翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
カスタムデータ識別子の設定オプション
カスタムデータ識別子を使用して、Amazon Simple Storage Service (Amazon S3) 内の機密データを検出するためのカスタム基準を定義できます。Amazon Macie が提供するマネージドデータ識別子を補足し、組織の特定のシナリオ、知的財産、または専有データを反映する機密データを検出できます。
各カスタムデータ識別子では、識別子によって生成される検出結果の検出基準と重要度設定 (オプション) を指定します。検出基準では、S3 オブジェクト内で一致させるテキストパターンを定義する正規表現を指定します。この基準では、結果を絞り込む文字シーケンスと近接ルールを指定することもできます。重要度設定では、結果に割り当てる重要度を指定します。重要度は、識別子の検出基準に一致するテキストの出現回数に基づいて指定できます。
トピック
検出基準
各カスタムデータ識別子を作成するときに、一致するテキストパターンを定義する正規表現 (regex) を指定します。また、単語やフレーズなどの文字シーケンス、および結果を絞り込む近接ルールを指定することもできます。文字シーケンスは、正規表現に一致するテキストに近接する必要がある単語またはフレーズである「キーワード」、または結果から除外する単語またはフレーズである「無視する単語」になります。
正規表現では、Amazon Macie は、Perl 互換正規表現 (PCRE) ライブラリ
-
バックリファレンス
-
キャプチャグループ
-
条件付きパターン
-
埋め込みコード
-
グローバルパターンフラグ (
/i、/m、および/xなど) -
再帰的なパターン
-
正と負のルックビハインドおよびルックアヘッドのゼロ幅アサーション (
?=、?!、?<=、および?<!など)。
正規表現には最大 512 文字を含めることができます。
カスタムデータ識別子に効果的な正規表現パターンを作成するには、以下のヒントとレコメンデーションにも注意してください。
-
行の先頭または末尾ではなく、ファイルの先頭または末尾にパターンが表示されることを想定している場合にのみ、アンカー (
^または$) を使用します。 -
パフォーマンス上の理由から、Macie は有界リピートグループのサイズを制限します。例えば、
\d{100,1000}は Macie ではコンパイルしません。この機能に近づくには、\d{100,}のようなオープンエンドリピートを使用できます。 -
パターンの一部で大文字と小文字を区別しないようにするには、
/iフラグの代わりに(?i)設定を使用します。 -
プレフィックスや交代を手動で最適化する必要はありません。たとえば、
/hello|hi|hey/から/h(?:ello|i|ey)/に変更してもパフォーマンスは向上しません。 -
パフォーマンス上の理由から、Macie はワイルドカードの繰り返し数を制限します。例えば、
a*b*a*は Macie ではコンパイルしません。
不正な形式または長時間実行される式から保護するために、Macie は、カスタムデータ識別子を作成する際、サンプルテキストのコレクションに対して正規表現パターンを自動的にテストします。正規表現に問題がある場合、Macie は問題を説明するエラーを返します。
正規表現に加えて、オプションで文字シーケンスと近接ルールを指定して結果を絞り込むこともできます。
- キーワード
-
これらは、正規表現パターンに一致するテキストの近接内にある必要がある文字シーケンスです。近接要件は、S3 オブジェクトのストレージ形式またはファイルタイプによって異なります。
-
構造化列データ – Macie は、テキストが正規表現パターンに一致し、キーワードがテキストを保存するフィールドまたは列の名前にある場合、または同じフィールドまたはセル値内のキーワードの最大一致距離の先頭と範囲内にある場合、結果を含めます。これは、Microsoft Excel ワークブック、CSV ファイル、および TSV ファイルに当てはまります。
-
構造化レコードベースのデータ – Macie は、テキストが正規表現パターンと一致し、テキストがキーワードの最大一致距離内にある場合、結果を含めます。キーワードは、テキストを保存するフィールドまたは配列へのパス内の要素の名前に含めるか、またはテキストを保存するフィールドまたは配列内の同じ値の前にくるかその一部にすることができます。これは Apache Avro オブジェクトコンテナ、Apache Parquet ファイル、JSON ファイル、および JSON Lines ファイルに当てはまります。
-
非構造化データ – テキストが正規表現パターンに一致し、テキストの前にキーワードがあり、かつテキストがキーワードの最大一致距離内にある場合、Macie は結果をレポートします。これは、Adobe ポータブルドキュメント形式ファイル、Microsoft Word ドキュメント、E メールメッセージ、および CSV、JSON、JSON Lines、および TSV ファイル以外の非バイナリテキストファイルに当てはまります。これには、これらのタイプのファイルに含まれるテーブルなどの構造化データが含まれます。
最大 50 個のキーワードを指定できます。各キーワードには、3~90 の UTF-8 文字を含めることができます。キーワードでは、大文字と小文字が区別されません。
-
- Maximum match distance (最大一致距離)
-
これは文字ベースのキーワードの近接ルールです。Macie はこの設定を使用して、キーワードが正規表現パターンに一致するテキストの前に置かれているかどうかを判断します。この設定は、キーワード全体の終わりと正規表現パターンに一致するテキストの終わりの間に存在できる最大文字数を定義します。Macie は、テキストが次の場合、結果を含めます。
-
正規表現パターンに一致する
-
少なくとも 1 つのキーワードが完了した後に出現する
-
キーワードから指定された距離内に出現する
それ以外の場合、Macie は結果からテキストを除外します。
1~300 文字の距離を指定できます。デフォルトの距離は 50 文字です。最良の結果を得るには、この距離が正規表現が検出するように設計されているテキストの最小文字数よりも大きくなければなりません。テキストの一部のみがキーワードの最大一致距離内にある場合、Macie はそのテキストを結果に含めません。
-
- 無視する単語
-
これらは、結果から除外する特定の文字シーケンスです。テキストが正規表現パターンと一致しても無視ワードが含まれている場合、Macie は結果にそれを含めません。
無視する単語を 10 個まで指定できます。無視する単語には、4~90 の UTF-8 文字を含めることができます。無視する単語では、大文字と小文字が区別されます。
注記
カスタムデータ識別子を作成する前に、サンプルデータを使用して検出基準をテストおよび改良することを強くお勧めします。カスタムデータ識別子は機密データ検出ジョブで使用されるため、作成後にカスタムデータ識別子を変更することはできません。これにより、実施するデータプライバシーと保護の監査または調査に関する機密データの調査結果と検出結果のイミュータブルな履歴を確実に保持できます。
Amazon Macie コンソールまたは Amazon Macie API を使用して、検出基準をテストできます。コンソールを使用して基準をテストするには、カスタムデータ識別子の作成中に [評価] セクションのオプションを使用します。プログラムで基準をテストするには、Amazon Macie API の TestCustomDataIdentifier オペレーションを使用します。を使用している場合は AWS Command Line Interface、test-custom-data-identifier コマンドを実行して基準をテストします。
キーワードが機密データの検索や誤検出の回避にどのように役立つかについては、以下の動画をご覧ください。
検出結果の重要度設定
カスタムデータ識別子を作成するときに、識別子が生成する機密データの検出結果のカスタム重要度設定も指定できます。デフォルトでは、Amazon Macie はカスタムデータ識別子が生成するすべての検出結果に中程度の重要度を割り当てます。S3 オブジェクトに検出基準と一致するテキストが少なくとも 1 つ含まれている場合、Macie は検出結果に自動的に中程度の重大度を割り当てます。
カスタム重要度設定により、検出基準に一致するテキストの出現回数に基づいて、割り当てる重要度を指定できます。この場合、低 (最小重要度)、中、および 高 (最大重要度) の最大 3 つの重要度レベルで頻度しきい値を定義できます。頻度しきい値は、指定された重要度で結果を生成するために S3 オブジェクトに存在する必要がある一致の最小数です。しきい値を超える値を指定する場合、しきい値は重要度で昇順 (低 から 高 に移動) である必要があります。
例えば、次の図は 3 つの頻度しきい値を指定する重要度設定 (Macie がサポートする重要度レベルごとに 1 つ) を示しています。
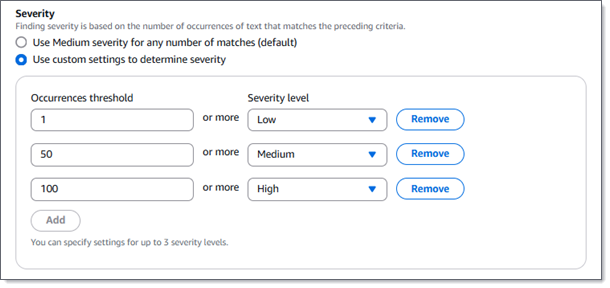
次のテーブルに、カスタムデータ識別子が生成する結果の重要度を示します。
| 頻度しきい値 | 重要度レベル | 結果 |
|---|---|---|
| 1 | 低 | S3 オブジェクトに、検出基準に一致するテキストの出現が 1~49 回含まれている場合、Macie はオブジェクトで低重要度の結果を作成します。 |
| 50 | 中 | S3 オブジェクトに、検出基準に一致するテキストの出現が 50~99 回含まれている場合、Macie はオブジェクトで中重要度の結果を作成します。 |
| 100 | 高 | S3 オブジェクトに、検出基準に一致するテキストの出現が 100 回以上含まれている場合、Macie はオブジェクトで高重要度の結果を作成します。 |
重要度設定を使用して、結果を作成するかどうかを指定することもできます。S3 オブジェクトに含まれる出現の回数が最小頻度しきい値よりも少ない場合、Macie は結果を作成しません。
