本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Precission Connect 将大型机数据库复制到 AWS
Lucio Pereira、Sayantan Giri 和 Balaji Mohan,Amazon Web Services
Summary
此模式概述了使用 Precission Connect 近乎实时地将数据从大型机数据库复制到 Amazon 数据存储的步骤。它通过 Amazon Managed Streaming for Apache Kafka (Amazon MSK) 和云中的自定义数据库连接器实现了基于事件的架构,以提高可扩展性、弹性和性能。
Precisely Connect 是一种复制工具,可从遗留大型机系统捕获数据并将其集成到云环境中。通过使用具有低延迟和高吞吐量的异构数据管道的近乎实时的消息流,通过变更数据捕获 (CDC) 将数据从大型机复制到 AWS。
该模式还涵盖了具有多区域数据复制和失效转移路由功能的弹性数据管道的灾难恢复策略。
先决条件和限制
先决条件
要复制到 AWS 云的现有大型机数据库,例如 IBM DB2、IBM 信息管理系统 (IMS) 或虚拟存储访问方法 (VSAM)
从您的企业环境到 AWS 的 AWS Direct Connect
或 AWS Virtual Private Network (AWS VPN ) 具有可由您的旧平台访问的子网的虚拟私有云
架构
源技术堆栈
至少包含以下数据库之一的大型机环境:
IBM IMS 数据库
IBM DB2 数据库
VSAM 文件
目标技术堆栈
Amazon MSK
Amazon Elastic Kubernetes Service (Amazon EKS) 和 Amazon EKS Anywhere
Docker
AWS 关系或 NoSQL 数据库,如下所示:
Amazon DynamoDB
Amazon Relational Database Service (Amazon RDS) for Oracle、Amazon RDS for PostgreSQL 或 Amazon Aurora
ElastiCache 适用于 Redis 的 Amazon
Amazon Keyspaces(Apache Cassandra 兼容)
目标架构
将大型机数据复制至 AWS 数据库
下图说明了将大型机数据复制到 AWS 数据库,例如 DynamoDB、Amazon RDS、Amazon 或 Amazon Keyspac ElastiCache es 的情况。通过在本地大型机环境中使用 Precisely Capture 和 Publisher、在本地分布式环境中使用 Amazon EKS Anywhere 上的 Precisely Dispatcher 以及在 Amazon Web Services Cloud 中使用 Precisely Apply Engine 和数据库连接器,可以近乎实时地进行复制。

图表显示了以下工作流:
Precisely Capture 从 CDC 日志中获取大型机数据,并将数据维护在内部临时存储中。
精确地 Publisher 监听内部数据存储的变化,并通过连接将 CDC 记录发送到 Precist Dispatcher。 TCP/IP
Precisely Dispatcher 从 Publisher 接收 CDC 记录并将其发送到 Amazon MSK。调度程序根据用户配置和多个工作任务创建 Kafka 键以并行推送数据。当记录存储在 Amazon MSK 中后,调度程序会向 Publisher 发送确认信息。
Amazon MSK 在云环境中保存 CDC 记录。主题的分区大小取决于您的事务处理系统 (TPS) 对吞吐量的要求。Kafka 密钥对于进一步的转换和事务排序是必需的。
Precisely Apply Engine 监听来自 Amazon MSK 的 CDC 记录,并根据目标数据库要求转换数据(例如,通过筛选或映射)。您可将自定义逻辑添加至 Precission SQD 脚本。(SQD 是 Precist 的专有语言。) Precisely Apply Engine 将每条 CDC 记录转换为 Apache Avro 或 JSON 格式,并根据您的要求将其分发到不同的主题。
目标 Kafka 主题根据目标数据库保存多个主题中的 CDC 记录,并且 Kafka 根据定义的 Kafka 键促进事务排序。分区键与相应的分区对齐以支持顺序过程。
数据库连接器(自定义 Java 应用程序)监听来自 Amazon MSK 的 CDC 记录并将其存储在目标数据库中。
可根据您的要求选择目标数据库。此模式同时支持 NoSQL 与关系数据库。
灾难恢复
业务连续性是组织成功的关键。Amazon Web Services Cloud 提供高可用性 (HA) 和灾难恢复 (DR) 功能,并支持贵组织的失效转移和备用计划。这种模式遵循 active/passive 灾难恢复策略,为实施符合您的 RTO 和 RPO 要求的灾难恢复策略提供了高级指导。
下图说明了 DR 的工作流。

此图显示以下内容:
如果 AWS 区域 1 发生任何故障,则需要进行半自动失效转移。如果区域 1 出现故障,系统必须启动路由更改,才能将 Precisly Dispatcher 连接至区域 2。
Amazon MSK 在不同区域间通过镜像复制数据,因此,在失效转移期间,区域 2 中的 Amazon MSK 集群必须提升为主要领导者。
Precisely Apply Engine 和数据库连接器是无状态应用程序,可以在任何区域中工作。
数据库同步取决于目标数据库。例如,DynamoDB 可以使用全局表,也可以使用全局数据 ElastiCache 存储。
通过数据库连接器执行低延迟和高吞吐量处理
数据库连接器是此模式中的关键组件。连接器采用基于侦听器的方法从 Amazon MSK 收集数据,并通过任务关键型应用程序(第 0 层和第 1 层)的高吞吐量和低延迟处理将事务发送到数据库。下图阐明了此过程。
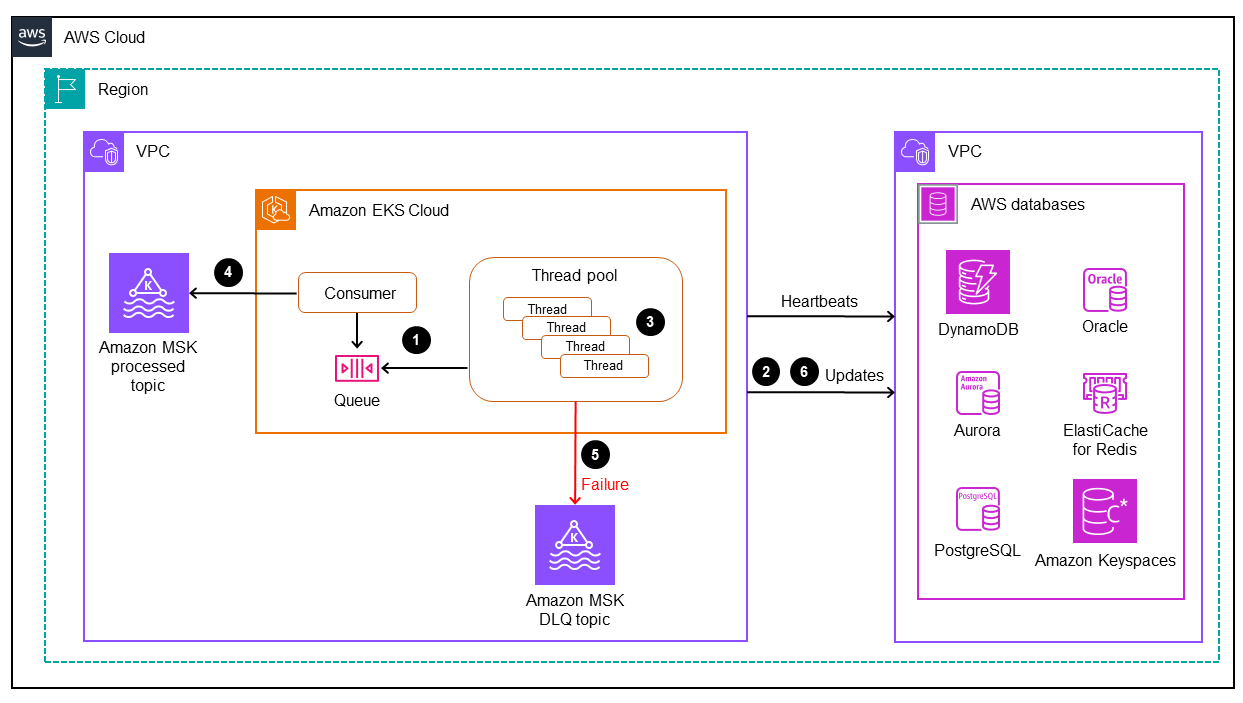
该模式支持通过多线程处理引擎开发具有单线程消耗的定制应用程序。
连接器主线程使用来自 Amazon MSK 的 CDC 记录并将其发送至线程池进行处理。
线程池中的线程处理 CDC 记录并将其发送至目标数据库。
如果所有线程都处于繁忙状态,则线程队列保留 CDC 记录。
主线程等待从线程队列中清除所有记录,并将偏移量提交至 Amazon MSK 中。
子线程处理故障。如果在处理过程中发生故障,则失败的消息将发送到 DLQ(死信队列)主题。
子线程根据大型机时间戳启动条件更新(参见 DynamoDB 文档中的条件表达式),以避免数据库中的任何重复 out-of-order或更新。
有关如何实现具有多线程功能的 Kafka 消费者应用程序的信息,请参阅 Confluent 网站上的博客文章 Apache Kafka 消费者使用多线程消息消费
工具
Amazon Web Services
Amazon Managed Streaming for Apache Kafka (Amazon MSK) 是一项完全托管式服务,可帮助您构建并运行使用 Apache Kafka 来处理流数据的应用程序。
Amazon Elastic Kubernetes Service (Amazon EKS) 可帮助您在 AWS 上运行 Kubernetes,而无需安装或维护您自己的 Kubernetes 控制面板或节点。
Amazon EKS Anywhere
帮助您部署、使用和管理在您自己的数据中心运行的 Kubernetes 集群。 Amazon DynamoDB 是一项完全托管式 NoSQL 数据库服务,可提供快速、可预测、可扩展的性能。
Amazon Relational Database Service (Amazon RDS) 可帮助您在 Amazon Web Services Cloud 中设置、操作和扩展关系数据库。
Amazon ElastiCache 可帮助您在 AWS 云中设置、管理和扩展分布式内存缓存环境。
Amazon Keyspaces(Apache Cassandra 兼容)是一项托管数据库服务,可帮助您在 Amazon Web Services Cloud 中迁移、运行和扩展 Cassandra 工作负载。
其他工具
Precission Connect
将来自传统大型机系统(例如 VSAM 数据集或 IBM 大型机数据库)的数据集成到下一代云和数据平台中。
最佳实践
找到 Kafka 分区和多线程连接器的最佳组合,从而平衡最佳性能和成本。由于 MIPS(每秒百万条指令)消耗量更高,多个 Precist Capture 和 Dispatcher 实例可能会增加成本。
避免向数据库连接器添加数据操作和转换逻辑。为此,请使用 Precisely Apply Engine,它提供以微秒为单位的处理时间。
在数据库连接器中创建对数据库的定期请求或运行状况检查调用(检测信号),以频繁预热连接并减少延迟。
实现线程池验证逻辑,以了解线程队列中的待处理任务,并在下一次 Kafka 轮询之前等待所有线程完成。这有助于避免节点、容器或进程崩溃时数据丢失。
通过运行状况端点公开延迟指标,通过控制面板和跟踪机制增强可观测性。
操作说明
| Task | 说明 | 所需技能 |
|---|---|---|
设置大型机过程(批处理或在线实用程序),以从大型机数据库启动 CDC 过程。 |
| 大型机工程师 |
激活大型机数据库日志流。 |
| 大型机数据库专家 |
使用捕获组件捕获 CDC 记录。 |
| 大型机工程师、Precisely Connect SME |
配置 Publisher 组件以侦听 Capture 组件。 |
| 大型机工程师、Precisely Connect SME |
在本地分布式环境中预配 Amazon EKS Anywhere。 |
| DevOps 工程师 |
在分布式环境中部署和配置 Dispatcher 组件,以便在 Amazon Web Services Cloud 中发布主题。 |
| DevOps 工程师,Precission Conn |
| Task | 说明 | 所需技能 |
|---|---|---|
在指定的 AWS 区域配置 Amazon EKS 集群。 |
| DevOps 工程师、网络管理员 |
配置 MSK 集群并配置适用 Kafka 主题。 |
| DevOps 工程师、网络管理员 |
配置 Apply Engine 组件,以侦听复制的 Kafka 主题。 |
| Precisely Connect SME |
在 Amazon Web Services Cloud 中配置 DB 实例。 |
| 数据工程师、 DevOps 工程师 |
配置和部署数据库连接器以侦听 Apply Engine 发布的主题。 |
| 应用程序开发人员、云架构师、数据工程师 |
| Task | 说明 | 所需技能 |
|---|---|---|
为您的业务应用程序定义灾难恢复目标。 |
| 云架构师、数据工程师、应用程序所有者 |
根据定义 RTO/RPO 设计灾难恢复策略。 |
| 云架构师、数据工程师 |
配置灾难恢复集群和配置。 |
| DevOps 工程师、网络管理员、云架构师 |
测试 CDC 管道灾难恢复。 |
| 应用程序所有者、数据工程师、云架构师 |
相关资源
AWS 资源
Precisely Connect 资源
Confluent 资源
