Amazon RDS 的最佳实践
了解使用 Amazon RDS 的最佳实践。随着新的最佳实践的确定,我们将持续更新此部分。
主题
注意
有关 Amazon RDS 的常见建议,请参阅 来自 Amazon RDS 的建议。
Amazon RDS 基本操作指导方针
以下是使用 Amazon RDS 时每个人都应遵循的基本操作指导方针。请注意,Amazon RDS 服务等级协议要求您遵循以下指导方针:
-
使用指标监控您的内存、CPU、副本滞后和存储使用情况。可将 Amazon CloudWatch 设置为在使用模式发生变化或当部署接近容量限制时向您发送通知。这样,您就可以保持系统的性能和可用性。
-
当接近存储容量限制时,可以纵向扩展数据库实例。存储和内存中应含有一些缓冲区,以适应应用程序的意外增大需求。
-
启用自动备份并设置备份时段,以在每天写入 IOPS 较低的时段进行。这时备份对数据库使用的影响最小。
-
如果您的数据库工作负载需要的 I/O 超过您的配置,那么出现故障转移或数据库故障后,恢复的速度将会变缓。要增加数据库实例的 I/O 容量,请执行以下任一或所有操作:
迁移到其他具有高 I/O 容量的数据库实例类。
从磁性存储转换为通用存储或预置 IOPS 存储,具体取决于您需要增加的量。有关可用存储类型的信息,请参阅 Amazon RDS 存储类型。
如果转换为配置的 IOPS 存储,请确保还使用已针对配置的 IOPS 进行优化的数据库实例类。有关配置的 IOPS 的信息,请参阅 预置 IOPS SSD 存储。
如果您已在使用配置的 IOPS 存储,请额外配置吞吐量容量。
-
如果您的客户端应用程序正在缓存数据库实例的域名服务 (DNS) 数据,请将生存时间 (TTL) 值设置为小于 30 秒。数据库实例的底层 IP 地址在故障转移后可能会发生变化。因此,长时间缓存 DNS 数据可能会导致连接故障。您的应用程序可能会尝试连接到不再使用的 IP 地址。
-
测试数据库实例的故障转移,以了解对于您的特定使用案例而言,该过程需要多长时间。此外,测试故障转移,以确保访问您数据库实例的应用程序在故障转移发生之后,可以自动连接到新数据库实例。
数据库实例 RAM 建议
Amazon RDS 性能最佳实践是分配足够的 RAM,以便您的工作集几乎完全驻留在内存中。工作集是经常在实例上使用的数据和索引。使用数据库实例的次数越多,工作集的增长量就越大。
若要确定您的工作集是否几乎完全位于内存中,请在数据库实例加载期间检查 ReadIOPS 指标 (使用 Amazon CloudWatch)。ReadIOPS 的值应是一个较小且稳定的值。在某些情况下,将数据库实例类纵向扩展为具有更多 RAM 的类会导致 ReadIOPS 大幅降低。在这些情况下,您的工作集几乎不完全在内存中。继续向上扩展直至 ReadIOPS 不再在扩展操作后大幅降低,否则 ReadIOPS 将降低至非常小的数量。有关监控数据库实例的指标的信息,请参阅在 Amazon RDS 控制台中查看指标。
使数据库引擎版本保持最新
定期升级数据库引擎版本,以保持安全性、性能和合规性。Amazon RDS 会发布新的次要版本和主要版本,其中包括安全补丁、性能增强和新功能。运行过时的数据库引擎可能会使您的工作负载暴露于已知的漏洞、兼容性问题,以及来自 AWS 和数据库供应商的支持减少。
为了最大限度地减少中断,在计划升级时,请考虑以下几点:
-
在暂存环境中进行测试:在升级生产数据库之前,对照您的工作负载验证新版本。
-
使用 Amazon RDS 托管式升级:启用自动次要版本升级,便于修补。
-
安排主要版本升级:查看发布说明,测试应用程序兼容性,并规划受控的升级时段。
定期升级有助于确保您的数据库保持安全、优化并符合 AWS 最佳实践。
AWS 数据库驱动程序
推荐使用 AWS 驱动程序套件来建立应用程序连接。借助这些驱动程序可显著缩短切换和故障转移时间,并支持使用 AWS Secrets Manager、AWS Identity and Access Management(IAM)和联合身份进行身份验证。AWS 驱动程序依靠监控数据库实例状态和了解实例拓扑,来确定新的写入器。这种方法将切换和故障转移时间缩短到几秒钟,而开源驱动程序的切换和故障转移时间则为几十秒。
随着新服务功能的推出,使用 AWS 驱动程序套件可为这些服务功能提供内置支持。
有关更多信息,请参阅 使用 AWS 驱动程序连接到数据库实例。
使用增强监控来确定操作系统问题
启用增强监测后,Amazon RDS 可提供运行数据库实例的操作系统 (OS) 的实时指标。您可以使用控制台查看数据库实例的指标。您还可以在您选择的监控系统中通过 Amazon CloudWatch Logs 使用增强型监控 JSON 输出。有关增强监控的更多信息,请参阅 使用增强监控来监控操作系统指标。
使用指标确定性能问题
要确定资源不足和其他常见瓶颈导致的性能问题,您可以监控可用于 Amazon RDS 数据库实例的指标。
查看性能指标
您应定期监控性能指标以查看各种时间范围内的平均值、最大值和最小值。通过这样做,您可以确定性能下降的时间。您还可以针对特定指标阈值设置 Amazon CloudWatch 警报,以便在达到这些阈值时向您发出警报。
要排除性能问题,了解系统的基准性能十分重要。当您设置数据库实例并在典型工作负载下运行该实例时,请捕获所有性能指标的平均值、最大值和最小值。按多个不同的间隔(例如,一小时、24 小时、一周、两周)执行此操作。这使您能够了解正常运行状况。这有助于将操作的峰值时间与非峰值时间进行比较。您随后可以利用这些信息确定性能何时降到标准水平以下。
如果使用多可用区数据库集群,则监控写入器数据库实例上的最新事务与读取器数据库实例上最新应用的事务之间的时间差异。这种差异称为副本滞后。有关更多信息,请参阅 副本滞后和多可用区数据库集群。
您可以在 Performance Insights 控制面板中查看组合的 Performance Insights 和 CloudWatch 指标,并监控您的数据库实例。为使用此监控视图,必须为您的数据库实例开启 Performance Insights。有关监控视图的信息,请参阅使用性能详情控制面板查看组合指标。
您可以创建特定时间段的性能分析报告,并查看已确定的见解和解决问题的建议。有关更多信息,请参阅在性能详情中创建性能分析报告。
查看性能指标
登录AWS 管理控制台并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 在导航窗格中,选择 Databases (数据库),然后选择数据库实例。
选择监控。
控制面板提供性能指标。指标原定设置为显示最近三小时的信息。
使用页面右上角的编号按钮翻阅其他指标,或调整设置以查看更多指标。
可以选择性能指标来调整时间范围,以便查看除了当日之外的数据。可以更改 Statistic、Time Range 和 Period 值以调整显示的信息。例如,您可能希望查看某个指标在最近两周内每天的峰值。如果是这样,请将 Statistic(统计数据)设置为 Maximum(最大值),将 Time Range(时间范围)设置为 Last 2 Weeks(最近 2 周),将 Period(时段)设置为 Day(天)。
还可以使用 CLI 或 API 查看性能指标。有关更多信息,请参阅“在 Amazon RDS 控制台中查看指标”。
设置 CloudWatch 警报
-
登录AWS 管理控制台并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
在导航窗格中,选择 Databases (数据库),然后选择数据库实例。
-
选择日志和事件。
-
在 CloudWatch 警报部分中,选择创建警报。
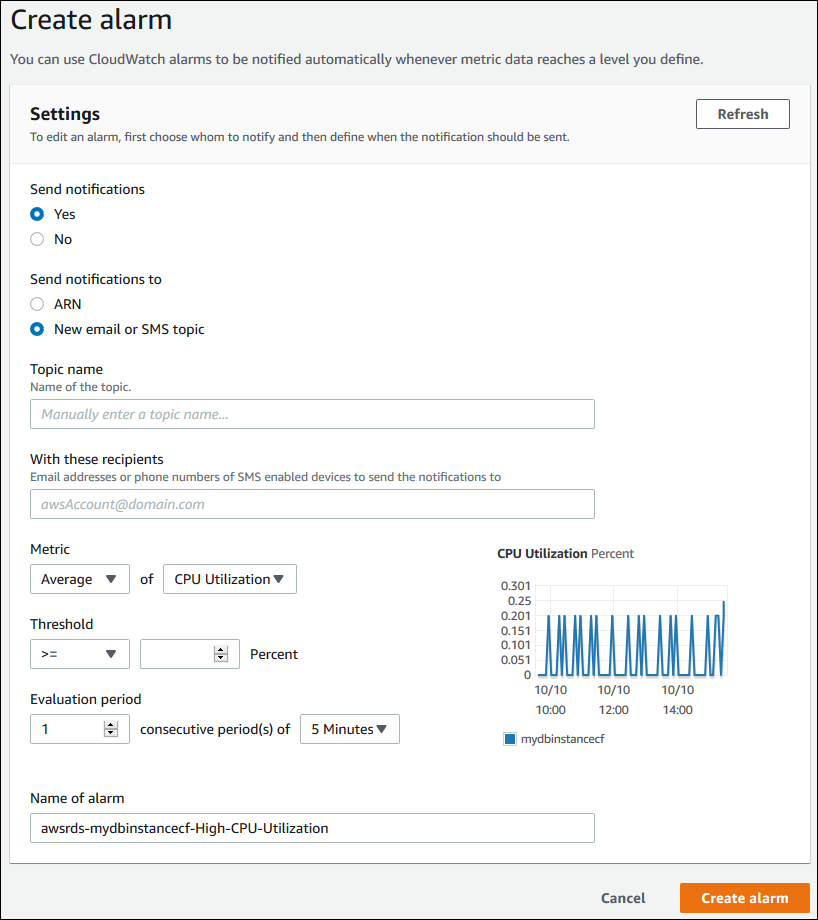
-
对于发送通知,选择是;对于发送通知到,选择新电子邮件或 SMS 主题。
-
对于主题名称,输入通知的名称;对于收件人如下,输入以逗号分隔的电子邮件地址和电话号码列表。
-
对于指标,选择要设置的警报统计信息和指标。
-
对于阈值,指定指标必须大于、小于还是等于阈值,然后指定阈值。
-
对于 Evaluation period(评估期),选择告警的评估期。对于 consecutive period(s) of(个连续周期,时间为),选择必须达到阈值才能触发告警的时段。
-
对于 Name of alarm (警报名称),输入警报的名称。
-
选择 Create Alarm。
警报将显示在 CloudWatch 警报部分中。
评估性能指标
数据库实例有一些不同类别的指标,确定可接受的值的方式取决于具体的指标。
CPU
CPU 使用率 – 使用的计算机处理容量的百分比。
内存
-
可释放内存 – 数据库实例上可用的 RAM 量(以字节为单位)。对于 CPU、内存和存储指标,“监控”选项卡中的红线指标标记为 75%。如果实例内存消耗频繁越过红线,则这指示您应检查您的工作负载或升级您的实例。
交换区使用情况 – 数据库实例使用的交换空间量(以字节为单位)。
磁盘空间
可用存储空间 – 数据库实例当前未使用的磁盘空间量(以 MB 为单位)。
输入/输出操作
读取 IOPS,写入 IOPS – 每秒进行的磁盘读取或写入操作平均数。
读取延迟,写入延迟 – 读取或写入操作的平均时间(以毫秒为单位)。
读取吞吐量,写入吞吐量 – 每秒对磁盘读取或写入的平均兆字节数。
队列深度 – 等待对磁盘写入或读取的 I/O 操作数。
网络流量
网络接收吞吐量,网络传输吞吐量 – 每秒出入数据库实例的网络流量速率(以每秒字节数为单位)。
数据库连接
数据库连接 – 连接到数据库实例的客户端会话数。
有关可用的性能指标的各个更详细的说明,请参阅使用 Amazon CloudWatch 监控 Amazon RDS 指标。
一般而言,性能指标的可接受值取决于您的基准性能以及应用程序执行的操作。应调查相对于基准性能的一致或趋势性变化。有关特定类型指标的建议如下:
High CPU or RAM consumption(高 CPU 或 RAM 消耗)– CPU 或 RAM 消耗值高可能是正常情况。例如,如果它们符合您的应用程序目标(如吞吐量或并发度)并且符合预期,则此类消耗值可能就是高。
磁盘空间消耗 – 如果使用的空间始终不低于总磁盘空间的 85%,则应调查磁盘空间消耗。应查看是否可以从实例中删除数据或是将数据存档到其他系统以释放空间。
网络流量 – 对于网络流量,应与系统管理员进行讨论,以了解域网络和 Internet 连接的预期吞吐量。如果吞吐量始终低于预期,则应调查网络流量。
数据库连接 – 如果发现用户连接数较高,同时实例性能下降并且响应时间延长,请考虑约束数据库连接。数据库实例的最佳用户连接数因您的实例类所执行操作的复杂性而异。要确定数据库连接的数量,请将数据库实例与参数组关联。在此组中,将 User Connections(用户连接)参数设置为 0 以外的值(无限制)。您可以使用现有参数组或新建一个。有关更多信息,请参阅“Amazon RDS 的参数组”。
IOPS 指标 – IOPS 指标的预期值取决于磁盘规格和服务器配置,因此,请使用您的基准来了解典型状况。调查值是否始终与您的基准不同。要获得最佳 IOPS 性能,请确保典型工作集适合内存大小,以最大程度减少读取和写入操作。
对于与性能指标有关的问题,改善性能的第一步是优化最常使用和成本最高昂的查询。对它们进行优化,看看这样做能否减轻系统资源承受的压力。有关更多信息,请参阅 优化查询。
如果您的查询经优化后,问题仍然存在,请考虑升级您的 Amazon RDS 数据库实例类。您可以将其升级为具有更多与问题相关的资源(CPU、RAM、磁盘空间、网络带宽,I/O 容量)的实例类。
优化查询
提高数据库实例性能的最佳方式之一是优化最常使用和占用资源最多的查询。在这里,您可以优化它们以降低它们的运行成本。有关改进查询的信息,请使用以下资源:
-
MySQL – 请参阅 MySQL 文档中的优化 SELECT 语句
。有关其他查询优化资源,请参阅 MySQL 性能调整和优化资源 。 -
Oracle – 请参阅 Oracle 数据库文档中的数据库 SQL 优化指南
。 -
SQL Server – 请参阅 Microsoft 文档中的分析查询
。您还可以使用与执行、索引和 I/O 相关的数据管理视图 (DMV)(在 Microsoft 文档的系统动态管理视图和功能 中进行了介绍)以排查 SQL Server 查询问题。 查询优化的一个常见途径是创建有效的索引。有关数据库实例的潜在索引改进,请参阅 Microsoft 文档中的 Database Engine Tuning Advisor
。有关在 RDS for SQL Server 上使用 Tuning Advisor 的信息,请参阅 使用 Database Engine Tuning Advisor 分析 Amazon RDS for SQL Server 数据库实例上的数据库工作负载。 -
PostgreSQL – 请参阅 PostgreSQL 文档中的使用 EXPLAIN
以了解如何分析查询计划。您可以参考此信息修改查询或底层表以提高查询性能。 有关如何在查询中指定联接以获得最佳性能的信息,请参阅使用显式 JOIN 子句控制计划程序
。 -
MariaDB – 请参阅 MariaDB 文档中的查询优化
。
使用 MySQL 的最佳实践
MySQL 数据库中的表大小和表的数量都会影响性能。
表大小
通常,操作系统对文件大小的约束决定了 MySQL 数据库的有效最大表大小。因此,限制通常不是由内部 MySQL 约束决定的。
在 MySQL 数据库实例中,请避免数据库中的表增长得过大。虽然一般存储限制为 64 TiB,但预置的存储限制将 MySQL 表文件的最大大小限制为 16 TiB。请对大型表进行分区,以将文件大小限制在 16 TiB 以内。此方法还可以提高性能并缩短恢复时间。有关更多信息,请参阅“Amazon RDS 中的 MySQL 文件大小限制”。
大小非常大的表(大于 100 GB)可能会对读取和写入(包括 DML 语句,尤其是 DDL 语句)的性能有负面影响。大型表上的索引可以显著提高选择性能,但也可能降低 DML 语句的性能。DDL 语句(例如 ALTER TABLE)在处理大型表时性能会显著降低,因为在某些情况下,这些操作可能会完全重建表。这些 DDL 语句可能会在操作期间锁定表。
MySQL 进行读取和写入操作所需的内存量取决于操作中涉及的表。最佳做法是至少有足够的 RAM 来保存主动使用的表的索引。要查找数据库中十个最大的表和索引,请使用以下查询:
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
表的数量
底层文件系统可能对表示表的文件的数量有限制。但是,MySQL 对表的数量没有限制。尽管如此,MySQL InnoDB 存储引擎中的表总数还是可能导致性能下降,无论这些表的大小如何。要限制操作系统的影响,您可以将表拆分到同一 MySQL 数据库实例中的多个数据库。这样做可能会限制目录中文件的数量,但不能解决整体问题。
当由于表的数量过多(超过 1 万个)而出现性能下降时,这种性能下降是由 MySQL 处理存储文件(包括打开和关闭存储文件)造成的。要解决此问题,可以提高 table_open_cache 和 table_definition_cache 参数的大小。但是,提高这些参数的值可能会显著增加 MySQL 使用的内存量,甚至可能会占用所有可用内存。有关更多信息,请参阅 MySQL 文档中的 MySQL 如何打开和关闭表
此外,表的数量过多会显著影响 MySQL 的启动时间。干净关机和重启以及崩溃恢复都可能受到影响,尤其是在 MySQL 8.0 之前的版本中。
我们建议数据库实例的所有数据库中表的总数少于 10,000。有关 MySQL 数据库中大量表的使用案例,请参阅 MySQL 8.0 中的一百万个表
存储引擎
Amazon RDS for MySQL 时间点还原和快照还原功能要求使用崩溃恢复存储引擎。仅 InnoDB 存储引擎支持这些功能。尽管 MySQL 支持功能不同的多种存储引擎,但并非所有引擎都为崩溃恢复和数据持久性而进行了优化。例如,MyISAM 存储引擎不支持可靠的崩溃恢复,并且可能使时间点还原或快照还原无法按预期工作。这可能导致在崩溃后重新启动 MySQL 时丢失或损坏数据。
InnoDB 是 Amazon RDS 上的 MySQL 数据库实例的推荐和支持的存储引擎。InnoDB 实例还可迁移到 Aurora,而 MyISAM 实例无法迁移。但是,如果您需要高强度的全文搜索功能,MyISAM 的效果比 InnoDB 更好。如果您仍然选择对 Amazon RDS 使用 MyISAM,遵循 使用不支持的 MySQL 存储引擎进行自动备份 中概述的步骤可能在某些情况下对执行快照恢复功能会有所帮助。
如果要将现有 MyISAM 表转换为 InnoDB 表,可以使用 MySQL 文档的 Converting Tables from MyISAM to InnoDB
此外,Amazon RDS for MySQL 当前不支持联合存储引擎。
使用 MariaDB 的最佳实践
MariaDB 数据库中的表大小和表的数量都会影响性能。
表大小
通常,操作系统对文件大小的约束决定了 MariaDB 数据库的有效最大表大小。因此,限制通常不是由内部 MariaDB 约束决定的。
在 MariaDB 数据库实例中,请避免数据库中的表增长得过大。虽然一般存储限制为 64 TiB,但预置的存储限制将 MariaDB 表文件的最大大小限制为 16 TiB。请对大型表进行分区,以将文件大小限制在 16 TiB 以内。此方法还可以提高性能并缩短恢复时间。
大小非常大的表(大于 100 GB)可能会对读取和写入(包括 DML 语句,尤其是 DDL 语句)的性能有负面影响。大型表上的索引可以显著提高选择性能,但也可能降低 DML 语句的性能。DDL 语句(例如 ALTER TABLE)在处理大型表时性能会显著降低,因为在某些情况下,这些操作可能会完全重建表。这些 DDL 语句可能会在操作期间锁定表。
MariaDB 进行读取和写入操作所需的内存量取决于操作中涉及的表。最佳做法是至少有足够的 RAM 来保存主动使用的表的索引。要查找数据库中十个最大的表和索引,请使用以下查询:
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
表的数量
底层文件系统可能对表示表的文件的数量有限制。但是,MariaDB 对表的数量没有限制。尽管如此,MariaDB InnoDB 存储引擎中的表总数还是可能导致性能下降,无论这些表的大小如何。要限制操作系统的影响,您可以将表拆分到同一 MariaDB 数据库实例中的多个数据库。这样做可能会限制目录中文件的数量,但不能解决整体问题。
当由于表的数量较多(超过 10,000)而出现性能下降时,这种性能下降是由 MariaDB 处理存储文件造成的。这项工作包括 MariaDB 打开和关闭存储文件。要解决此问题,可以提高 table_open_cache 和 table_definition_cache 参数的大小。但是,提高这些参数的值可能会显著增加 MariaDB 使用的内存量。它甚至可能会占用所有可用内存。有关详细信息,请参阅 MariaDB 文档中的优化 table_open_cache
此外,表的数量过多会显著影响 MariaDB 的启动时间。干净关机和重启以及崩溃恢复都可能受到影响。我们建议数据库实例中所有数据库中表的总数少于一万。
存储引擎
Amazon RDS for MariaDB 时间点还原和快照还原功能要求使用崩溃恢复存储引擎。尽管 MariaDB 支持功能不同的多种存储引擎,但并非所有引擎都针对崩溃恢复和数据耐久性而进行了优化。例如,尽管 Aria 是 MyISAM 的崩溃安全替代,但它仍可能使时间点还原或快照还原无法按预期工作。这可能导致在崩溃后重新启动 MariaDB 时丢失或损坏数据。InnoDB 是 Amazon RDS 上的 MariaDB 数据库实例的推荐和支持的存储引擎。如果您仍然选择对 Amazon RDS 使用 Aria,遵循使用不支持的 MariaDB 存储引擎进行自动备份中概述的步骤可能在某些情况下对执行快照恢复功能会有所帮助。
如果要将现有 MyISAM 表转换为 InnoDB 表,可以使用 MariaDB 文档的 Converting Tables from MyISAM to InnoDB
使用 Oracle 的最佳实践
有关使用 Amazon RDS for Oracle 的最佳实践信息,请参阅在 Amazon Web Services 中运行 Oracle 数据库的最佳实践。
2020 年AWS虚拟研讨会包括关于在 Amazon RDS 上运行生产 Oracle 数据库的演示。可在此处获取演示视频:
使用 PostgreSQL 的最佳实践
在以下两种重要情况下,您可改善 RDS for PostgreSQL 的性能:一种情况是在将数据加载到数据库实例中时。另一种情况是使用 PostgreSQL autovacuum 功能时。以下各节涵盖了我们针对以下情况建议的一些实例。
有关如何 Amazon RDS 实施其他常见 PostgreSQL DBA 任务的信息,请参阅 Amazon RDS for PostgreSQL 的数据库管理员常见任务。
将数据加载到 PostgreSQL 数据库实例中
在将数据加载到 Amazon RDS for PostgreSQL 数据库实例中时,修改数据库实例设置和数据库参数组值。将它们设置为允许以最高效的方式将数据导入数据库实例中。
对数据库实例设置进行以下修改:
-
禁用数据库实例备份(将 backup_retention 设置为 0)
-
禁用多可用区
修改数据库参数组以包括以下设置。此外,测试参数设置以找到对数据库实例最高效的设置。
-
增大
maintenance_work_mem参数的值。有关 PostgreSQL 资源消耗参数的更多信息,请参阅 PostgreSQL 文档。 -
增加
max_wal_size和checkpoint_timeout参数的值可减少对预写日志(WAL)进行写入的次数。 -
禁用
synchronous_commit参数 -
禁用 PostgreSQL autovacuum 参数。
-
确保您要导入的所有表都不是未记录的表。在故障转移期间,存储在未记录的表中的数据可能会丢失。有关更多信息,请参阅 CREATE TABLE UNLOGGED
。
将 pg_dump -Fc (压缩) 或 pg_restore -j (并行) 命令与这些设置结合使用。
加载操作完成后,将数据库实例和数据库参数恢复为正常设置。
使用 PostgreSQL Autovacuum 功能
PostgreSQL 数据库的 autovacuum 功能是我们强烈向您推荐的一项功能,您可使用此功能保持 PostgreSQL 数据库实例正常运行。Autovacuum 自动执行 VACUUM 和 ANALYZE 命令。使用 autovacuum 是 PostgreSQL 所需的而不是 Amazon RDS 强制的,并且使用此功能对于获得良好性能是至关重要的。原定设置情况下,为所有新的 Amazon RDS for PostgreSQL 数据库实例启用此功能,并将适当地设置相关的配置参数。
您的数据库管理员需要知道和了解此维护操作。有关 autovacuum 的 PostgreSQL 文档,请参阅Autovacuum 守护程序
Autovacuum 不是一个“不占用资源”的操作,但它将会在后台运行并尽可能地在让位于用户操作。启用后,autovacuum 将检查是否有包含大量更新的或删除的元组的表。它还可防止因事务 ID 重叠导致丢失非常旧的数据。有关更多信息,请参阅防止事务 ID 重叠故障
Autovacuum 不应被视为是一种开销较高的操作 (可减少此类操作以获得更佳性能)。相反,如果未运行 autovacuum,则更新和删除速度较快的表的性能将随时间推移而快速降低。
重要
不运行 autovacuum 可能导致最终需要中断工作来执行侵入性更强的 vacuum 操作。在某些情况下,RDS for PostgreSQL 数据库实例可能由于过于保守地使用 autovacuum 而变得不可用。在这些情况下,PostgreSQL 数据库会关闭以保护自己。此时,Amazon RDS 必须直接在数据库实例上执行单一用户模式完全 vacuum。这种完全 vacuum 可能导致多个小时的中断。因此,强烈建议您不要关闭在原定设置情况下开启的 autovacuum。
autovacuum 参数确定 autovacuum 运行的时间和难度。autovacuum_vacuum_threshold 和 autovacuum_vacuum_scale_factor 参数确定 autovacuum 运行的时间。autovacuum_max_workers、autovacuum_nap_time、autovacuum_cost_limit 和 autovacuum_cost_delay 参数确定 autovacuum 运行的难度。有关 autovacuum、其运行时间和所需参数的更多信息,请参阅 PostgreSQL 文档中的日常清理
以下查询显示名为 table1 的表中的“不活动”元祖数:
SELECT relname, n_dead_tup, last_vacuum, last_autovacuum FROM pg_catalog.pg_stat_all_tables WHERE n_dead_tup > 0 and relname = 'table1';
查询结果将与下面类似:
relname | n_dead_tup | last_vacuum | last_autovacuum ---------+------------+-------------+----------------- tasks | 81430522 | | (1 row)
Amazon RDS for PostgreSQL 最佳实践视频
2020 年AWS re:Invent 会议包含了有关新功能和在 Amazon RDS 上使用 PostgreSQL 的最佳实践的演示。可在此处获取演示视频:
使用 SQL Server 的最佳实践
利用 SQL Server 数据库实例实现多可用区部署的最佳实践包括:
使用 Amazon RDS 数据库事件来监控故障转移。例如,当数据库实例发生故障转移时,您会收到文本消息或电子邮件通知。有关 Amazon RDS 事件的更多信息,请参阅 使用 Amazon RDS 事件通知。
如果您的应用程序缓存了 DNS 值,则将生存时间 (TTL) 设置为小于 30 秒的值。在发生故障转移的情况下,这样设置 TTL 是一个好的做法。在故障转移的情况下,IP 地址可能发生更改,而且缓存值可能不再可用。
建议您不要 启用以下模式,因为它们会关闭多可用区所需的事务日志记录:
-
Simple 恢复模式
-
离线模式
-
只读模式
-
进行测试以确定数据库实例执行故障转移所需的时长。故障转移时间会因使用的数据库类型、实例类和存储类型而异。如果发生故障转移,还应测试您的应用程序继续运行的能力。
要缩短故障转移时间,请执行以下操作:
确保为您的工作负载分配了足够的配置的 IOPS。I/O 不足会导致延长故障转移时间。数据库恢复需要 I/O。
使用小型事务。数据库恢复依赖于事务,因此,如果您可将大型事务分成多个小型事务,则您的故障转移时间将缩短。
在故障转移期间,请考虑到延迟可能会有所提升。作为故障转移过程的一部分,Amazon RDS 自动将您的数据复制到新的备用实例。这种复制意味着将新数据提交到两个不同的数据库实例。因此,在备用数据库实例赶上新的主数据库实例的进度之前,可能会出现一些延迟。
在所有可用区内部署您的应用程序。如果某个可用区出现故障,您在其他可用区内的应用程序仍将可用。
在使用 SQL Server 的多可用区部署时,请记住,Amazon RDS 会为您实例上的所有 SQL Server 数据库创建副本。如果不希望特定数据库具有辅助副本,请设置不使用这些数据库的多可用区的单独数据库实例。
Amazon RDS for SQL Server 最佳实践视频
2019 年AWS re:Invent 会议包含了有关新功能和在 Amazon RDS 上使用 SQL Server 的最佳实践的演示。可在此处获取演示视频:
使用数据库参数组
我们建议,在将参数组更改应用于生产数据库实例前,您应当在测试数据库实例上试验数据库参数组更改。在数据库参数组内不恰当地设置数据库引擎参数可能会产生意外的不利影响,包括性能降低和系统不稳定。修改数据库引擎参数时应始终保持谨慎,并且在修改数据库参数组前要备份数据库实例。
有关备份数据库实例的信息,请参阅备份、还原和导出数据。
自动创建数据库实例的最佳实践
Amazon RDS最佳实践是使用数据库引擎的首选次要版本创建数据库实例。您可以使用 AWS CLI、Amazon RDS API 或 AWS CloudFormation 自动创建数据库实例。使用这些方法时,您只能指定主要版本,Amazon RDS 随后将自动创建采用首选次要版本的实例。例如,如果 PostgreSQL 12.5 是首选次要版本,并且您使用 create-db-instance 指定版本 12,则数据库实例的版本将使用版本 12.5。
要确定首选次要版本,您可以使用 describe-db-engine-versions 选项运行 --default-only 命令,如以下示例所示。
aws rds describe-db-engine-versions --default-only --engine postgres { "DBEngineVersions": [ { "Engine": "postgres", "EngineVersion": "12.5", "DBParameterGroupFamily": "postgres12", "DBEngineDescription": "PostgreSQL", "DBEngineVersionDescription": "PostgreSQL 12.5-R1", ...some output truncated... } ] }
有关以编程方式创建数据库实例的信息,请参阅以下资源:
使用 AWS CLI – create-db-instance
使用 Amazon RDS API – CreateDBInstance
使用 AWS CloudFormation – AWS::RDS::DBInstance
Amazon RDS 新特征视频
2023 年 AWS re:Invent 会议包含了有关新的 Amazon RDS 特征的演示。可在此处获取演示视频:
