サポート終了通知: 2025 AWS 年 10 月 31 日、 は Amazon Lookout for Vision のサポートを終了します。2025 年 10 月 31 日以降、Lookout for Vision コンソールまたは Lookout for Vision リソースにアクセスできなくなります。詳細については、このブログ記事
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Lookout for Vision について
Amazon Lookout for Vision を使えば、以下のように、工業製品の視覚的欠陥を正確かつ大規模に見つけることができます:
-
損傷部分の検出 — 製造や組み立ての過程で、製品の表面品質、色、形状の損傷を特定します。
-
欠落部品の特定 — 物体の非適用、存在、配置の情報に基づいて欠落している部品を特定します。たとえば、プリント回路基板で欠けているコンデンサなどです。
-
プロセス問題の発見 — シリコンウェーハの同じ箇所に繰り返し傷がつくなど、パターンが繰り返される欠陥を検出します。
Lookout for Vision により、画像内の異常の存在を予測するコンピュータービジョンモデルを作成できます。Amazon Lookout for Vision がモデルのトレーニングとテストに使用する画像を提供してください。Amazon Lookout for Vision は、トレーニング済みモデルの評価と改善に使用できるメトリクスを提供しています。トレーニング済みモデルを AWS クラウドでホストしたり、エッジデバイスにデプロイしたりできます。簡単な API オペレーションにより、モデルの作成する予測が返されます。
モデルを作成、評価、使用するための一般的なワークフローは次のとおりです:
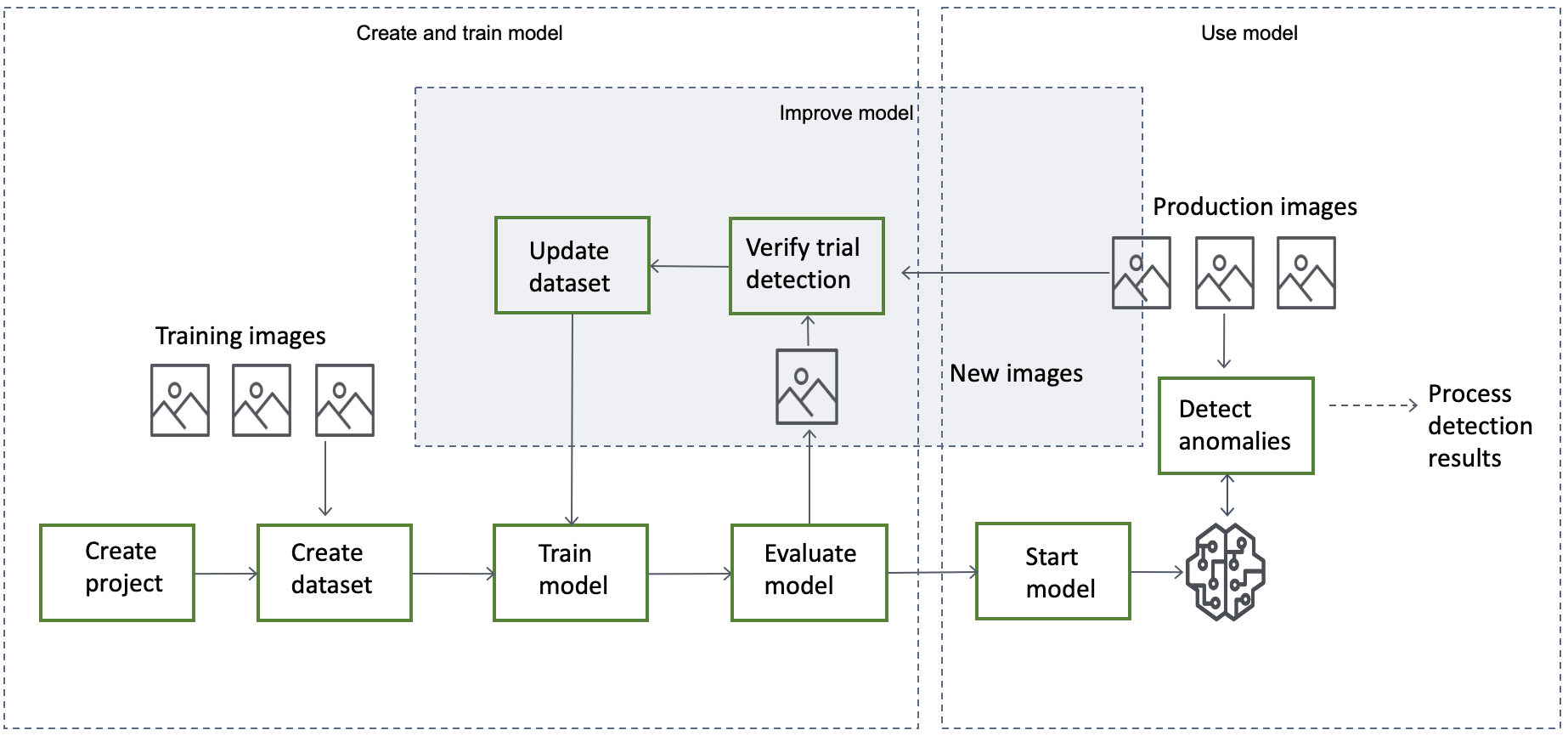
モデルタイプを選択する
モデルを作成する前に、必要なモデルのタイプを決定する必要があります。画像分類と画像セグメンテーションという 2 タイプのモデルを作成できます。お客様はユースケースに基づいて作成するモデルのタイプを決定します。
画像分類モデル
画像に異常があるかどうかを確認するだけでよく、その位置を知る必要がない場合は、画像分類モデルを作成します。画像分類モデルは、画像に異常があるかどうかを予測します。予測には、予測の精度に対するモデルの信頼度が含まれます。このモデルは、画像上で見つかった異常の位置に関する情報を提供しません。
画像セグメンテーションモデル
傷の場所など、異常箇所を知る必要がある場合は、画像セグメンテーションモデルを作成します。Amazon Lookout for Vision モデルはセマンティックセグメンテーションを使用して、異常のタイプ (傷や部分的欠落など) が存在する画像でのピクセルを識別します。
注記
セマンティックセグメンテーションモデルはさまざまなタイプの異常を検出します。個々の異常に関するインスタンス情報は提供されません。たとえば、画像に 2 つのへこみが含まれている場合、Lookout for Vision は、単一のエンティティ内で両方のへこみに関する情報を返し、へこみの異常タイプを示します。
Amazon Lookout for Vision のセグメンテーションモデルでは、次のことが予測されます:
分類
モデルは、分析された画像の分類 (正常/異常) を返し、そこには予測でのモデルの信頼度が含まれます。分類情報はセグメンテーション情報とは別に計算されるため、それらの関係は想定しないでください。
セグメンテーション
モデルは、画像上で異常が発生している、ピクセルを示す画像マスクを返します。データセット内の異常ラベルに割り当てられた色に従って、さまざまなタイプの異常が色分けされます。異常ラベルは異常のタイプを表します。たとえば、次の画像内の青いマスクは、自動車で見つかった異常として傷の位置を示しています。

モデルはマスク内の各異常ラベルのカラーコードを返します。また、モデルは異常ラベルの画像の被覆率も返します。
Lookout for Vision セグメンテーションモデルにより、さまざまな基準を使用してモデルからの分析結果を分析できます。例:
-
異常箇所 — 異常箇所を知る必要がある場合は、セグメンテーション情報を利用して、異常をカバーするマスクを確認してください。
-
異常のタイプ — セグメンテーション情報を使用して、許容数を超える異常のタイプを画像が含んでいるかどうかを判断します。
-
対象範囲 — セグメンテーション情報を使用して、ある異常タイプが画像の許容範囲を超えているかどうかを判断します。
-
画像分類 — 異常箇所を知る必要がない場合は、分類情報を使用して画像に異常があるかどうかを判断します。
サンプルコードについては、「画像内の異常を検出する」を参照してください。
必要なモデルのタイプを決定したら、モデルを管理するためのプロジェクトとデータセットを作成します。ラベルを使用すると、画像を通常または異常に分類できます。ラベルは、マスクや異常タイプなどのセグメンテーション情報も識別します。データセット内の画像にどのようにラベルを付けるかによって、Lookout for Vision が作成するモデルのタイプが決まります。
画像セグメンテーションモデルのラベリングは、画像分類モデルのラベリングよりも複雑です。セグメンテーションモデルをトレーニングするには、トレーニング画像を正常または異常として分類する必要があります。また、異常画像ごとに異常マスクと異常タイプを定義する必要があります。分類モデルでは、トレーニング画像が正常か異常かを識別するだけで済みます。
モデルを作成する
モデルを作成するステップは、以下のように、プロジェクトの作成、データセットの作成、モデルのトレーニングとなります:
プロジェクトを作成する
作成したデータセットとモデルを管理するためのプロジェクトを作成します。プロジェクトは、単一タイプの機械部品の異常を検出するなど、単一のユースケースに使用する必要があります。
プロジェクトの概要はダッシュボードで確認できます。詳細については、「Amazon Lookout for Vision ダッシュボードを使用する」を参照してください。
詳細情報: 「プロジェクトを作成する」を参照してください。
データセットを作成する
Amazon Lookout for Vision でモデルをトレーニングするには、ユースケースに合った通常のオブジェクトと異常なオブジェクトの画像が必要です。これらの画像はデータセットで提供します。
データセットとは、複数の画像とそれらの画像を説明するラベルのセットのことです。画像では、異常が発生する単一タイプのオブジェクトが表されている必要があります。詳細については、「データセットの画像の準備」を参照してください。
Amazon Lookout for Vision では、シングルデータセットを使用するプロジェクトを作成したり、個別のトレーニングデータセットとテストデータセットを持つプロジェクトを作成できます。トレーニング、テスト、およびパフォーマンスチューニングをより細かく制御する必要がある場合を除き、単一のデータセットプロジェクトを使用することをお勧めします。
データセットは、画像をインポートして作成します。画像のインポート方法によっては、画像にラベルが付けられる場合もあります。ラベルを付けない場合は、コンソールを使用して画像にラベルを付けます。
画像のインポート
Lookout for Vision コンソールでデータセットを作成した場合、次のいずれかの方法で画像をインポートできます:
-
ローカルコンピュータから画像をインポートします。画像はラベル付けされません。
-
S3 バケットから画像をインポートします。Amazon Lookout for Vision では、画像を含むフォルダー名を使用して画像を分類できます。
normalを正常な画像に使用します。anomalyを異常な画像に使用します。セグメンテーションラベルを自動的に割り当てることはできません。 -
Amazon SageMaker Ground Truth マニフェストファイルをインポートします。マニフェストファイル内の画像はラベル付けされます。独自のマニフェストファイルを作成してインポートできます。画像が多い場合は、SageMaker Ground Truth ラベリングサービスの使用を検討してください。次に、Amazon SageMaker Ground Truth ジョブから出力マニフェストファイルをインポートします。
画像のラベリング
ラベルは、データセット内の画像について記述します。ラベルは、画像が正常か異常かを指定します (分類)。ラベルは画像上の異常箇所も記述します (セグメンテーション)。
画像にラベルが付いていない場合は、コンソールを使用してラベルを付けることができます。
データセット内の画像に割り当てるラベルによって、Lookout for Vision が作成するモデルのタイプが決まります:
画像分類
画像分類モデルを作成するには、Lookout for Vision コンソールを使用して、データセット内の画像を正常または異常に分類します。
CreateDataset オペレーションを使用して、分類情報を含むマニフェストファイルからデータセットを作成することもできます。
画像セグメンテーション
画像セグメンテーションモデルを作成するには、Lookout for Vision コンソールを使用して、データセット内の画像を正常または異常として分類します。また、画像上の異常領域 (存在する場合) にはピクセルマスクを指定し、個々の異常マスクには異常ラベルを指定します。
また、この CreateDataset オペレーションを使用して、セグメンテーションと分類の情報を含むマニフェストファイルからデータセットを作成することもできます。
プロジェクトに個別のトレーニングデータセットとテストデータセットがある場合、Lookout for Vision はトレーニングデータセットを使用してモデルタイプの学習と決定行います。テストデータセットの画像には同じ方法でラベルを付ける必要があります。
詳細情報: 「データセットの作成」を参照してください。
モデルをトレーニングする
トレーニングは、モデルを作成し、画像内の異常の存在を予測するようにトレーニングします。モデルをトレーニングするたびに、モデルの新しいバージョンが作成されます。
トレーニングのスタート時に、Amazon Lookout for Vision は、モデルのトレーニングに最適なアルゴリズムを選択します。モデルはトレーニングされ、テストされます。Amazon Lookout for Vision コンソールの開始 で、単一データセットプロジェクトのトレーニングを行う場合、データセットは内部で分割され、トレーニングデータセットとテストデータセットが作成されます。個別のトレーニングデータセットとテストデータセットを持つプロジェクトを作成することもできます。この構成では、Amazon Lookout for Vision はトレーニングデータセットを使用してモデルをトレーニングし、テストデータセットでモデルをテストします。
重要
課金はモデルのトレーニングに成功するまでの時間に対して行われます。
詳細情報:モデルのトレーニング。
モデルの評価
テスト中に作成されたパフォーマンスメトリックを使用して、モデルのパフォーマンスを評価します。
パフォーマンスメトリクスにより、トレーニングしたモデルのパフォーマンスをより適切に理解し、実運用で使用する準備ができたかどうかを判断できます。
詳細: 「モデルの改善」を参照してください。
パフォーマンスメトリクスの結果、改善が必要な場合は、新しい画像で検出タスクを試行することにより、トレーニングデータを追加することができます。タスクが完了したら、結果を確認し、検証済みの画像をトレーニングデータセットに追加できます。または、新しいトレーニング画像をデータセットに直接追加することもできます。次に、モデルを再トレーニングし、パフォーマンスメトリクスを再チェックします。
詳細: 「トライアル検出タスクでモデルを検証する」を参照してください。
モデルを使用する
AWS クラウドでモデルを使用する前に、StartMode オペレーションでモデルを開始します。コンソールからモデルの StartModel CLI コマンドを取得できます。
詳細情報:モデルの開始。
トレーニング済みの Amazon Lookout for Vision モデルは、入力された画像に正常なコンテンツまたは異常なコンテンツが含まれているかどうかを予測します。モデルがセグメンテーションモデルの場合、予測には異常が見つかったピクセルをマークする異常マスクが含まれます。
モデルで予測を行うには、DetectAnomalies オペレーションを実行し、ローカルコンピュータから入力画像を渡します。DetectAnomalies を呼び出す CLI コマンドは、コンソールから取得することができます。
詳細情報:画像内の異常を検出する。
重要
モデルの稼働時間に応じて課金されます。
モデルを使用しなくなった場合は、StopModel オペレーションを使用してモデルを停止します。CLI コマンドは、コンソールから取得できます。
詳細情報:モデルを停止する。
モデルをエッジデバイスで使用する
Lookout for Vision モデルは AWS IoT Greengrass Version 2 コアデバイスで使用できます。
詳細: 「エッジデバイスでの Amazon Lookout for Vision モデルの使用」を参照してください。
ダッシュボードを使用する
ダッシュボードを使用して、すべてのプロジェクトの概要と個々のプロジェクトの概要情報を取得できます。
詳細: 「ダッシュボードを使用する」を参照してください。
