您可以使用 Athena SQL 中的成本型优化器(CBO)功能来优化查询。您可以选择请求 Athena 为 AWS Glue 中的一个表收集表级或列级统计数据。如果查询中的所有表都有统计数据,Athena 会使用这些统计数据来创建它认为性能最佳的执行计划。查询优化器会根据统计模型来计算备选计划,然后选择速度可能最快的计划来运行查询。
AWS Glue 表上的统计数据被收集并存储在 AWS Glue Data Catalog 中,也提供给 Athena 来改进查询计划和执行。这些统计数据是列级统计数据,例如 Parquet、ORC、JSON、ION、CSV 和 XML 等文件类型的不同值、空值、最大值和最小值的个数。Amazon Athena 通过在查询处理中尽早应用最严格的筛选条件来使用这些统计数据优化查询。这种筛选功能限制了内存使用量和为提供查询结果而必须读取的记录数。
Athena 还会将 CBO 和规则型优化器(RBO)功能结合起来使用。RBO 以机械方式应用可提高查询性能的规则。RBO 通常会带来益处,因为它的转换是为了简化查询计划。不过,由于 RBO 不进行成本计算或计划比较,查询较复杂便会让 RBO 难以创建最佳计划。
因此,Athena 会同时使用 RBO 和 CBO 来优化您的查询。在确定改进查询执行的机会后,Athena 就会创建最佳计划。有关执行计划详情的信息,请参阅查看 SQL 查询的执行计划。有关 CBO 如何工作的详细讨论,请参阅 AWS 大数据博客中的 Speed up queries with the cost-based optimizer in Amazon Athena
要为 AWS Glue Catalog 表生成统计数据,可以使用 Athena 控制台、AWS Glue 控制台或 AWS Glue API。由于 Athena 已与 AWS Glue Catalog 集成,在运行来自 Amazon Athena 的查询时,您会自动获得相应的查询性能改进。
注意事项和限制
-
表类型 – 目前,Athena 中的 CBO 功能仅支持 AWS Glue Data Catalog 中的 Hive 表。
-
Athena for Spark – CBO 功能在 Athena for Spark 中不可用。
-
定价 – 有关定价信息,请访问 AWS Glue 定价页面
。
使用 Athena 控制台生成表统计数据
本节旨在介绍如何使用 Athena 控制台为 AWS Glue 中的表生成表级或列级统计数据。有关使用 AWS Glue 生成表统计数据的信息,请参阅《AWS Glue Developer Guide》中的 Working with column statistics。
使用 Athena 控制台为表生成统计数据
从 https://console.aws.amazon.com/athena/
打开 Athena 控制台。 -
在 Athena 查询编辑器的表列表中,选择所需表的三个垂直点,然后选择生成统计数据。
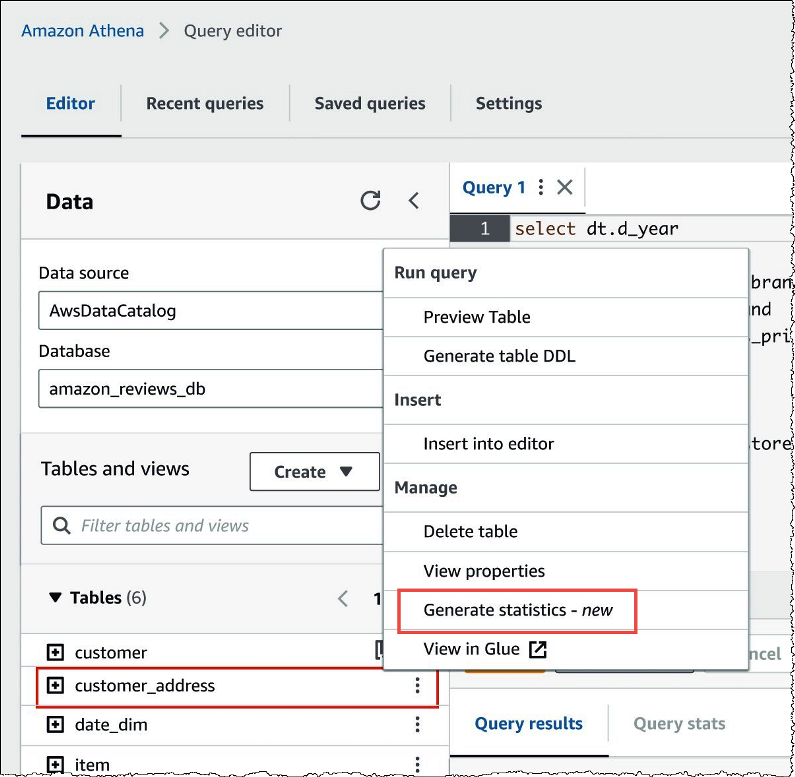
-
在生成统计数据对话框中,选择所有列为表中的所有列生成统计数据,或者选择所选列来选择特定列。所有列为默认设置。
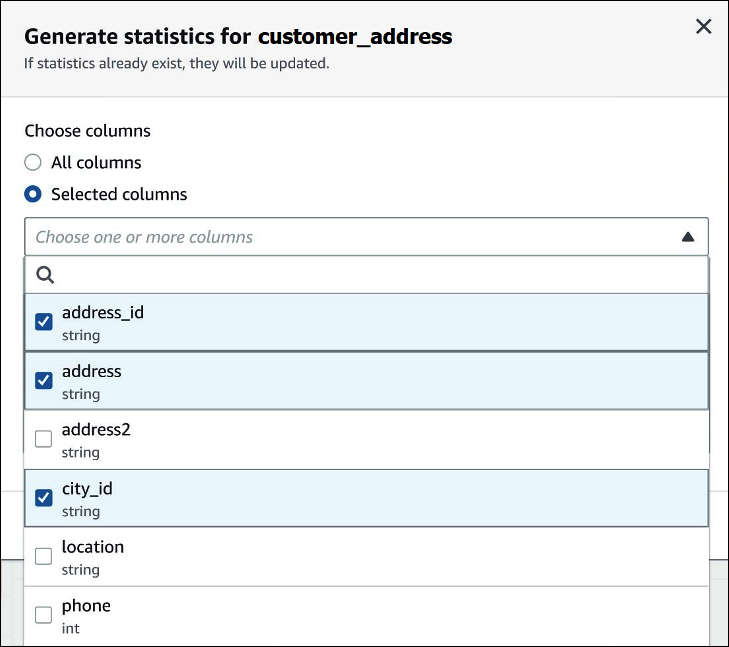
-
对于 AWS Glue 服务角色,创建服务角色或选择现有服务角色来授予 AWS Glue 生成统计数据的权限。对于包含表数据的 Amazon S3 存储桶,AWS Glue 服务角色还需要
S3:GetObject权限。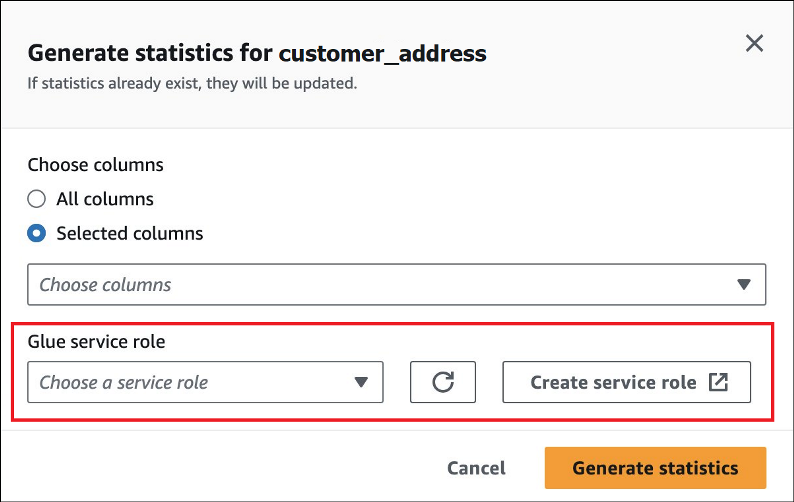
-
选择生成统计数据。为
table_name生成统计数据通知横幅显示任务状态。
-
要在 AWS Glue 控制台中查看详细信息,请选择在 Glue 中查看。
有关在 AWS Glue 控制台中查看统计数据的信息,请参阅《AWS Glue 开发人员指南》中的 Viewing column statistics。
-
生成统计数据后,包含统计数据的表和列在括号中显示统计数据一词,如下图所示。

现在,如果运行查询,Athena 会对生成统计数据的表和列执行基于成本的优化。
其他资源
有关更多信息,请参阅以下资源。
