de formation, déplacez la souris près du point de données sur le graphique.
Les graphiques sont automatiquement mis à jour toutes les 10 secondes pendant que la formation est en cours. Vous pouvez cliquer sur le bouton d'actualisation pour mettre à jour manuellement l'affichage des métriques.
Une tâche de formation est bonne si les moyennes des récompenses et d’achèvement des pistes montrent des tendances convergentes. Ainsi, le modèle a probablement convergé si la progression par épisode atteint continuellement 100 % et que les récompenses s'épuisent. Si ce n'est pas le cas, clonez le modèle et reformez-le.
Clonez un modèle entraîné pour démarrer une nouvelle passe d'entraînement
Si vous clonez un modèle précédemment formé en tant que point de départ d'un nouveau cycle de formation, vous pouvez améliorer l'efficacité de la formation. Pour ce faire, modifiez les hyperparamètres pour utiliser les connaissances déjà acquises.
Dans cette section, vous allez apprendre à cloner un modèle entraîné à l'aide de la DeepRacer console AWS.
Pour itérer la formation, le modèle d'apprentissage par renforcement à l'aide de la console AWS DeepRacer
-
Connectez-vous à la DeepRacer console AWS, si ce n'est pas déjà fait.
-
Sur la page Models (Modèles), choisissez un modèle formé, puis sélectionnez Clone (Cloner) dans la liste du menu déroulant Action (Action).
-
Pour Model details (Détails du modèle), effectuez les opérations suivantes :
-
Entrez
RL_model_1dans Model name (Nom du modèle) si vous ne voulez pas qu'un nom soit généré pour le modèle cloné. -
Vous pouvez également fournir une description du to-be-cloned modèle dans Description du modèle - facultatif.
-
-
Pour la simulation de l'environnement, choisissez une autre option de piste.
-
Pour Reward function (Fonction de récompense), choisissez l'un des exemples de fonctions de récompense disponibles. Modifiez la fonction de récompense. Examinez par exemple la direction.
-
Développez Algorithm settings (Paramètres d'algorithme) et essayez différentes options. Passez par exemple la valeur de Gradient descent batch size (Taille de lot pour la descente de gradient) de 32 à 64 ou augmentez la valeur de Learning rate (Taux d'apprentissage) pour accélérer la formation.
-
Testez les différentes options de Stop conditions (Conditions d'arrêt).
-
Choisissez Start training (Démarrer la formation) pour débuter une nouvelle phase de formation.
Comme c'est généralement le cas lorsqu'il s'agit de former un modèle de Machine Learning fiable, il est important de procéder à des expérimentations systématiques pour trouver la meilleure solution.
Évaluez les DeepRacer modèles AWS dans le cadre de simulations
Évaluer un modèle consiste à tester l'efficacité d'un modèle formé. Dans AWSDeepRacer, l'indicateur de performance standard est le temps moyen passé au bout de trois tours consécutifs. À l'aide de cette métrique, pour deux modèles quelconques, l'un est meilleur que l'autre s'il permet à l'agent d'avancer plus rapidement sur la même voie.
En général, l'évaluation d'un modèle comprend les tâches suivantes :
-
Configurer et lancer une tâche d'évaluation.
-
Observer l'évaluation en cours pendant que la tâche s'exécute. Cela peut être fait dans le DeepRacer simulateur AWS.
-
Examiner le récapitulatif d'évaluation à l'issue de la tâche d'évaluation. Vous pouvez à tout moment mettre fin à une tâche d'évaluation en cours.
Note
La durée de l'évaluation dépend des critères que vous sélectionnez. Si votre modèle ne répond pas aux critères d'évaluation, l'évaluation se poursuivra jusqu'à ce que la limite de 20 minutes soit atteinte.
-
Vous pouvez également soumettre le résultat de l'évaluation à un DeepRacerclassement AWS éligible. La place sur le tableau des scores vous permet de comparer les performances de votre modèle à celles des autres participants.
Testez un DeepRacer modèle AWS avec un DeepRacer véhicule AWS circulant sur une piste physique, voirPilotez votre DeepRacer véhicule AWS .
Optimisez les DeepRacer modèles AWS de formation pour les environnements réels
De nombreux facteurs influencent les performances d'un modèle formé dans un environnement réel, notamment l'espace d'action choisi, la fonction de récompense, les hyperparamètres utilisés dans la formation, le calibrage du véhicule ainsi que les conditions de la piste réelle. La simulation est en outre uniquement une approximation (souvent sommaire) des conditions réelles. Sous l'influence de ces facteurs, la formation d'un modèle en simulation, son application aux conditions réelles et l'obtention de performances satisfaisantes représentent un réel défi.
Former un modèle pour obtenir de bonnes performances dans les conditions réelles implique de nombreuses itérations afin d'explorer la fonction de récompense, les espaces d'action, les hyperparamètres ainsi que l'évaluation en simulation et les tests dans un environnement réel. La dernière étape implique ce que l'on appelle le transfert simulation-to-realdu monde (sim2real) et peut sembler peu maniable.
Pour vous aider à relever les défis du transfert sim2real, prenez en compte les considérations suivantes :
-
Assurez-vous que le véhicule est bien calibré.
Le calibrage est important, car l'environnement simulé est probablement une représentation partielle de l'environnement réel. En outre, l'agent effectue une action en fonction de l'état actuel de la piste, tel que capturé par la caméra à chaque étape. Il ne voit pas assez loin pour planifier son itinéraire à une vitesse rapide. Pour palier à cela, la simulation impose des limites de vitesse et de direction. Pour garantir que le modèle formé fonctionne en conditions réelles, le véhicule doit être correctement calibré en fonction de ces limites et d'autres paramètres de simulation. Pour de plus amples informations sur le calibrage de votre véhicule, veuillez consulter Calibrez votre DeepRacer véhicule AWS.
-
Commencez par tester votre véhicule avec le modèle par défaut.
Votre DeepRacer véhicule AWS est livré avec un modèle pré-entraîné chargé dans son moteur d'inférence. Avant de tester votre propre modèle en conditions réelles, vérifiez que le véhicule fonctionne assez bien avec le modèle par défaut. Si ce n'est pas le cas, vérifiez la configuration de la piste physique. Si vous testez un modèle sur une piste physique qui n'a pas été correctement conçue, vous risquez d'obtenir de mauvaises performances. Dans ce cas, reconfigurez ou réparez votre piste avant de lancer ou de reprendre la phase de test.
Note
Lorsque vous utilisez votre DeepRacer véhicule AWS, les actions sont déduites en fonction du réseau de règles formé sans que la fonction de récompense soit invoquée.
-
Vérifiez que le modèle fonctionne en simulation.
Si votre modèle ne fonctionne pas correctement en conditions réelles, il est possible que le modèle ou la piste soit défectueux. Pour identifier les causes premières, vous devez d'abord évaluer le modèle en simulation afin de vérifier si l'agent simulé peut effectuer au moins une boucle sans sortir de la piste. Pour cela, vous pouvez inspecter la convergence des récompenses tout en observant la trajectoire de l'agent dans le simulateur. Si la récompense atteint le maximum lorsque l'agent simulé termine une boucle sans hésitation, le modèle est susceptible d'être performant.
-
Ne forcez pas la formation du modèle.
Si vous continuez la formation alors que le modèle effectue correctement et de façon cohérente les tours de piste en simulation, vous risquez d'obtenir un modèle trop précis. Un modèle formé de manière excessive ne fonctionnera pas correctement en conditions réelles, car il ne pourra pas gérer les différences, même mineures, entre la piste simulée et l'environnement réel.
-
Utilisez plusieurs modèles de différentes itérations.
Une session de formation standard génère différents modèles, allant de modèles manquant de précision à des modèles trop précis. Étant donné qu'il n'y a pas de critère de priorité pour déterminer le modèle idéal, vous devez choisir quelques modèles à partir du moment où l'agent termine un tour de piste dans le simulateur et effectue les tours de manière cohérente.
-
Commencez lentement et augmentez la vitesse progressivement pendant le test.
Lorsque vous testez le modèle déployé sur votre véhicule, commencez avec une faible valeur de vitesse maximale. Par exemple, vous pouvez définir la limite de la vitesse de test à moins de 10 % de la limite de la vitesse de formation. Augmentez ensuite progressivement la vitesse de test jusqu'à ce que le véhicule commence à se déplacer. La limite de la vitesse de test est définie lorsque vous calibrez le véhicule à l'aide de la console de commande de l'appareil. Si le véhicule roule trop vite, par exemple si la vitesse dépasse celles observées lors de l'entraînement en simulateur, le modèle a peu de chances de bien fonctionner sur piste réelle.
-
Testez un modèle en positionnant votre véhicule à différents points de départ.
Le modèle apprend à suivre un certain chemin en simulation et peut être sensible à sa position sur la piste. Il est conseillé de commencer les tests du véhicule avec différentes positions sur la piste, dans les limites de la piste (de la gauche au centre à la droite), afin de vérifier les performances du modèle à partir de certaines positions. La plupart des modèles ont tendance à garder le véhicule à proximité de l'un des côtés des lignes blanches. Pour vous aider à analyser la trajectoire du véhicule, tracez les positions du véhicule (x, y) étape par étape à partir de la simulation afin d'identifier les trajectoires pouvant être suivies par votre véhicule dans un environnement réel.
-
Commencez à tester sur une piste rectiligne.
Il est beaucoup plus facile de piloter sur une piste rectiligne que sur une piste courbe. Une piste rectiligne vous permettra d'éliminer rapidement les mauvais modèles. Si un véhicule ne peut pas suivre une piste rectiligne, cela signifie qu'il ne sera pas performant non plus sur une piste courbe.
-
Faites attention au comportement dans lequel le véhicule effectue un seul type d'actions.
Lorsque votre véhicule ne parvient à effectuer qu'un seul type d'action, par exemple en orientant le véhicule uniquement vers la gauche, le modèle est probablement trop ou pas assez ajusté. Avec des paramètres de modèle donnés, un trop grand nombre d'itérations de la formation peut entraîner un réglage trop précis. Un manque d'itérations peu générer un modèle manquant de précision.
-
Soyez attentif à la capacité du véhicule de corriger sa trajectoire le long de la bordure d'une piste.
Un modèle efficace permet au véhicule de s'auto-corriger lorsqu'il s'approche des bordures d'une piste. Les modèles les mieux formés ont cette capacité. Si le véhicule peut s'auto-corriger sur les deux bordures de la piste, le modèle est considéré plus fiable et de meilleure qualité.
-
Soyez attentifs aux comportements incohérents du véhicule.
Un modèle de politique représente une distribution de probabilité pour effectuer une action dans un état donné. Lorsque le modèle formé est chargé dans son moteur d'inférence, un véhicule choisit l'action la plus probable, étape par étape, en fonction des prescriptions du modèle. Si les probabilités d'action sont réparties uniformément, le véhicule peut effectuer toutes les actions dont la probabilité est égale ou très similaire. Cela entraîne un comportement de conduite erratique. Par exemple, lorsque le véhicule suit parfois une trajectoire rectiligne (par exemple, la moitié du temps) et qu'il effectue des virages inutiles à d'autres moments, le modèle est soit sous-équipé, soit trop ajusté.
-
Attention à un seul type de virage (à gauche ou à droite) effectué par le véhicule.
Si le véhicule effectue parfaitement les virages vers la gauche, mais ne parvient pas effectuer des virages vers la droite, ou s'il effectue uniquement des virages vers la droite et jamais de virages vers la gauche, vous devez calibrer ou recalibrer la direction de votre véhicule. Vous pouvez également essayer d'utiliser un modèle formé avec les paramètres proches des paramètres physiques testés.
-
Faites attention aux virages brusques du véhicule et à la sortie de la piste.
Si le véhicule suit correctement la trajectoire sur une grande partie de la piste, mais sort soudainement de la piste, cela est sans doute dû à des distractions dans l'environnement. Les distractions les plus courantes sont des reflets lumineux imprévus ou inattendus. Dans ce cas, utilisez des barrières autour de la piste ou d'autres solutions pour réduire les lumières éblouissantes.
