Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
AWS Lake Formation prend en charge la création de tables Apache Iceberg qui utilisent le format de données Apache Parquet dans AWS Glue Data Catalog les données résidant dans Amazon S3. Une table du catalogue de données est la définition des métadonnées qui représente les données d'un magasin de données. Par défaut, Lake Formation crée des tables Iceberg v2. Pour connaître la différence entre les tables v1 et v2, consultez la section Modifications de version de format
Apache Iceberg
Vous pouvez utiliser la console Lake Formation ou l'CreateTableopération décrite dans le AWS Glue API pour créer une table Iceberg dans le catalogue de données. Pour plus d'informations, consultez CreateTable action (Python : create_table).
Lorsque vous créez une table Iceberg dans le catalogue de données, vous devez spécifier le format de la table et le chemin du fichier de métadonnées dans Amazon S3 pour pouvoir effectuer des lectures et des écritures.
Vous pouvez utiliser Lake Formation pour sécuriser votre table Iceberg à l'aide d'autorisations de contrôle d'accès précises lorsque vous enregistrez l'emplacement des données Amazon S3 auprès de celui-ci. AWS Lake Formation Pour les données source dans Amazon S3 et les métadonnées qui ne sont pas enregistrées auprès de Lake Formation, l'accès est déterminé par IAM les politiques d'autorisation et les AWS Glue actions d'Amazon S3. Pour de plus amples informations, veuillez consulter Gestion des autorisations relatives à Lake Formation.
Note
Le catalogue de données ne prend pas en charge la création de partitions ni l'ajout de propriétés de table Iceberg.
Prérequis
Pour créer des tables Iceberg dans le catalogue de données et configurer les autorisations d'accès aux données de Lake Formation, vous devez remplir les conditions suivantes :
-
Autorisations requises pour créer des tables Iceberg sans les données enregistrées auprès de Lake Formation.
Outre les autorisations requises pour créer une table dans le catalogue de données, le créateur de la table doit disposer des autorisations suivantes :
s3:PutObjectsur la ressource arn:aws:s3 : :1 {} bucketName-
s3:GetObjectsur la ressource arn:aws:s3 : :1 {} bucketName -
s3:DeleteObjectsur la ressource arn:aws:s3 : :1 {} bucketName
-
Autorisations requises pour créer des tables Iceberg avec des données enregistrées auprès de Lake Formation :
Pour utiliser Lake Formation afin de gérer et de sécuriser les données de votre lac de données, enregistrez votre site Amazon S3 contenant les données pour les tables auprès de Lake Formation. Cela permet à Lake Formation de vendre des informations d'identification à AWS des services d'analyse tels qu'Athena, Redshift Spectrum et Amazon EMR pour accéder aux données. Pour plus d'informations sur l'enregistrement d'un site Amazon S3, consultezAjouter un emplacement Amazon S3 à votre lac de données.
Un directeur qui lit et écrit les données sous-jacentes enregistrées auprès de Lake Formation doit disposer des autorisations suivantes :
-
lakeformation:GetDataAccess -
DATA_LOCATION_ACCESSUn directeur qui possède des autorisations de localisation des données sur un emplacement possède également des autorisations de localisation sur tous les sites enfants.
Pour plus d'informations sur les autorisations de localisation des données, consultezContrôle d'accès aux données sous-jacent.
-
Pour activer le compactage, le service doit assumer un IAM rôle autorisé à mettre à jour les tables dans le catalogue de données. Pour plus de détails, consultez la section Conditions préalables à l'optimisation des tables.
Création d'une table Iceberg
Vous pouvez créer des tables Iceberg v1 et v2 à l'aide de la console Lake Formation ou AWS Command Line Interface comme indiqué sur cette page. Vous pouvez également créer des tables Iceberg à l'aide de AWS Glue la console ou AWS Glue crawler. Pour plus d'informations, consultez la section Data Catalog and Crawlers dans le manuel du AWS Glue développeur.
Pour créer une table Iceberg
Connectez-vous à la AWS Management Console console Lake Formation et ouvrez-la à l'adresse https://console.aws.amazon.com/lakeformation/
. Sous Catalogue de données, choisissez Tables, puis utilisez le bouton Créer une table pour spécifier les attributs suivants :
-
Nom de la table : entrez le nom de la table. Si vous utilisez Athena pour accéder aux tables, suivez ces conseils de dénomination dans le guide de l'utilisateur d'Amazon Athena.
-
Base de données : Choisissez une base de données existante ou créez-en une nouvelle.
-
Description : description de la table. Vous pouvez écrire une description vous aidant à comprendre le contenu de la table.
-
Format de tableau : pour Format de tableau, choisissez Apache Iceberg.
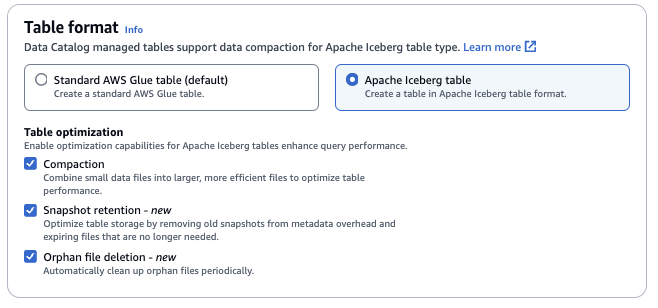
Optimisation des tables
-
Compaction : les fichiers de données sont fusionnés et réécrits pour supprimer les données obsolètes et consolider les données fragmentées dans des fichiers plus volumineux et plus efficaces.
Conservation des instantanés : les instantanés sont des versions horodatées d'une table Iceberg. Les configurations de conservation des instantanés permettent aux clients de définir la durée de conservation des instantanés et le nombre d'instantanés à conserver. La configuration d'un optimiseur de conservation des instantanés peut aider à gérer la charge de stockage en supprimant les anciens instantanés inutiles et leurs fichiers sous-jacents associés.
Suppression de fichiers orphelins — Les fichiers orphelins sont des fichiers qui ne sont plus référencés par les métadonnées de la table Iceberg. Ces fichiers peuvent s'accumuler au fil du temps, en particulier après des opérations telles que la suppression de tables ou l'échec de ETL tâches. L'activation de la suppression des fichiers orphelins permet AWS Glue d'identifier et de supprimer périodiquement ces fichiers inutiles, libérant ainsi de l'espace de stockage.
Pour plus d’informations, consultez Optimisation des tables Iceberg.
-
-
IAMrôle : pour exécuter le compactage, le service joue un IAM rôle en votre nom. Vous pouvez choisir un IAM rôle à l'aide de la liste déroulante. Assurez-vous que le rôle dispose des autorisations requises pour activer le compactage.
Pour en savoir plus sur les autorisations requises, consultez la section Conditions préalables à l'optimisation des tables.
-
Emplacement : Spécifiez le chemin d'accès au dossier dans Amazon S3 qui stocke la table de métadonnées. Iceberg a besoin d'un fichier de métadonnées et d'un emplacement dans le catalogue de données pour pouvoir effectuer des lectures et des écritures.
-
Schéma : choisissez Ajouter des colonnes pour ajouter des colonnes et les types de données des colonnes. Vous avez la possibilité de créer une table vide et de mettre à jour le schéma ultérieurement. Le catalogue de données prend en charge les types de données Hive. Pour plus d'informations, consultez la section Types de données Hive
. Iceberg vous permet de faire évoluer le schéma et la partition après avoir créé la table. Vous pouvez utiliser les requêtes Athena pour mettre à jour le schéma de table et les requêtes Spark
pour mettre à jour les partitions.
-
