可通过适用于 Apache Kafka 的 Amazon Athena 连接器支持 Amazon Athena 对 Apace Kafka 主题运行 SQL 查询。使用此连接器在 Athena 中以表的形式查看 Apache Kafka
此连接器不使用 Glue 连接将配置属性集中保存到 Glue 中。连接配置通过 Lambda 完成。
先决条件
可以使用 Athena 控制台或 AWS Serverless Application Repository 将该连接器部署到您的 AWS 账户。有关更多信息,请参阅创建数据来源连接或使用 AWS Serverless Application Repository 部署数据来源连接器。
限制
-
不支持写入 DDL 操作。
-
任何相关的 Lambda 限制。有关更多信息,请参阅《AWS Lambda 开发人员指南》中的 Lambda 配额。
-
必须将筛选条件中的日期和时间戳数据类型转换为适当的数据类型。
-
CSV 文件类型不支持日期和时间戳数据类型,它们被视为 VARCHAR 值。
-
不支持映射到嵌套 JSON 字段。连接器仅映射顶级字段。
-
连接器不支持复杂类型。复杂类型解释为字符串。
-
要提取或处理复杂的 JSON 值,请使用 Athena 中可用的 JSON 相关函数。有关更多信息,请参阅 从字符串中提取 JSON 数据。
-
连接器不支持对 Kafka 消息元数据的访问。
术语
-
元数据处理程序 — 从您的数据库实例中检索元数据的 Lambda 处理程序。
-
记录处理程序 — 从您的数据库实例中检索数据记录的 Lambda 处理程序。
-
复合处理程序 — 从您的数据库实例中检索元数据和数据记录的 Lambda 处理程序。
-
Kafka 端点 – 文本字符串,用于建立与 Kafka 实例的连接。
集群兼容性
Kafka 连接器可用于以下集群类型。
-
独立 Kafka - 与 Kafka 直接连接(经过或未经身份验证)。
-
Confluent - 与 Confluent Kafka 直接连接。有关将 Athena 与 Confluent Kafka 数据配合使用的信息,请参阅 AWS 商业智能博客中的使用 Amazon Athena 在 Amazon QuickSight 中可视化 Confluent 数据
。
连接到 Confluent
要连接到 Confluent,需要执行以下步骤:
-
从 Confluent 生成 API 密钥。
-
将 Confluent API 密钥的用户名和密码存储到 AWS Secrets Manager 中。
-
在 Kafka 连接器中提供
secrets_manager_secret环境变量的密钥名称。 -
按照本文档的 设置 Kafka 连接器 节中的步骤执行操作。
支持的身份验证方法
连接器支持以下身份验证方法。
-
SASL/PLAIN
-
SASL/PLAINTEXT
-
NO_AUTH
-
自行管理的 Kafka 和 Confluent 平台 – SSL、SASL/SCRAM、SASL/PLAINTEXT、NO_AUTH
-
自行管理的 Kafka 和 Confluent Cloud - SASL/PLAIN
有关更多信息,请参阅 为 Athena Kafka 连接器配置身份验证。
支持的输入数据格式
连接器支持以下输入数据格式。
-
JSON
-
CSV
-
AVRO
-
PROTOBUF (PROTOCOL BUFFERS)
参数
使用本节中的参数来配置 Athena Kafka 连接器。
-
auth_type – 指定集群的身份验证类型。连接器支持以下身份验证类型:
-
NO_AUTH - 直接连接到 Kafka(例如,连接到部署在 EC2 实例上的 Kafka 集群,但不使用身份验证)。
-
SASL_SSL_PLAIN – 此方法使用
SASL_SSL安全协议和PLAINSASL 机制。有关更多信息,请参阅 Apache Kafka 文档中的 SASL 配置。 -
SASL_PLAINTEXT_PLAIN – 此方法使用
SASL_PLAINTEXT安全协议和PLAINSASL 机制。有关更多信息,请参阅 Apache Kafka 文档中的 SASL 配置。 -
SASL_SSL_SCRAM_SHA512 - 您可以使用此身份验证类型控制对 Apache Kafka 集群的访问权限。此方法将用户名和密码存储在 AWS Secrets Manager 中。密钥必须与 Kafka 集群相关。有关更多信息,请参阅 Apache Kafka 文档中的使用 SASL/SCRAM 进行身份验证
。 -
SASL_PLAINTEXT_SCRAM_SHA512 - 此方法使用
SASL_PLAINTEXT安全协议和SCRAM_SHA512 SASL机制。此方法使用存储在 AWS Secrets Manager 中的用户名和密码。有关更多信息,请参阅 Apache Kafka 文档中的 SASL 配置一节。 -
SSL - SSL 身份验证使用密钥存储和信任存储文件来连接 Apache Kafka 集群。您必须生成信任存储和密钥存储文件,将其上传到 Amazon S3 存储桶,并在部署连接器时提供对 Amazon S3 的引用。密钥存储、信任存储和 SSL 密钥存储在 AWS Secrets Manager 中。部署连接器时需要提供 AWS 私有密钥。有关更多信息,请参阅 Apache Kafka 文档中的使用 SSL 进行加密和身份验证
。 有关更多信息,请参阅 为 Athena Kafka 连接器配置身份验证。
-
-
certificates_s3_reference – 包含证书(密钥存储和信任存储文件)的 Amazon S3 位置。
-
disable_spill_encryption -(可选)当设置为
True时,将禁用溢出加密。默认值为False,此时将使用 AES-GCM 对溢出到 S3 的数据使用进行加密 - 使用随机生成的密钥,或者使用 KMS 生成密钥。禁用溢出加密可以提高性能,尤其是当您的溢出位置使用服务器端加密时。 -
kafka_endpoint – 提供给 Kafka 的端点详细信息。
-
schema_registry_url – 架构注册表的 URL 地址(例如
http://schema-registry.example.org:8081)。适用于AVRO和PROTOBUF数据格式。Athena 仅支持 Confluent 架构注册表。 -
secrets_manager_secret – 保存凭证的 AWS 密钥名称。
-
溢出参数 – Lambda 函数将不适合内存的数据临时存储(“溢出”)到 Amazon S3。由同一 Lambda 函数访问的所有数据库实例都会溢出到同一位置。使用下表中的参数指定溢出位置。
参数 描述 spill_bucket必需。Amazon S3 存储桶的名称,Lambda 函数可以在该存储桶中溢出数据。 spill_prefix必需。溢出存储桶中的前缀,Lambda 函数可以在该存储桶中溢出数据。 spill_put_request_headers(可选)用于溢出的 Amazon S3 putObject请求的请求标头和值的 JSON 编码映射(例如,{"x-amz-server-side-encryption" : "AES256"})。有关其他可能的标头,请参阅《Amazon Simple Storage Service API 参考》中的 PutObject。 -
子网 ID - 与 Lambda 函数可用于访问数据来源的子网对应的一个或多个子网 ID。
-
公有 Kafka 集群或标准 Confluent Cloud 集群 - 将连接器与具有 NAT 网关的私有子网关联。
-
具有私有连接的 Confluent Cloud 集群 - 将连接器与具有通往 Confluent Cloud 集群的路由的私有子网关联。
-
对于 AWS 中转网关
,子网必须位于连接到 Confluent Cloud 使用的相同中转网关的 VPC 中。 -
对于 VPC 对等
,子网必须位于与 Confluent Cloud VPC 对等的 VPC 中。 -
对于 AWS PrivateLink
,子网必须位于具有通往 VPC 端点的路由的 VPC 中,该端点连接到 Confluent Cloud。
-
-
注意
如果您将连接器部署到 VPC 中以访问私有资源,并且还想连接到 Confluent 等可公开访问的服务,则必须将连接器关联到某个具有 NAT 网关的私有子网。有关更多信息,请参阅《Amazon VPC 用户指南》中的 NAT 网关。
数据类型支持
下表显示了 Kafka 和 Apache Arrow 支持的相应数据类型。
| Kafka | Arrow |
|---|---|
| CHAR | VARCHAR |
| VARCHAR | VARCHAR |
| TIMESTAMP | MILLISECOND |
| DATE | DAY |
| BOOLEAN | BOOL |
| SMALLINT | SMALLINT |
| INTEGER | INT |
| BIGINT | BIGINT |
| DECIMAL | FLOAT8 |
| DOUBLE | FLOAT8 |
分区和拆分
Kafka 主题分为多个分区。每个分区会进行排序。分区中的每条消息都有一个增量 ID,称为偏移。每个 Kafka 分区进一步分为多个分区,以进行并行处理。数据在 Kafka 集群中配置的保留期内可用。
最佳实践
最佳做法是在查询 Athena 时使用谓词下推,如下例所示。
SELECT *
FROM "kafka_catalog_name"."glue_schema_registry_name"."glue_schema_name"
WHERE integercol = 2147483647SELECT *
FROM "kafka_catalog_name"."glue_schema_registry_name"."glue_schema_name"
WHERE timestampcol >= TIMESTAMP '2018-03-25 07:30:58.878'设置 Kafka 连接器
在使用连接器之前,您必须设置 Apache Kafka 集群,使用 AWS Glue 架构注册表定义架构,并为连接器配置身份验证。
使用 AWS Glue 架构注册表时,请注意以下几点:
-
确保 AWS Glue 架构注册表的 Description(描述)字段中的文本包含
{AthenaFederationKafka}字符串。此标记字符串是与 Amazon Athena Kafka 连接器一起使用的 AWS Glue 注册表中的必需项。 -
为了获得最佳性能,数据库名称和表名称仅限使用小写。使用混合大小写会使连接器执行不区分大小写的搜索,这种搜索的计算密集度更高。
设置 Apache Kafka 环境和 AWS Glue 架构注册表
-
设置 Apache Kafka 环境。
-
将 JSON 格式的 Kafka 主题描述文件(即其架构)上传到 AWS Glue 架构注册表。有关更多信息,请参阅《AWS Glue 开发人员指南》中的与 AWS Glue 架构注册表集成。
-
要在 AWS Glue 架构注册表中定义架构时使用
AVRO或PROTOBUF数据格式,请执行以下操作:-
对于架构名称,以原始名称相同的大小写输入 Kafka 主题名称。
-
对于数据格式,选择 Apache Avro 或 Protocol Buffers。
有关详细示例,请参阅以下章节。
-
将架构上传到 AWS Glue 架构注册表时,请使用本节中的示例格式。
JSON 类型架构示例
在以下示例中,要在 AWS Glue 架构注册表中创建的架构指定 json 作为 dataFormat 的值,并将 datatypejson 用于 topicName。
注意
topicName 的值应使用与 Kafka 中主题名称相同的大小写。
{
"topicName": "datatypejson",
"message": {
"dataFormat": "json",
"fields": [
{
"name": "intcol",
"mapping": "intcol",
"type": "INTEGER"
},
{
"name": "varcharcol",
"mapping": "varcharcol",
"type": "VARCHAR"
},
{
"name": "booleancol",
"mapping": "booleancol",
"type": "BOOLEAN"
},
{
"name": "bigintcol",
"mapping": "bigintcol",
"type": "BIGINT"
},
{
"name": "doublecol",
"mapping": "doublecol",
"type": "DOUBLE"
},
{
"name": "smallintcol",
"mapping": "smallintcol",
"type": "SMALLINT"
},
{
"name": "tinyintcol",
"mapping": "tinyintcol",
"type": "TINYINT"
},
{
"name": "datecol",
"mapping": "datecol",
"type": "DATE",
"formatHint": "yyyy-MM-dd"
},
{
"name": "timestampcol",
"mapping": "timestampcol",
"type": "TIMESTAMP",
"formatHint": "yyyy-MM-dd HH:mm:ss.SSS"
}
]
}
}CSV 类型架构示例
在以下示例中,要在 AWS Glue 架构注册表中创建的架构指定 csv 作为 dataFormat 的值,并将 datatypecsvbulk 用于 topicName。topicName 的值应使用与 Kafka 中主题名称相同的大小写。
{
"topicName": "datatypecsvbulk",
"message": {
"dataFormat": "csv",
"fields": [
{
"name": "intcol",
"type": "INTEGER",
"mapping": "0"
},
{
"name": "varcharcol",
"type": "VARCHAR",
"mapping": "1"
},
{
"name": "booleancol",
"type": "BOOLEAN",
"mapping": "2"
},
{
"name": "bigintcol",
"type": "BIGINT",
"mapping": "3"
},
{
"name": "doublecol",
"type": "DOUBLE",
"mapping": "4"
},
{
"name": "smallintcol",
"type": "SMALLINT",
"mapping": "5"
},
{
"name": "tinyintcol",
"type": "TINYINT",
"mapping": "6"
},
{
"name": "floatcol",
"type": "DOUBLE",
"mapping": "7"
}
]
}
}AVRO 类型架构示例
以下示例用于在 AWS Glue 架构注册表中创建基于 AVRO 的架构。在 AWS Glue 架构注册表中定义架构时,对于架构名称,以原始名称相同的大小写输入 Kafka 主题名称;对于数据格式,选择 Apache Avro。由于您直接在注册表中指定了此信息,因此 dataformat 和 topicName 字段不是必填字段。
{
"type": "record",
"name": "avrotest",
"namespace": "example.com",
"fields": [{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
]
}PROTOBUF 类型架构示例
以下示例用于在 AWS Glue 架构注册表中创建基于 PROTOBUF 的架构。在 AWS Glue 架构注册表中定义架构时,对于架构名称,以原始名称相同的大小写输入 Kafka 主题名称;对于数据格式,选择 Protocol Buffers。由于您直接在注册表中指定了此信息,因此 dataformat 和 topicName 字段不是必填字段。第一行将架构定义为 PROTOBUF。
syntax = "proto3"; message protobuftest { string name = 1; int64 calories = 2; string colour = 3; }
有关在 AWS Glue 架构注册表中添加注册表和架构的更多信息,请参阅 AWS Glue 文档中的架构注册表入门。
为 Athena Kafka 连接器配置身份验证
您可以使用多种方法对 Apache Kafka 集群进行身份验证,包括 SSL、SASL/SCRAM、SASL/PLAIN 和 SASL/PLAINTEXT。
下表显示了连接器的身份验证类型以及每种连接器的安全协议和 SASL 机制。有关更多信息,请参阅 Apache Kafka 文档中的安全性
| auth_type | security.protocol | sasl.mechanism | 集群类型兼容性 |
|---|---|---|---|
SASL_SSL_PLAIN |
SASL_SSL |
PLAIN |
|
SASL_PLAINTEXT_PLAIN |
SASL_PLAINTEXT |
PLAIN |
|
SASL_SSL_SCRAM_SHA512 |
SASL_SSL |
SCRAM-SHA-512 |
|
SASL_PLAINTEXT_SCRAM_SHA512 |
SASL_PLAINTEXT |
SCRAM-SHA-512 |
|
SSL |
SSL |
不适用 |
|
SSL
如果集群经过 SSL 身份验证,则您必须生成信任存储和密钥存储文件,并将其上传到 Amazon S3 存储桶。部署连接器时,必须提供此 Amazon S3 参考资料。密钥存储、信任存储和 SSL 密钥存储在 AWS Secrets Manager 中。部署连接器时需要提供 AWS 密钥。
有关在 Secrets Manager 中创建密钥的信息,请参阅创建 AWS Secrets Manager 密钥。
要使用此身份验证类型,请按下表所示设置环境变量。
| 参数 | 值 |
|---|---|
auth_type |
SSL |
certificates_s3_reference |
包含证书的 Amazon S3 位置。 |
secrets_manager_secret |
您的 AWS 密钥名称。 |
在 Secrets Manager 中创建密钥后,您可以在 Secrets Manager 控制台中查看该密钥。
在 Secrets Manager 中查看密钥
打开 Secrets Manager 控制台,网址为 https://console.aws.amazon.com/secretsmanager/
。 -
在导航窗格中,选择 Secrets(密钥)。
-
在 Secrets(密钥)页面,选择密钥链接。
-
在密钥的详细信息页面上,选择 Retrieve secret value(检索密钥值)。
下图显示了示例密钥,其中包含三个键值对:
keystore_password、truststore_password和ssl_key_password。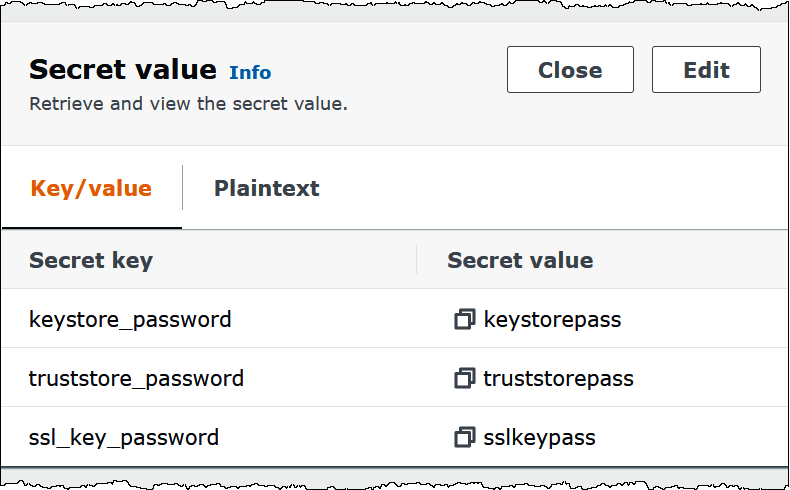
有关在 Kafka 中使用 SSL 的更多信息,请参阅 Apache Kafka 文档中的使用 SSL 进行加密和身份验证
SASL/SCRAM
如果您的集群使用 SCRAM 身份验证,请在部署连接器时提供与集群关联的 Secrets Manager 密钥。用户的 AWS 凭证(密钥和访问密钥)用于与集群进行身份验证。
按下表所示设置环境变量。
| 参数 | 值 |
|---|---|
auth_type |
SASL_SSL_SCRAM_SHA512 |
secrets_manager_secret |
您的 AWS 密钥名称。 |
下图显示了 Secrets Manager 控制台中的示例密钥,其中包含两个键值对:一个用于 username,另一个用于 password。
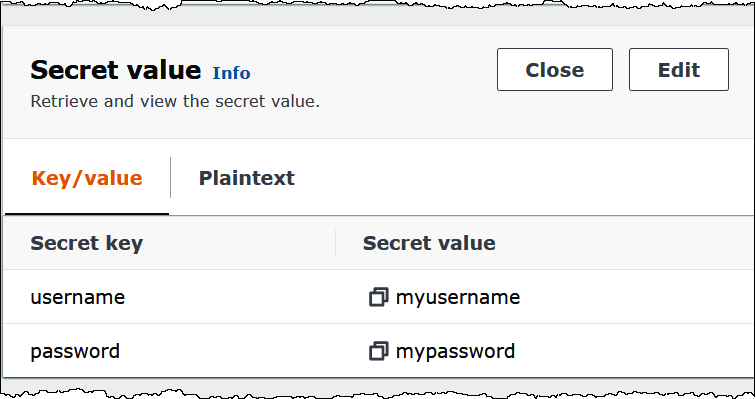
有关在 Kafka 中使用 SASL/SCRAM 的更多信息,请参阅 Apache Kafka 文档中的使用 SASL/SCRAM 进行身份验证
许可证信息
使用此连接器,即表示您确认包含第三方组件(这些组件的列表可在此连接器的 pom.xml
其他资源
有关此连接器的更多信息,请访问 GitHub.com 上的相应站点
