您可以创建 Amazon CloudWatch 告警,使其在多可用区数据库集群的副本滞后超过阈值时发送 Amazon SNS 消息。告警会在您指定的时间范围内监控 ReplicaLag 指标。操作是向 Amazon SNS 主题或 Amazon EC2 Auto Scaling 策略发送的通知。
为多可用区数据库集群副本滞后设置 CloudWatch 告警
登录 AWS Management Console 并打开 CloudWatch 控制台,网址为 https://console.aws.amazon.com/cloudwatch/
。 -
在导航窗格中,依次选择 Alarms(警报)和 All alarms(所有警报)。
-
选择Create alarm(创建警报)。
-
在 Specify metric and conditions (指定指标和条件) 页面上,选择 Select metric (选择指标)。
-
在搜索框中,输入多可用区数据库集群的名称,然后按 Enter。
下图显示 Select metric(选择指标)页面,其中输入了名为
rds-cluster的多可用区数据库集群。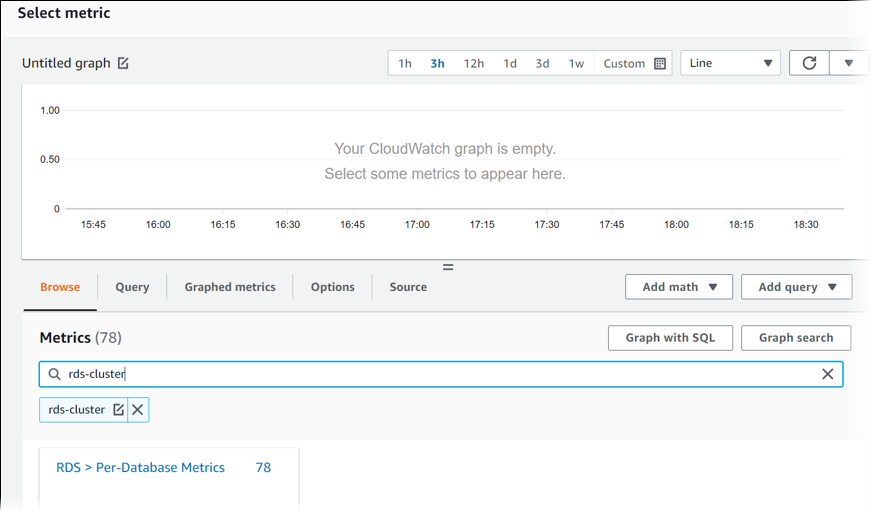
-
依次选择 RDS、Per-Database Metrics(每个数据库的指标)。
-
在搜索框中,输入
ReplicaLag并按 Enter,然后选择数据库集群中的每个数据库实例。下图显示 Select metric(选择指标)页面,及为 ReplicaLag 指标选择的数据库实例。
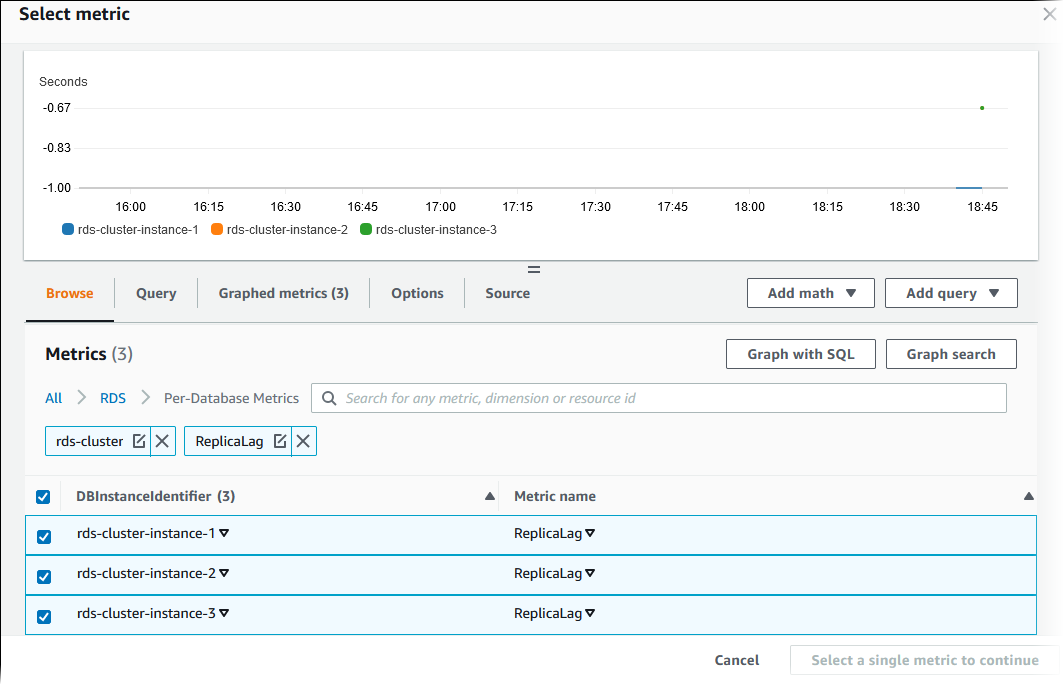
此告警考虑多可用区数据库集群中所有三个数据库实例的副本滞后。任何数据库实例超过阈值时,该告警都会响应。它使用一个数学表达式,返回三个指标的最大值。首先按指标名称排序,然后选择所有三个 RepliaLag 指标。
-
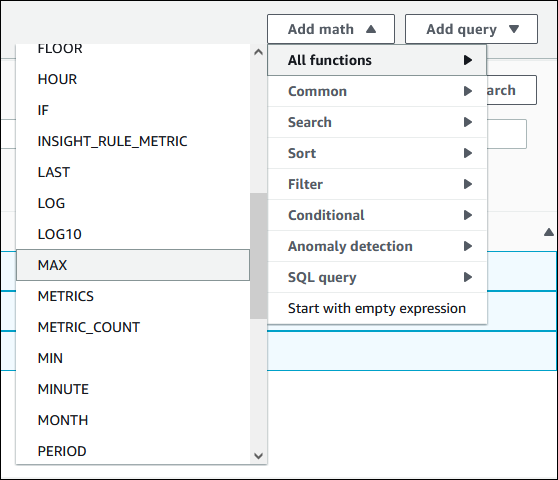
从 Add math(添加数学表达式)中,依次选择 All functions(所有函数)、MAX。
-
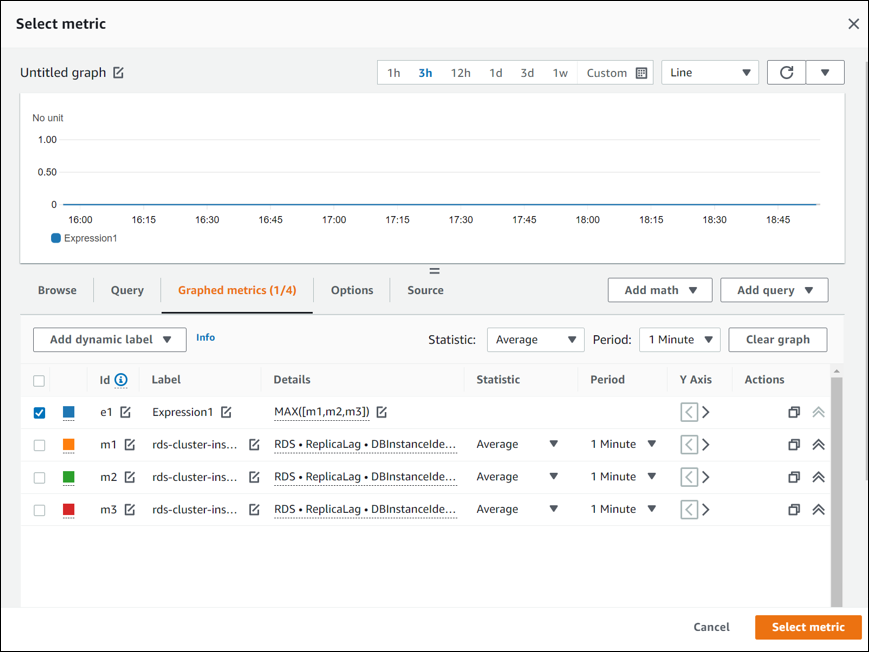
选择 Graphed metrics(绘制的指标)选项卡,然后将 Expression1(表达式 1)的详细信息编辑为
MAX([m1,m2,m3])。 -
对于所有三个 ReplicaLag 指标,将 Period(周期)更改为 1 minute(1 分钟)。
-
清除所有指标的选择, Expression1(表达式 1)除外。
Select metric(选择指标)页面应类似于以下图像。
-
选择选择指标。
-
在 Specify metric and conditions(指定指标和条件)页面中,将标签更改为有意义的名称(例如
ClusterReplicaLag),然后在 Define the threshold value(定义阈值)中输入秒数。对于本教程,请输入1200秒(20 分钟)。您可以根据工作负载要求调整该值。Specify metric and conditions(指定指标和条件)页面应类似于以下图像。
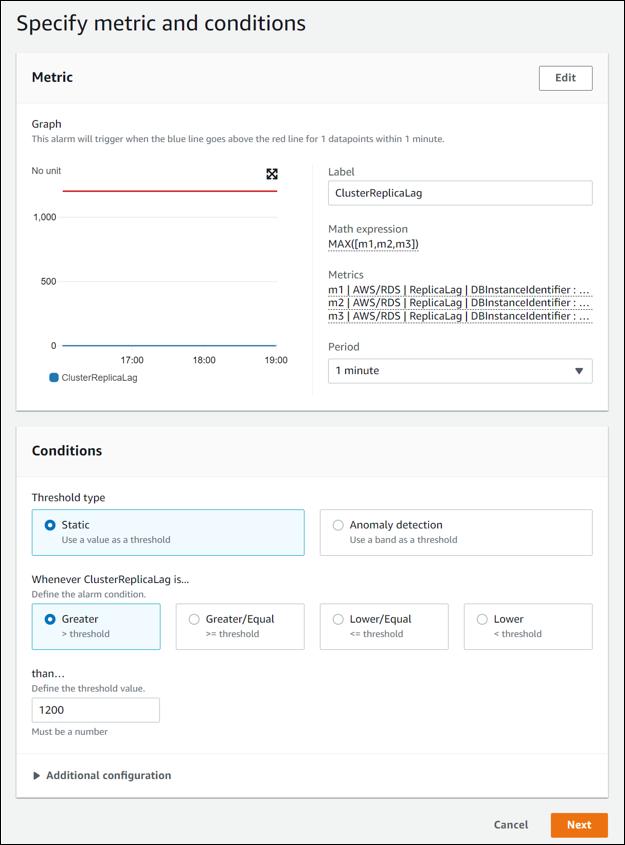
-
选择 Next(下一步),随即显示 Configure actions(配置操作)页面。
-
保持选中 In alarm(处于告警中),选择 Create new topic(创建新主题),然后输入主题名称和有效的电子邮件地址。
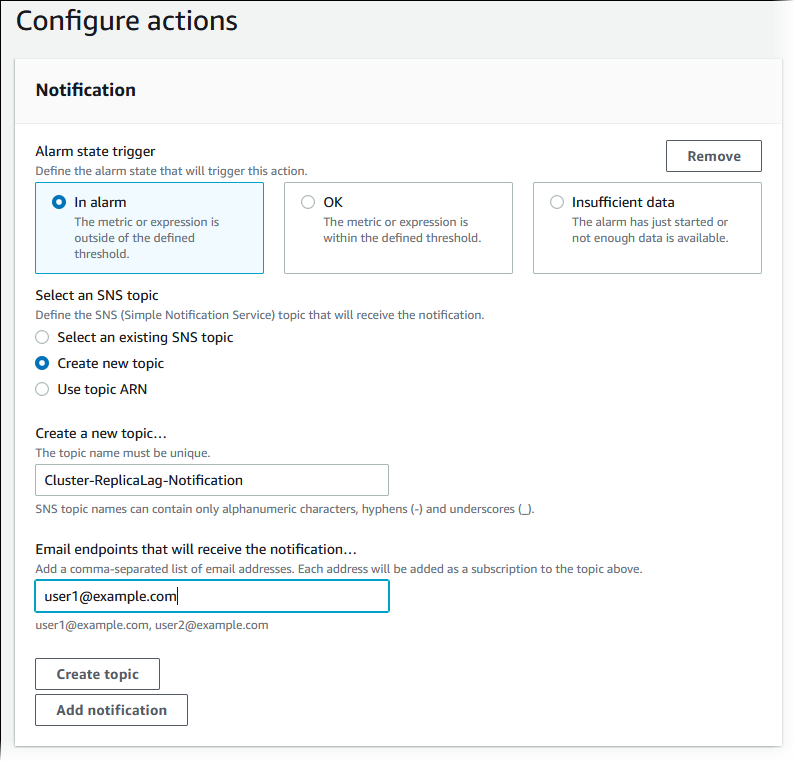
-
选择 Create topic(创建主题),然后选择 Next(下一步)。
-
在 Add name and description(添加名称和说明)页面中,输入 Alarm name(告警名称)和 Alarm description(告警说明),然后选择 Next(下一步)。
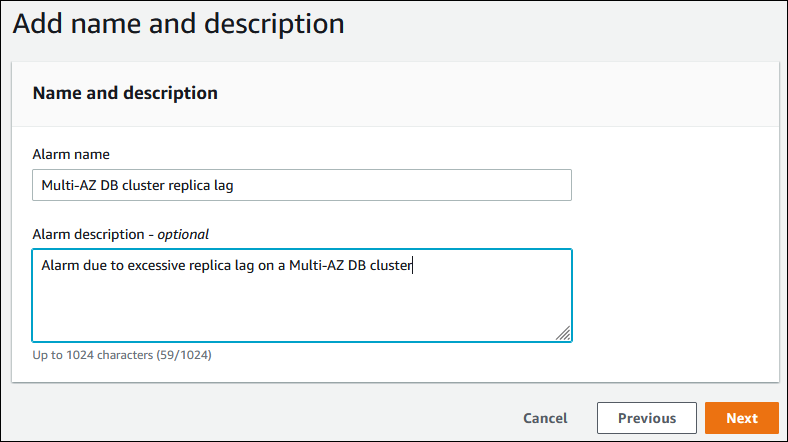
-
预览您将在 Preview and create(预览和创建)页面上创建的告警,然后选择 Create alarm(创建告警)。
