기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Step Functions의 대규모 병렬 워크로드를 위해 분산 모드에서 Map 상태 사용
상태 관리 및 데이터 트랜스포밍
변수를 사용하여 상태 간 데이터 전달과 JSONata를 사용하여 데이터 트랜스포밍에 대해 알아봅니다.
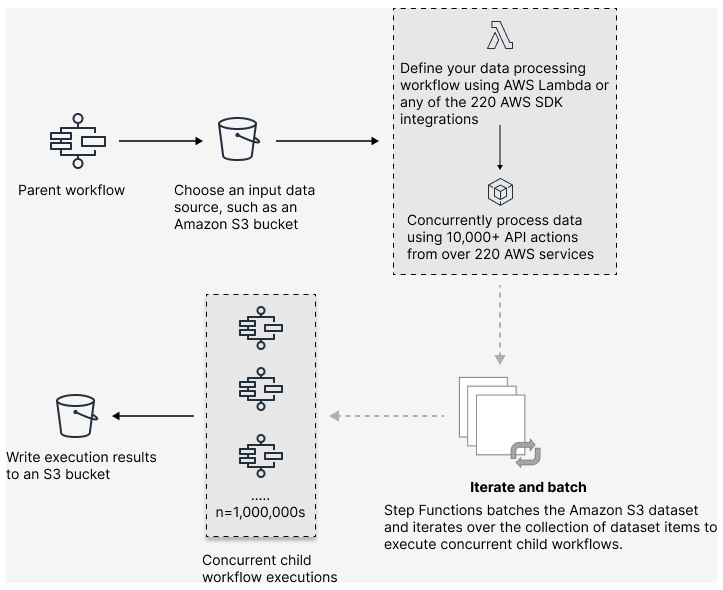
Step Functions를 사용하면 대규모 병렬 워크로드를 오케스트레이션하여 반정형 데이터의 온디맨드 처리와 같은 작업을 수행할 수 있습니다. 이러한 병렬 워크로드를 사용하면 Amazon S3에 저장된 대규모 데이터 소스를 동시에 처리할 수 있습니다. 예를 들어 대량의 데이터가 포함된 단일 JSON 또는 CSV 파일을 처리할 수 있습니다. 또는 대규모 Amazon S3 객체 집합을 처리할 수 있습니다.
워크플로에 대규모 병렬 워크로드를 설정하려면 분산 모드에 Map 상태를 포함합니다. Map 상태는 데이터세트의 항목을 동시에 처리합니다. Distributed로 설정된 Map 상태를 Distributed Map 상태라고 합니다. 분산 모드에서 Map 상태를 사용하면 동시 처리가 가능해집니다. 분산 모드에서 Map 상태는 데이터세트의 항목을 하위 워크플로 실행이라고 하는 반복으로 처리합니다. 병렬로 실행할 수 있는 하위 워크플로 실행 수를 지정할 수 있습니다. 각 하위 워크플로 실행에는 상위 워크플로와 별개인 자체 실행 내역이 있습니다. 지정하지 않는 경우 Step Functions는 병렬 하위 워크플로 실행 10,000개를 동시에 실행합니다.
다음 그림에서는 워크플로에서 대규모 병렬 워크로드를 설정하는 방법을 설명합니다.
워크숍에서 학습
Step Functions 및 Lambda와 같은 서버리스 기술이 관리 및 규모 조정을 간소화하고, 획일적인 작업을 오프로드하며, 대규모 분산 데이터 처리의 문제를 해결하는 방법을 알아봅니다. 그 과정에서 높은 동시성 처리를 위해 분산 맵으로 작업하게 됩니다. 또한 이 워크숍에서는 워크플로를 최적화하기 위한 모범 사례와 클레임 처리, 취약성 스캔 및 Monte Carlo 시뮬레이션에 대한 실제 사용 사례를 제공합니다.
이 주제의 내용
주요 용어
- 분산 모드
-
Map 상태 처리 모드입니다. 이 모드에서는 각
Map상태 반복은 하위 워크플로 실행으로 실행되므로 동시성이 높습니다. 각 하위 워크플로 실행에는 상위 워크플로의 실행 내역과 별개인 자체 실행 내역이 있습니다. 이 모드에서 대규모 Amazon S3 데이터 소스의 입력을 읽을 수 있습니다. - Distributed Map 상태
-
분산 처리 모드로 설정된 Map 상태입니다.
- 맵 워크플로
Map상태가 실행하는 일련의 단계입니다.- 상위 워크플로
-
Distributed Map 상태가 하나 이상 포함된 워크플로입니다.
- 하위 워크플로 실행
-
Distributed Map 상태 반복입니다. 하위 워크플로 실행에는 상위 워크플로의 실행 내역과 별개인 자체 실행 내역이 있습니다.
- 맵 실행
-
분산 모드에서
Map상태를 실행하면 Step Functions에서 맵 실행 리소스를 만듭니다. 맵 실행은 Distributed Map 상태가 시작하는 일련의 하위 워크플로 실행과 이러한 실행을 제어하는 런타임 설정을 의미합니다. Step Functions에서 Amazon 리소스 이름(ARN)을 맵 실행에 할당합니다. Step Functions 콘솔에서 맵 실행을 검사할 수 있습니다.DescribeMapRunAPI 작업을 간접적으로 호출할 수도 있습니다.맵 실행의 하위 워크플로 실행은 지표를 CloudWatch다음으로 내보냅니다. 이러한 지표에는 다음 형식의 레이블이 지정된 상태 머신 ARN이 있습니다.
arn:partition:states:region:account:stateMachine:stateMachineName/MapRunLabel or UUID자세한 내용은 맵 실행 보기 단원을 참조하십시오.
Distributed Map 상태 정의 예제(JSONPath)
다음 조건 조합을 모두 충족하는 대규모 병렬 워크로드를 오케스트레이션해야 하는 경우 분산 모드에서 Map 상태를 사용합니다.
데이터세트 크기가 256KiB를 초과합니다.
워크플로의 실행 이벤트 내역 항목이 25,000개를 초과합니다.
동시 반복을 40회 넘게 실행해야 합니다.
다음 Distributed Map 상태 정의 예제에서는 데이터세트를 Amazon S3 버킷에 저장된 CSV 파일로 지정합니다. 또한 CSV 파일의 각 행에서 데이터를 처리하는 Lambda 함수를 지정합니다. 이 예제에서는 CSV 파일을 사용하므로 CSV 열 헤더 위치도 지정합니다. 이 예제의 전체 상태 머신 정의를 보려면 Distributed Map을 사용하여 대규모 CSV 데이터 복사 자습서를 참조하세요.
{
"Map": {
"Type": "Map",
"ItemReader": {
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
},
"Resource": "arn:aws:states:::s3:getObject",
"Parameters": {
"Bucket": "amzn-s3-demo-bucket",
"Key": "csv-dataset/ratings.csv"
}
},
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "LambdaTask",
"States": {
"LambdaTask": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:us-east-2:account-id:function:processCSVData"
},
"End": true
}
}
},
"Label": "Map",
"End": true,
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Parameters": {
"Bucket": "amzn-s3-demo-destination-bucket",
"Prefix": "csvProcessJobs"
}
}
}
}Distributed Map을 실행할 수 있는 권한
워크플로에 Distributed Map 상태가 포함된 경우 Step Functions에는 상태 머신 역할에서 Distributed Map 상태의 StartExecution API 작업을 호출할 수 있는 적절한 권한이 있어야 합니다.
다음 IAM 정책 예제에서는 Distributed Map 상태를 실행하는 데 필요한 최소 권한을 상태 머신 역할에 부여합니다.
참고
stateMachineNamearn:aws:states:입니다.region:account-id:stateMachine:mystateMachine
-
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "states:StartExecution" ], "Resource": [ "arn:aws:states:us-east-1:123456789012:stateMachine:myStateMachineName" ] }, { "Effect": "Allow", "Action": [ "states:DescribeExecution" ], "Resource": "arn:aws:states:us-east-1:123456789012:execution:myStateMachineName:*" } ] }
또한 Amazon S3 버킷과 같이 Distributed Map 상태에서 사용되는 AWS 리소스에 액세스하는 데 필요한 최소 권한이 있는지 확인해야 합니다. 자세한 내용은 Distributed Map 상태를 사용하기 위한 IAM 정책 단원을 참조하세요.
Distributed Map 상태 필드
워크플로에서 Distributed Map 상태를 사용하려면 다음 필드를 하나 이상을 지정합니다. 일반 상태 필드 외에 다음 필드를 지정합니다.
Type(필수)-
상태 유형을 설정합니다(예:
Map). ItemProcessor(필수)-
Map상태 처리 모드와 정의를 지정하는 다음 JSON 객체를 포함합니다.-
ProcessorConfig- 다음 하위 필드를 사용하여 항목 처리 모드를 지정하는 JSON 객체입니다.-
Mode- 분산 모드에서Map상태를 사용하려면DISTRIBUTED로 설정합니다.주의
분산 모드는 표준 워크플로에서는 지원되지만 Express 워크플로에서는 지원되지 않습니다.
-
ExecutionType- 맵 워크플로 실행 유형을 STANDARD 또는 EXPRESS로 지정합니다.Mode하위 필드에DISTRIBUTED를 지정한 경우 이 필드를 제공해야 합니다. 워크플로 유형에 대한 자세한 내용은 Step Functions에서 워크플로 유형 선택 섹션을 참조하세요.
-
StartAt- 워크플로의 첫 번째 상태를 나타내는 문자열을 지정합니다. 이 문자열은 대소문자를 구분하며 상태 객체 중 하나의 이름과 일치해야 합니다. 이 상태는 데이터세트의 항목마다 가장 먼저 실행됩니다.Map상태에 제공하는 모든 실행 입력은 먼저StartAt상태에 전달됩니다.States- 쉼표로 구분된 상태 집합이 포함된 JSON 객체입니다. 이 객체에서 Map workflow를 정의합니다.
-
ItemReader-
데이터세트와 해당 위치를 지정합니다.
Map상태는 지정된 데이터세트에서 입력 데이터를 수신합니다.분산 모드에서는 이전 상태에서 전달된 JSON 페이로드나 대규모 Amazon S3 데이터 소스를 데이터세트로 사용할 수 있습니다. 자세한 내용은 ItemReader(맵) 단원을 참조하십시오.
Items(선택 사항, JSONata만 해당)-
배열 또는 객체로 평가되어야 하는 JSON 배열, JSON 객체 또는 JSONata 표현식입니다.
ItemsPath(선택 사항, JSONPath만 해당)-
JsonPath
구문을 사용하여 참조 경로를 지정하여 항목 배열이 포함된 JSON 노드 또는 상태 입력 내에 키-값 페어가 있는 객체를 선택합니다. 분산 모드에서는 이전 단계의 JSON 배열 또는 객체를 상태 입력으로 사용하는 경우에만이 필드를 지정합니다. 자세한 내용은 ItemsPath(Map, JSONPath만 해당) 단원을 참조하십시오.
ItemSelector(선택 사항, JSONPath만 해당)-
개별 데이터세트 항목 값을 각
Map상태 반복에 전달하기 전에 재정의합니다.이 필드에서 키-값 페어 컬렉션이 포함된 유효한 JSON 입력을 지정합니다. 이러한 페어는 상태 머신 정의에서 정의한 정적 값, 경로를 사용하여 상태 입력에서 선택한 값 또는 컨텍스트 객체에서 액세스한 값 중 하나일 수 있습니다. 자세한 내용은 ItemSelector(맵) 단원을 참조하십시오.
ItemBatcher(선택 사항)-
데이터세트 항목을 일괄 처리하려면 지정합니다. 그러면 각 하위 워크플로 실행에서 이러한 항목 배치를 입력으로 수신합니다. 자세한 내용은 ItemBatcher(맵) 단원을 참조하십시오.
MaxConcurrency(선택 사항)-
동시에 실행할 수 있는 하위 워크플로 실행 수를 지정합니다. 인터프리터는 병렬 하위 워크플로 실행을 지정된 수까지만 허용합니다. 동시성 값을 지정하지 않거나 0으로 설정하면 Step Functions는 동시성을 제한하지 않고 병렬 하위 워크플로 실행 10,000개를 실행합니다. JSONata 상태에서 정수로 평가되는 JSONata 표현식을 지정할 수 있습니다.
참고
병렬 하위 워크플로 실행에 대해 더 높은 동시성 제한을 지정할 수 있지만와 같은 다운스트림 AWS 서비스의 용량을 초과하지 않는 것이 좋습니다 AWS Lambda.
MaxConcurrencyPath(선택 사항, JSONPath만 해당)-
참조 경로를 사용하여 상태 입력에서 동적으로 최대 동시성 값을 제공하려면
MaxConcurrencyPath를 사용합니다. 확인되면 참조 경로에서 값이 음수가 아닌 정수인 필드를 선택해야 합니다.참고
Map상태에는MaxConcurrency및MaxConcurrencyPath모두 포함될 수 없습니다. ToleratedFailurePercentage(선택 사항)-
맵 실행에서 허용할 수 있는 실패 항목 비율을 정의합니다. 이 비율을 초과하면 맵 실행이 자동으로 실패합니다. Step Functions는 실패하거나 시간 초과된 총 항목 수를 총 항목 수로 나눈 결과로 실패 항목 백분율을 계산합니다. 0~100 범위의 값을 지정해야 합니다. 자세한 내용은 Step Functions에서 분산 맵 상태의 실패 임계값 설정 단원을 참조하십시오.
JSONata 상태에서 정수로 평가되는 JSONata 표현식을 지정할 수 있습니다.
ToleratedFailurePercentagePath(선택 사항, JSONPath만 해당)-
참조 경로를 사용하여 상태 입력에서 허용 실패 백분율 값을 동적으로 제공하려면
ToleratedFailurePercentagePath를 사용합니다. 확인되면 참조 경로에서 값이 0~100인 필드를 선택해야 합니다. ToleratedFailureCount(선택 사항)-
맵 실행에서 허용할 수 있는 실패 항목 수를 정의합니다. 이 수를 초과하면 맵 실행이 자동으로 실패합니다. 자세한 내용은 Step Functions에서 분산 맵 상태의 실패 임계값 설정 단원을 참조하십시오.
JSONata 상태에서 정수로 평가되는 JSONata 표현식을 지정할 수 있습니다.
ToleratedFailureCountPath(선택 사항, JSONPath만 해당)-
참조 경로를 사용하여 상태 입력에서 허용 실패 계수 값을 동적으로 제공하려면
ToleratedFailureCountPath를 사용합니다. 확인되면 참조 경로에서 값이 음수가 아닌 정수인 필드를 선택해야 합니다. Label(선택 사항)-
Map상태를 고유하게 식별하는 문자열입니다. 맵 실행마다 Step Functions는 레이블을 맵 실행 ARN에 추가합니다. 다음은demoLabel이라는 사용자 지정 레이블이 있는 맵 실행 ARN의 예제입니다.arn:aws:states:region:account-id:mapRun:demoWorkflow/demoLabel:3c39a231-69bb-3d89-8607-9e124eddbb0b레이블을 지정하지 않으면 Step Functions에서 자동으로 고유한 레이블을 생성합니다.
참고
레이블 길이는 40자를 초과할 수 없고 상태 머신 정의 내에서 고유해야 하며 다음과 같은 문자를 포함할 수 없습니다.
-
공백
-
와일드카드 문자 (
? *) -
괄호 문자(
< > { } [ ]) -
특수 문자 (
: ; , \ | ^ ~ $ # % & ` ") -
제어 문자(
\\u0000-\\u001f또는\\u007f-\\u009f).
Step Functions는 비 ASCII 문자가 포함된 상태 머신, 실행, 활동 및 레이블 이름을 허용합니다. 이러한 문자는 Amazon CloudWatch에서 데이터 로깅을 방지하므로 Step Functions 지표를 추적할 수 있도록 ASCII 문자만 사용하는 것이 좋습니다.
-
ResultWriter(선택 사항)-
Step Functions에서 모든 하위 워크플로 실행 결과를 기록하는 Amazon S3 위치를 지정합니다.
Step Functions는 실행 입력 및 출력, ARN, 실행 상태와 같은 모든 하위 워크플로 실행 데이터를 통합합니다. 그런 다음 같은 상태의 실행을 지정된 Amazon S3 위치에 있는 각 파일로 내보냅니다. 자세한 내용은 ResultWriter(맵) 단원을 참조하십시오.
Map상태 결과를 내보내지 않으면 모든 하위 워크플로 실행 결과 배열이 반환됩니다. 예제:[1, 2, 3, 4, 5] ResultPath(선택 사항, JSONPath만 해당)-
반복 출력을 배치할 위치를 입력에서 지정합니다. 그러면 입력은 OutputPath 필드(있는 경우)에서 지정한 대로 필터링된 후 상태 출력으로 전달됩니다. 자세한 내용은 입/출력 처리를 참조하십시오.
ResultSelector(선택 사항)-
키-값 페어 컬렉션을 전달합니다. 여기서 값은 정적이거나 결과에서 선택된 값입니다. 자세한 내용은 ResultSelector 단원을 참조하십시오.
작은 정보
상태 머신에서 사용하는 Parallel 또는 Map 상태가 배열을 반환하는 경우 ResultSelector 필드를 사용하여 배열을 평면 배열로 변환할 수 있습니다. 자세한 내용은 배열의 배열 평면화 단원을 참조하십시오.
Retry(선택 사항)-
Retrier라고 하는 객체 배열로, 재시도 정책을 정의합니다. 상태에서 런타임 오류가 발생하면 실행에서 재시도 정책을 사용합니다. 자세한 내용은 Retry 및 Catch를 사용하는 상태 머신 예 단원을 참조하십시오.
참고
Distributed Map 상태에 대한 Retrier를 정의하면 재시도 정책이
Map상태가 시작된 모든 하위 워크플로 실행에 적용됩니다. 예를 들어Map상태에서 하위 워크플로 실행 3개를 시작했는데 그 중 하나가 실패했다고 가정해보겠습니다. 실패가 발생하면 실행에서Map상태의Retry필드(정의된 경우) 를 사용합니다. 재시도 정책은 실패한 실행뿐만 아니라 모든 하위 워크플로 실행에 적용됩니다. 하위 워크플로 실행이 하나 이상 실패하면 맵 실행이 실패합니다.Map상태를 재시도하면 새 맵 실행이 생성됩니다. Catch(선택 사항)-
폴백(fallback) 상태를 정의하는 객체 배열(Catcher). 상태에서 런타임 오류가 발생하면 Step Functions는
Catch에 정의된 Catcher를 사용합니다. 오류가 발생하면 실행은 먼저Retry에 정의된 모든 Retrier를 사용합니다. 재시도 정책이 정의되지 않았거나 삭제되면 실행에서 Catcher(정의된 경우)를 사용합니다. 자세한 내용은 폴백 상태를 참조하십시오. Output(선택 사항, JSONata만 해당)-
상태에서 출력을 지정하고 트랜스포밍하는 데 사용됩니다. 지정하면 값이 상태 출력 기본값을 재정의합니다.
출력 필드는 모든 JSON 값(객체, 배열, 문자열, 숫자, 부울, null)을 허용합니다. 객체 또는 배열 내부의 문자열 값을 포함한 모든 문자열 값은 {% %} 문자로 묶여 있는 경우 JSONata로 평가됩니다.
출력은 "Output": "{% jsonata expression %}"와 같은 JSONata 표현식도 직접 수락합니다.
자세한 내용은 Step Functions에서 JSONata로 데이터 트랜스포밍 단원을 참조하십시오.
-
Assign(선택 사항) -
변수를 저장하는 데 사용됩니다.
Assign필드는 변수 이름과 할당된 값을 정의하는 키/값 페어가 있는 JSON 객체를 허용합니다. 객체 또는 배열 내부의 문자열 값을 포함한 모든 문자열 값은{% %}문자로 묶일 때 JSONata로 평가됩니다.자세한 내용은 변수를 사용하여 상태 간에 데이터 전달 단원을 참조하십시오.
Step Functions에서 분산 맵 상태의 실패 임계값 설정
대규모 병렬 워크로드를 오케스트레이션할 때 허용 실패 임계값을 정의할 수도 있습니다. 이 값을 사용하면 최대 실패 항목 수 또는 실패 항목 비율을 맵 실행의 실패 임계값으로 지정할 수 있습니다. 지정한 값에 따라 임계값을 초과하면 맵 실행이 자동으로 실패합니다. 두 값을 모두 지정하는 경우 두 값 중 하나를 초과하면 워크플로가 실패합니다.
임계값을 지정하면 전체 맵 실행이 실패하기 전에 특정 개수의 항목이 실패할 수 있습니다. 지정된 임계값이 초과되어 맵 실행이 실패하면 Step Functions에서 States.ExceedToleratedFailureThreshold 오류를 반환합니다.
참고
Step Functions는 허용 실패 임계값이 초과되더라도 맵 실행이 실패하기 전에 맵 실행에서 하위 워크플로를 계속 실행할 수 있습니다.
Workflow Studio에서 임계값을 지정하려면 런타임 설정 필드의 추가 구성에서 허용된 실패 임계값 설정을 선택합니다.
- 허용 실패 백분율
-
허용할 수 있는 실패 항목 백분율을 정의합니다. 이 값을 초과하면 맵 실행이 실패합니다. Step Functions는 실패하거나 시간 초과된 총 항목 수를 총 항목 수로 나눈 결과로 실패 항목 백분율을 계산합니다. 0~100 범위의 값을 지정해야 합니다. 기본 백분율 값은 0입니다. 즉, 하위 워크플로 실행 중 하나라도 실패하거나 시간 초과되면 워크플로가 실패합니다. 백분율을 100으로 지정하면 모든 하위 워크플로 실행이 실패하더라도 워크플로는 실패하지 않습니다.
또는 백분율을 Distributed Map 상태 입력에서 기존 키-값 페어의 참조 경로로 지정할 수 있습니다. 이 경로는 런타임 시 0~100 사이의 양의 정수로 해석되어야 합니다.
ToleratedFailurePercentagePath하위 필드에 참조 경로를 지정합니다.다음 입력을 예로 들어보겠습니다.
{"percentage":15}다음과 같이 해당 입력에 대한 참조 경로를 사용하여 백분율을 지정할 수 있습니다.
{ ... "Map": { "Type": "Map", ..."ToleratedFailurePercentagePath":"$.percentage"... } }중요
Distributed Map 상태 정의에서
ToleratedFailurePercentage또는ToleratedFailurePercentagePath를 지정할 수 있지만 둘 다 지정할 수는 없습니다. - 허용 실패 횟수
-
허용할 수 있는 실패 항목 수를 정의합니다. 이 값을 초과하면 맵 실행이 실패합니다.
또는 수를 Distributed Map 상태 입력에서 기존 키-값 페어의 참조 경로로 지정할 수 있습니다. 이 경로는 런타임 시의 양의 정수로 해석되어야 합니다.
ToleratedFailureCountPath하위 필드에 참조 경로를 지정합니다.다음 입력을 예로 들어보겠습니다.
{"count":10}다음과 같이 해당 입력에 대한 참조 경로를 사용하여 개수를 지정할 수 있습니다.
{ ... "Map": { "Type": "Map", ..."ToleratedFailureCountPath":"$.count"... } }중요
Distributed Map 상태 정의에서
ToleratedFailureCount또는ToleratedFailureCountPath를 지정할 수 있지만 둘 다 지정할 수는 없습니다.
분산 맵에 대해 자세히 알아보기
계속해서 Distributed Map 상태에 대해 자세히 알아보려면 다음 리소스를 참조하세요.
-
입/출력 처리
Distributed Map 상태에서 수신하는 입력과 생성되는 출력을 구성하기 위해 Step Functions는 다음 필드를 제공합니다.
Step Functions는 이러한 필드 외에도 Distributed Map의 허용 실패 임계값을 정의할 수 있는 기능을 제공합니다. 이 값을 사용하면 최대 실패 항목 수 또는 실패 항목 비율을 맵 실행의 실패 임계값으로 지정할 수 있습니다. 허용 실패 임계값 구성에 대한 자세한 내용은 Step Functions에서 분산 맵 상태의 실패 임계값 설정 섹션을 참조하세요.
-
Distributed Map 상태 사용
Distributed Map 상태 사용을 시작하려면 다음 자습서와 샘플 프로젝트를 참조하세요.
-
Distributed Map 상태 실행 예제
Step Functions 콘솔은 Distributed Map 상태 실행과 관련된 모든 정보를 표시하는 맵 실행 세부 정보 페이지를 제공합니다. 이 페이지에 표시된 정보를 검사하는 방법에 대한 자세한 내용은 맵 실행 보기 섹션을 참조하세요.
